1.The difference of the reinforcement learning:(区别于传统的监督/非监督学习)
-
no supervisor ,only a reward signal(小孩试错的过程)
-
feedback is delayed,not instantaneous(错误的决定不会即时显现灾难,要经过几个阶段的验证,反馈被延迟)
-
time really matters(sequential连续的,not i.i.d data)(独立同分布已经被破坏掉了,agent根据环境影响来采取措施应对环境的变化)
2.增强学习可以用在各个领域利用奖励机制便于优化决策,需要不同数据集的集合。例如在游戏中通过不断地学习试错找到完美的策略。
3.Rewards
-
是一个标量的反馈信号,用随机变量
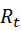 表示。
表示。 -
转换后的标量奖励信号要足够多,并且有一定的优先级(有衡量尺度)。
-
每一步决策都要找到对应的
 ,时每一步的reward相加最后实现最大化
,时每一步的reward相加最后实现最大化
4.Goal:select actions to maximise total future reward
建立统一的框架,使用机器学习的方法,使用相同的形式应对不同的连续决策问题,提前考虑未来,最大化未来的奖励
-
Actions may have long term consequences
-
Reward may be dalayed
-
It may be better to sacrifice(牺牲) immediate reward to gain more long-term reward
需要提前考虑未来,结果是长期性的。可能不是当下想要的结果,但是经过几步以后,就变成我们想要的结果了,这就意味着现在需要放弃一些好的奖励,而在不久的未来则会得到更高的奖励,所以不要太贪心,需要目光长远,例如长期投资问题或者飞机飞行油耗问题
5.数据流传播方向:

agent负责take action,agent采取行动的每一步都是基于它当前所获得的信息。agent有两个输入,一个是观察得到的外部信息,另外一个就是获得的奖励,共同决定了下一步的措施。我们的目标就是找到位于大脑中的算法。

在另一个方面,我们有一个外部环境。随着时间不断循环agent与environment之间的交互,agent每采取一步行动,agent就会得到来自外部世界观测的输入;agent采取行动之后,新的环境就产生了,产生对应的obsercation和reward,产生了下一个外部信息以及对应的分数。我们不能控制环境,只能唯一地通过agent采取行动这个渠道来影响环境。
-
增强学习是基于观察,奖励,行动措施的时间序列。
-
这个时间序列代表着agent的经验,这个经验就是用于增强学习的数据。
-
因此增强学习的问题就是聚焦这个数据来源,即这个数据流。
6.History:The history is the sequence of observations,actions,rewards。
![]()
-
What happens next depends on the history:
-
The agent selects actions depends on the history.(创建映射)
-
The environment selects observations/rewards(环境根据history发生变化产生rewards)
-
但是history通常很巨大
7.State 对history简要的总结,用state代替history
-
State is the information used to determine what happens next.
-
State is a function of the history.

-
state分为agent state和environment state
8.An information state(Markov state) contains all useful information from history.
Markov链 (Markov性质)
A state ![]() is Markov if and only if
is Markov if and only if ![]()
下一时刻的状态与原来的state无关,仅和当下有关
![]()
-
Once the state is known,the history may be thrown away.
-
The state is a sufficient statistic of the future.
-
The environment stste
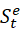 is Markov.
is Markov. -
The history
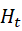 is Markov(定义,可以存储整个的history)
is Markov(定义,可以存储整个的history)
9.Full observability environment (全观察环境)(课程大部分涉及到此种环境)
-
agent directly observes environment state(数字所表示的状态)
-
 agent state和environment state相同
agent state和environment state相同 -
This is a Markov decision process(MDP)
10.Partial observability:agent indirectly observes environment
-
eg: robot/poker playing agent
-
此时agent state和environment state不相同
-
This is a partially observable Markov decision process(POMDP)
11.创建代理 ![]()
-
记住每一次的观测,动作,奖励 complete history:
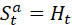
-
Beliefs of environment state:
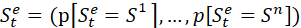 (贝叶斯问题)
(贝叶斯问题) -
neural network:
 线性组合方式将最近agent的状态与最近的观测结合起来,就能得到最新的状态(循环神经网络)
线性组合方式将最近agent的状态与最近的观测结合起来,就能得到最新的状态(循环神经网络)
12.An RL agent may include one or more of these components:
-
policy:agent's behaviour function(行为函数,状态到行动的映射)
-
value function:how good is each state and/or action.(预期奖励)
-
model:agent's representation of the environment(判断环境的变化)
13.Policy
-
A policy is the agent's behaviour
-
It is a map from statre to action.
-
Deterministic policy:
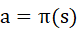
-
Stochastic(随机)policy:
 随即方式状态映射到状态
随即方式状态映射到状态
14.Value:未来奖励的预测
-
Value function is a prediction of future reward.
-
Used to evaluate the goodness and badnenss of states.
-
And therefore to select between actions.
-
对于一种policy
 ,其中
,其中 是下一阶段的奖励,其中增加一个小于1的权重值,这表明我们更关注当前的奖励,即
是下一阶段的奖励,其中增加一个小于1的权重值,这表明我们更关注当前的奖励,即 ,作为折现值。
,作为折现值。
15.Model:并不是环境本身,不是必须要求的。
-
A model predicts what the environment will do next.
-
transition model:P predicts the next state(dynamics)
-
reward model:R predicts the next (immediate) reward.
-
状态转换模型:
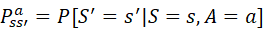 是根据当前的状态和动作,环境所处的下一个状态的概率。
是根据当前的状态和动作,环境所处的下一个状态的概率。
![]() 预期奖励是基于先前的以及当下的状态的。
预期奖励是基于先前的以及当下的状态的。
16.对增强学习分类根据agent是否包含这三个关键元素:
-
Value Based:No Policy(Implicit不清楚的),即不需要明确的Policy;Value Function
-
Policy Based:Policy;No Value Function
-
Actor Critic:Policy;Value Function
17.根据model分类:
-
Model Free:Policy and/or Value Function;No Model
-
Model Based:Policy and/or Value FUnction;Model