Vgg16网络模型一些注意和理解(可能学习的不是非常的扎实,如果有什么问题向往指出)
- 为什么使用3个3*3的卷积核代替一个7*7的卷积核?
保证在有相同感知野的条件下,提升了网络的深度,在一定程度上提升了网络的效果,减少了权重参数的数量。
- 为什么使用1*1的卷积核?
1.为了使我们的网络更深。
2.降低维度
3.为了增加更多的非线性变换
1*1的卷积核可以结合max pooling
1*1卷积核可以设置大的步长,这样可以在丢失非常少的信息下降低数据的维度
取代fc层
Vgg整个的网络模型:
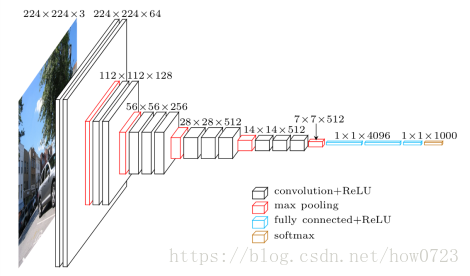
比如第一层输出为什么会得到我们的224*224*64这样的卷积输出:
就拿第一个卷积的过程来说:
我们选用的卷积核是3*3*3这样一个滤波器,然后为了使用了64个卷积核横放在一起就是我们的这样的64个卷积核((3*3*3)*64),和我们的输入图像分别卷积,然后得到相应的第一个卷积层的输出,这样就得到了我们想要的224*224*64这样一个卷积层的输出。我之前一直很不明白为什么224*224*3的输入图像经过卷积核卷积为什么会得到224*224*64,就算是选择3*3*3的滤波器也不会得到这样的输出结果。
对于第一层卷积输出到第二层卷积输出是有使用的卷积核可以看成(3*3*64)*64这样有64个分别和前一层卷积,也是得到224*224*64的第二层输出。
到了第三个卷积层输出到第四个卷积层输出我们可以看到中间有一个池化层,一开始我以为是错的,池化层会减小上一层输入的长和宽但是不会增加他的通道数,所以我们看到上面第一个红色的池化层输出是112*112*64。
实在不理解可以看看卷积的这样一个详细的过程。


这是一个输入图像和一个卷积核卷积过程的示意图 。
上面就是一个输入图像和一个
其中的几个注意点:
- 卷积层的作用:主要是用来进行特征的提取。
2.1全连接层的每一个结点都与上一层所有的结点相连接,用来把前边提取到的特征综合起来。由于使用全连接的特性,全连接层的参数也是最多的。第一个全连接层有4096个节点,上一层POOL2时7*7*512=25088个节点,则该层传输需要25088*4096个权值得到上图1*4096的输出结果,需要耗损很大的内存。
2.2但是对于vgg16网络模型图我们很难理解为什么在7*7*512输出的结果是1*1*4096主要是我们在训练的时候是使用的是全连接网络,但是在我们测试图片的时候,使用的却是全连接转换成卷积层使用的7*7的卷积核,这就是为什么我们的输出结果变成了1*1*4096,然后在使用1*1的卷积核这样就得到我们的最终的输出结果。
至于为什么使用卷积来代替全连接,主要是因为:
- 提升了计算的效率,并且减少了内存的消耗
- 不会限制我们的的输入图片的大小。
3.为什么我们训练的时候有三个全连接层,我的初步的了解是:
相当于我们的泰勒公式使用多项式去拟合我们的光画曲线,我们这里的一个全连接层中的一层相当于一个多项式,我们使用许多的神经元去拟合这里的数据分布,如果只有一层那就很难解决非线性的问题了。
4. CNN网络中前几层的卷积层参数量占比小,计算量占比大;而后面的全连接层正好相反,大部分CNN网络都具有这个特点。因此我们在进行计算加速优化时,重点放在卷积层;进行参数优化、权值裁剪时,重点放在全连接层。