多线程(threading)
线程是调度的最小单元. 一个进程可以包含多个线程.
线程是通过 Thread类进行实例化.
举个例子说明多线程的好处:
1.我们在爬虫的时候,输入URL后需要做两件事 第一要获取列表,第二要获取详情
2.如果是多线程直接 第一,第二一起执行,第一个操作在等待的时候会把GIL交给第二个操作,
这样不要等待返回,就可以执行第二个操作,大大节省了时间,这样就实现了并发.
如果不是多线程会先执行第一个操作等待返回结果再执行第二个操作.
接下来用代码进行演示下效果:
import time,threading #导入线程 moudle
def get_details_html(url): #运行的函数1
print("html start")
time.sleep(5) #为了模拟返回的时间
print("html end")
def get_details_url(url): #运行的函数 2
print("url start")
time.sleep(5) #为了模拟返回的时间
print("url end")
if __name__=="__main__":
thread1=threading.Thread(target=get_details_html,args=("",))
#创建线程1
thread2=threading.Thread(target=get_details_url,args=("",))
# 创建线程2
start_time=time.time()
thread1.start() #开启线程1
thread2.start() #开启线程2
run_time=time.time()-start_time #记录执行时间
print("runtime:{}".format(run_time)) #打印执行时间
打印结果如下:
html start
url start
runtime:0.0
html end
url end
从打印结果了看,印证我们的说法,在等待返回会把GIL 锁释放出来.
为什么 runtime 为0 呢? 按照我们的理解并发结果应该为3 .
下边我们来解释下 :
这里面隐藏了一个知识点就是我们都忽略了主线程.
实际 一共有三个线程 线程1,线程2 和主线程 main. 我们来debug 看下 :
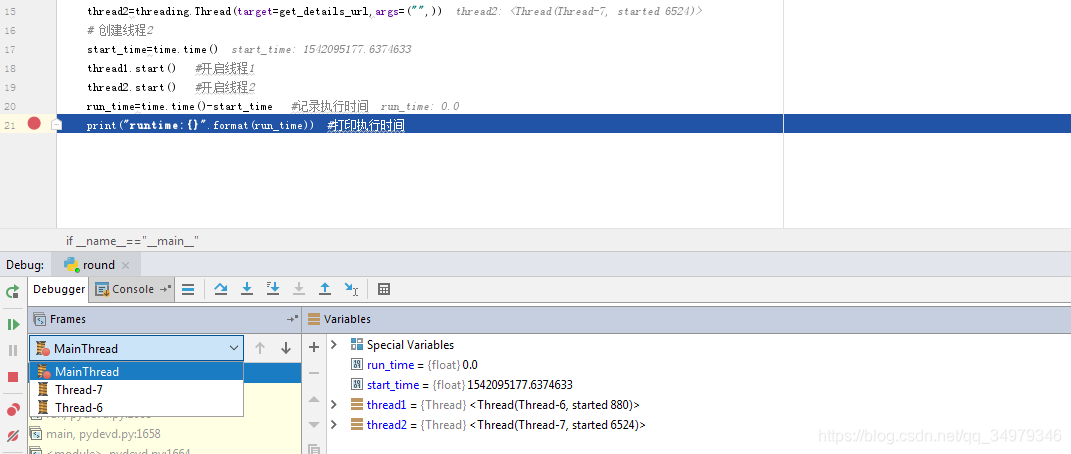
三个线程之间是并发的,所以main 线程不会等待其他两个直接执行了,所以结果为0 .
虽然它们三个都是并发的,各自执行但是 main线程执行完了并没有退出 ,一旦它断掉,其他
两个线程也会挂掉,main线程一挂掉,进程就挂.
setDaemaon 守护线程
1.演示主线程退出,子线程挂掉的情况 会用到一个知识_setDaemon 代码演示如下:
import time,threading #导入线程 moudle
def get_details_html(url): #运行的函数1
print("html start")
time.sleep(5) #为了模拟返回的时间
print("html end")
def get_details_url(url): #运行的函数 2
print("url start")
time.sleep(5) #为了模拟返回的时间
print("url end")
if __name__=="__main__":
thread1=threading.Thread(target=get_details_html,args=("",))
#创建线程1
thread2=threading.Thread(target=get_details_url,args=("",))
# 创建线程2
thread1.setDaemon(True) # 当主线程退出,子线程强制退出
thread2.setDaemon(True) # 当主线程退出,子线程强制退出
start_time=time.time()
thread1.start() #开启线程1
thread2.start() #开启线程2
run_time=time.time()-start_time #记录执行时间
print("runtime:{}".format(run_time)) #打印执行时间
打印结果:
html start
url start
runtime:0.0
当线程调用的时候,线程就变成了守护线程.
假如线程1 变成守护线程,线程2不是,线程2仍然会继续执行完.
join()函数控制多线程的执行顺序
假如我们都在每个线程加上join,看下执行效果:
import time,threading #导入线程 moudle
def get_details_html(url): #运行的函数1
print("html start")
time.sleep(5) #为了模拟返回的时间
print("html end")
def get_details_url(url): #运行的函数 2
print("url start")
time.sleep(5) #为了模拟返回的时间
print("url end")
if __name__=="__main__":
thread1=threading.Thread(target=get_details_html,args=("",))
#创建线程1
thread2=threading.Thread(target=get_details_url,args=("",))
# 创建线程2
thread1.setDaemon(True) # 当主线程退出,子线程强制退出
thread2.setDaemon(True) # 当主线程退出,子线程强制退出
start_time=time.time()
thread1.start() #开启线程1
thread2.start() #开启线程2
thread1.join() #先执行
thread2.join() #先执行
run_time=time.time()-start_time #记录执行时间
print("runtime:{}".format(run_time)) #打印执行时间
打印结果:
html start
url start
url end
html end
runtime:5.000763416290283
说明两点:
1.主线程在最后才执行(runtime)
2.执行时间并不是 5+5 , 说明实现了并发操作.
通过继承Thread 类来实现多线程
threading 适合代码量比较小,场景不复杂的情况下. 如果代码量大直接用继承类比较简洁 .
我们把上边的代码用继承Thread类进行改变,如下:
import time,threading #导入线程 moudle
class Get_details_html(threading.Thread): #继承Thread类
def __init__(self): #重写父类init 方法,在这里可以加入线程一些属性 例如name
super().__init__()
def run(self): #重写run方法, 并把线程的执行过程写到这里
print("html start")
time.sleep(5) # 为了模拟返回的时间
print("html end")
class Get_details_url(threading.Thread):
def __init__(self):
super().__init__()
def run(self):
print("url start")
time.sleep(5) # 为了模拟返回的时间
print("url end")
if __name__=="__main__":
thread1=Get_details_html() #要取到一个线程对象,才能执行类的方法.
#创建线程1
thread2=Get_details_url()
# 创建线程2
start_time=time.time()
thread1.start() #开启线程1
thread2.start() #开启线程2
thread1.join()
thread2.join()
run_time=time.time()-start_time #记录执行时间
print("runtime:{}".format(run_time)) #打印执行时间
打印结果:
html start
url start
url end
html end
runtime:5.001164197921753
我们发现执行结果一样, 利用继承类我们可以实现复杂的操作,大部分都是用这个方式.
我们已经完成了多线程实现的两种方式,下一节我们将实现线程之间如何通信.
谢谢浏览,有好的建议请留言 谢谢