本文为《数据挖掘:概念与技术》中“数据仓库与联机分析处理”的阅读笔记。
数据仓库与联机分析处理
ETL:用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。
- 数据仓库提供联机分析处理(OLAP)工具,用于各种粒度的多维数据的交互分析,有利于有效的数据泛化和数据挖掘。
- 数据立方体,是一种用于数据和OLAP以及OLAP操作(如上卷、下钻、切片和切块)的多维数据模型。
数据仓库:基本概念
什么是数据仓库
数据仓库是一个面向主题的、集成的、时变的、非易失的数据集合,支持管理者的决策过程。
- 面向主题的:数据仓库关注决策者的数据建模和分析,而不是单位的日志操作和事务处理。数据仓库通常排除对于决策无用的数据,提供特定主题的简明视图。
- 集成的:通常构造数据仓库是将多个异构数据源,如关系数据库、一般文件和联机事务处理记录集成在一起。
- 时变的:数据仓库的关键结构都隐式或显式地包含时间元素。
- 非易失的:数据仓库总是物理地分离存放数据,不需要事务处理、恢复和并发控制机制,通常只需要数据访问操作:数据的初始化装入和数据访问。
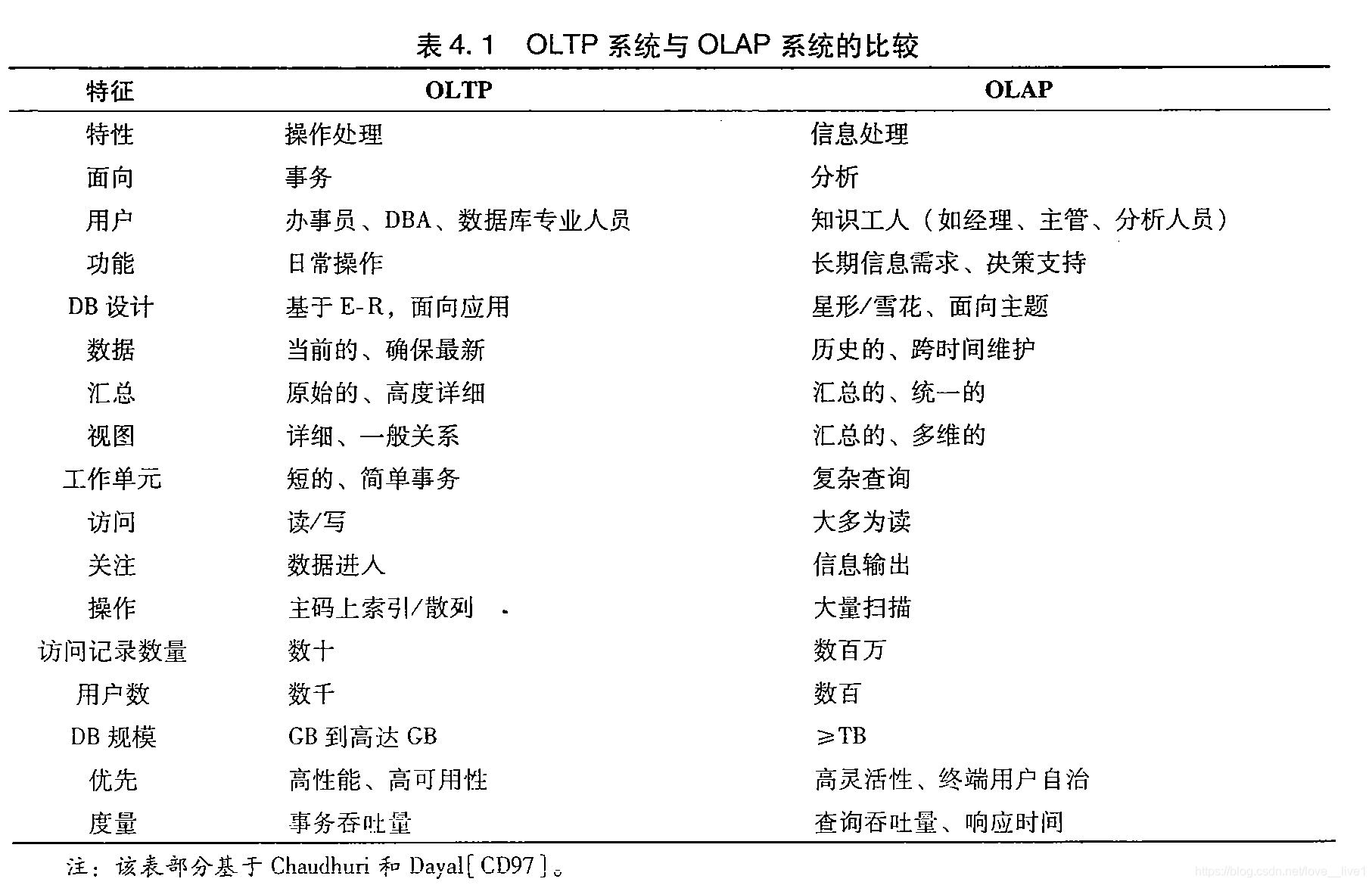
操作数据库系统与数据仓库的区别
- 联机操作数据库系统的主要是执行联机事务和查询处理,称为联机事务处理(Online Transaction Processing,OLTP)系统。
- 数据仓库系统在数据分析和决策方面为用户或“知识工人”提供服务,这种系统可以用不同的格式组织和提供数据,以便满足不同用户的形形色色的需求,称作联机分析处理(Online Analytical Processing,OLAP)系统。
主要区别如下:
- 用户和系统的面向性: OLTP是面向顾客的,用于专业人员的事务和查询处理;OLAP是面向市场的,用于知识工人的数据分析。
- 数据内容:OLTP系统管理当前数据;OLAP系统管理大量历史数据,提供汇总和聚集机制,使数据更容易用于有根据的决策。
- 数据库设计:OLTP系统采用实体-联系(ER)数据模型和面向应用的数据库设计;OLAP系统通常采用星形或雪花模型和面向主题的数据库设计。
- 视图:OLTP系统主要关注一个企业或部门内部的当前数据,而不涉及历史数据或不同单位的数据;OLAP系统还处理来自不同单位的信息,以及由多个数据库集成的信息。由于数据量巨大,OLAP数据存放在多个存储介质上。
- 访问模式:OLTP系统的访问主要由短的原子食物组成,该系统需要并发控制和恢复机制;OLAP系统的访问大部分是 只读操作(存放的是历史数据,不是最新数据),尽管许多情况是复杂的查询。
为什么需要分离的数据仓库
- 操作数据库是为已知的任务和负载设计的,检索特定的记录,优化“定制的”查询。数据仓库的查询通常是复杂的,涉及大量数据在汇总级的计算,可能需要特殊的基于多维视图的数据组织、存取方法和实现方法。
- 操作数据库支持多事务的并发处理,需要并发控制和恢复机制,以确保一致性和事务的鲁棒性。OLAP查询只需要对汇总和聚集数据记录进行只读访问。
- 数据仓库与操作数据库分离是由于这两种系统中的数据的结构、内容和用法都不相同。
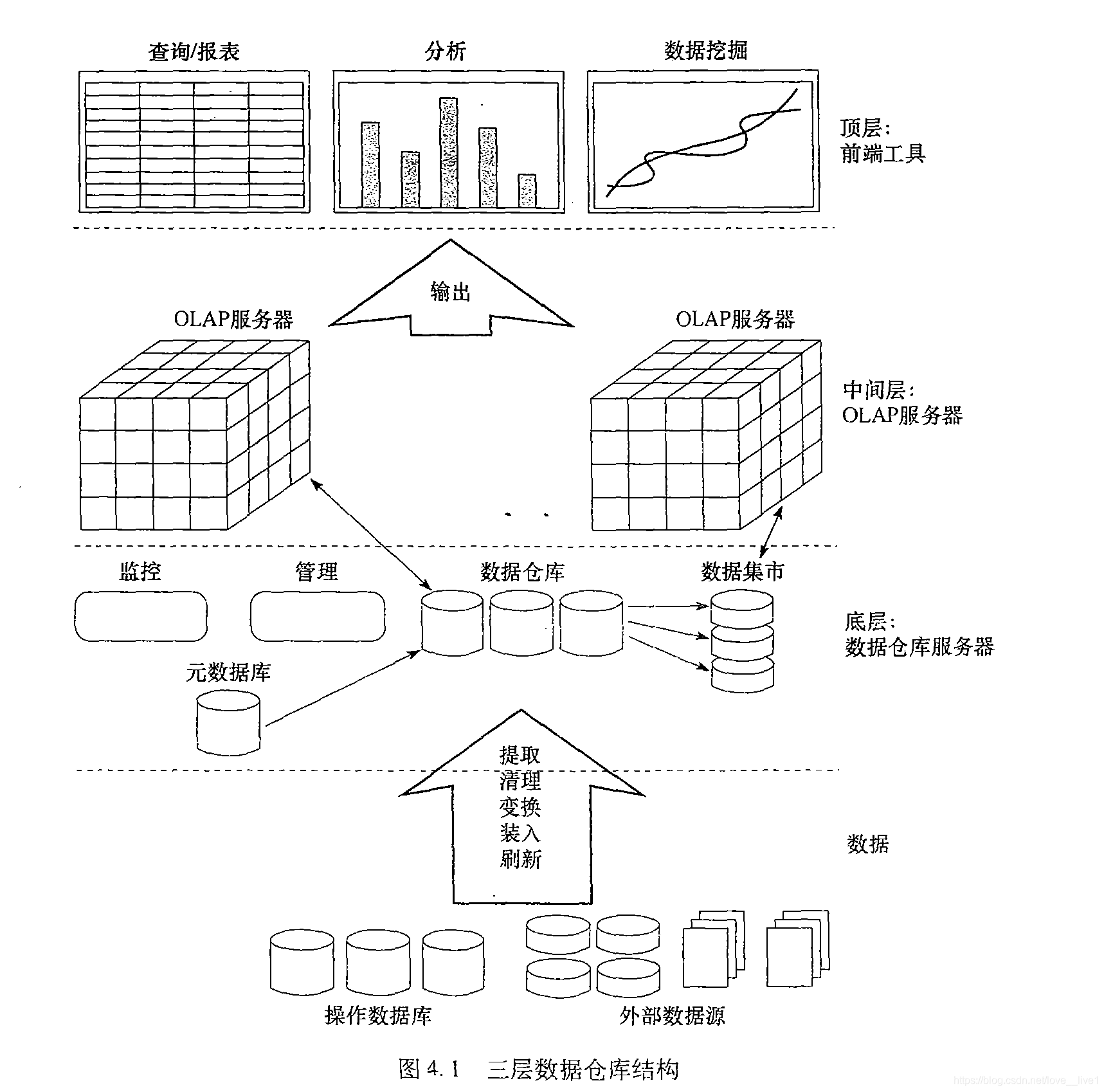
数据仓库:一种多层体系结构
- 底层是仓库数据库服务器。
- 中间层是OLAP服务器
- 顶层是前段客户层
数据仓库模型:企业仓库、数据集市和虚拟仓库
从结构的角度来看,有三种数据仓库模型
- 企业仓库
- 数据集市
- 虚拟仓库
数据提取、变换和装入
- 数据提取:由多个异构的外部数据源收集数据。
- 数据清理:检测数据中的错误,可能时订正它们。
- 数据变换:将数据由遗产或宿主格式转换层数据仓库格式。
- 装入:排序、汇总、合并、计算视图、检查完整性,并建立索引和划分。
- 刷新:传播由数据源到数据仓库的更新。
元数据库
元数据是关于数据的数据。在数据仓库中,元数据是定义仓库对象的数据。元数据库应当包括以下内容:
- 数据仓库结构的描述
- 操作元数据,包括数据血统、数据流通、管理信息
- 用于汇总的算法
- 由操作环境到数据仓库的映射
- 系统性能的数据
- 商务元数据
数据仓库建模:数据立方体与OLAP
数据仓库和OLAP工具基于多维数据模型,这种模型将数据看做数据立方体形式。
数据立方体:一种多维数据模型
- 数据立方体允许以多维对数据建模和观察,它由维和事实定义。
- 维是一个单位想要记录的透视或实体。
- 每个维都可以有一个与之相关联的表,该表称为维表,它进一步描述维。
- 通常,多维数据模型围绕注入销售这样的中心主题组织,主题用事实表表示,事实是数值度量的。
- 存放最低层汇总的方体称作基本方体(base cuboid),0-D方体存放最高层的汇总,称为顶点方体(apex cuboid),顶点方体通常用all标记。
星型、雪花型和事实星座:多维数据模型的模式
最流行的数据仓库的数据模型是多维数据模型,这种模型可以是星型模型、雪花模型和事实星座模式。
星型模式
- 最常见的模式范型,其中数据仓库包括:
- 一个大的中心表(事实表),它包含大批数据并且不含冗余
- 一组小的附属表(维表),每维一个。
- -每维只用一个表表示,而每个表包含一组属性。
- 一个维表中的属性可能形成一个层次(全序)或格(偏序)。

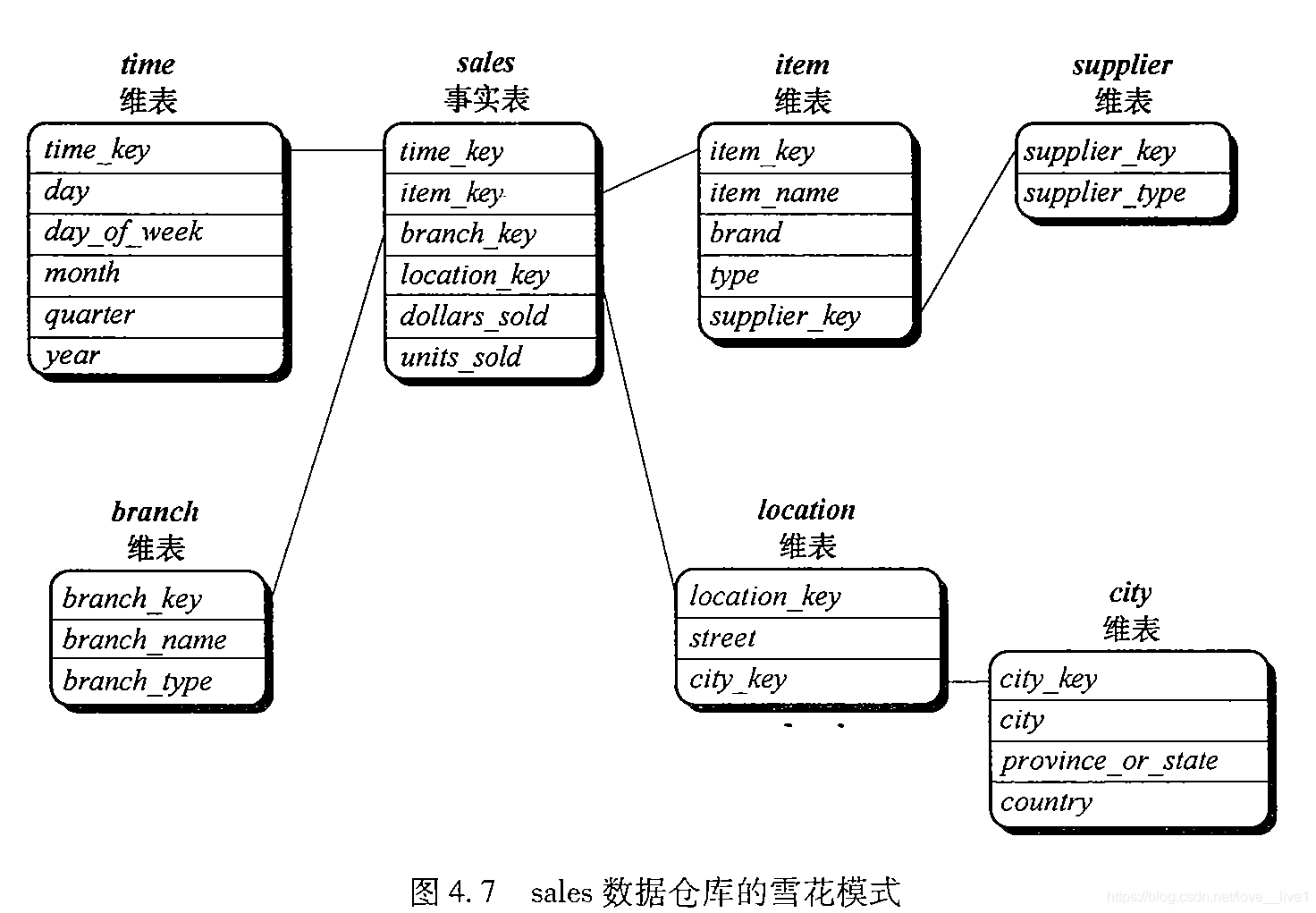
雪花模式 - 雪花模式是星型模式的变种,其中某些维表被规范化,因而把数据进一步分解到附加的表中。
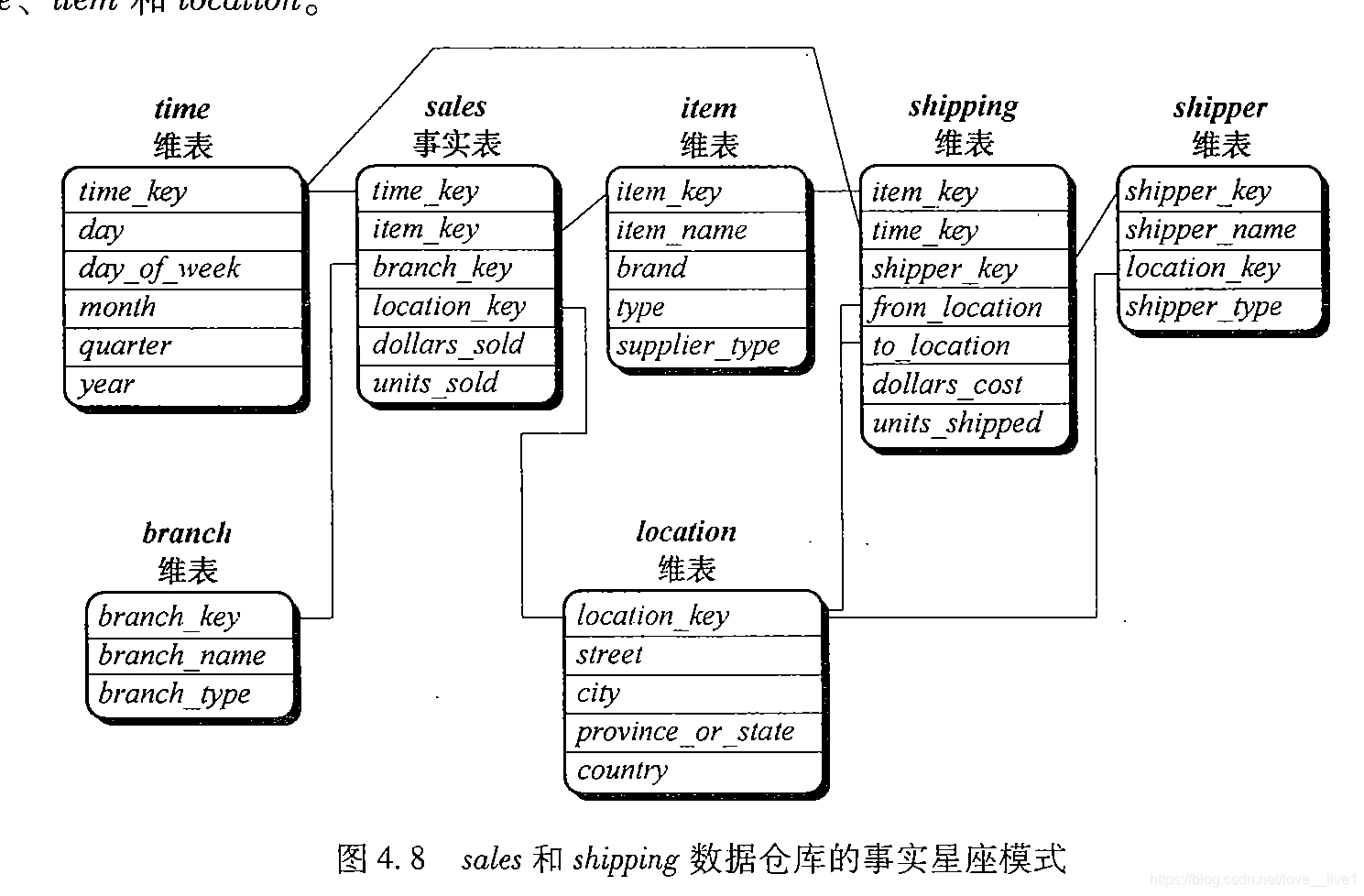
事实星座 - 复杂的应用可能需要多个事实表共享维表,这种模式可以看做星型模式的汇集,因此称作星系模式或事实星座。
- 对于数据仓库,通常使用事实星座模式,因为它能对多个相关的主题建模。数据集市是数据仓库的一个子集,它针对选定的主题,流行采用星型或雪花模式,因为他们都适合对单个主题建模。
维:概念分层的作用
概念分层定义一个映射序列,将低层概念集映射到较高层、更一般的概念。
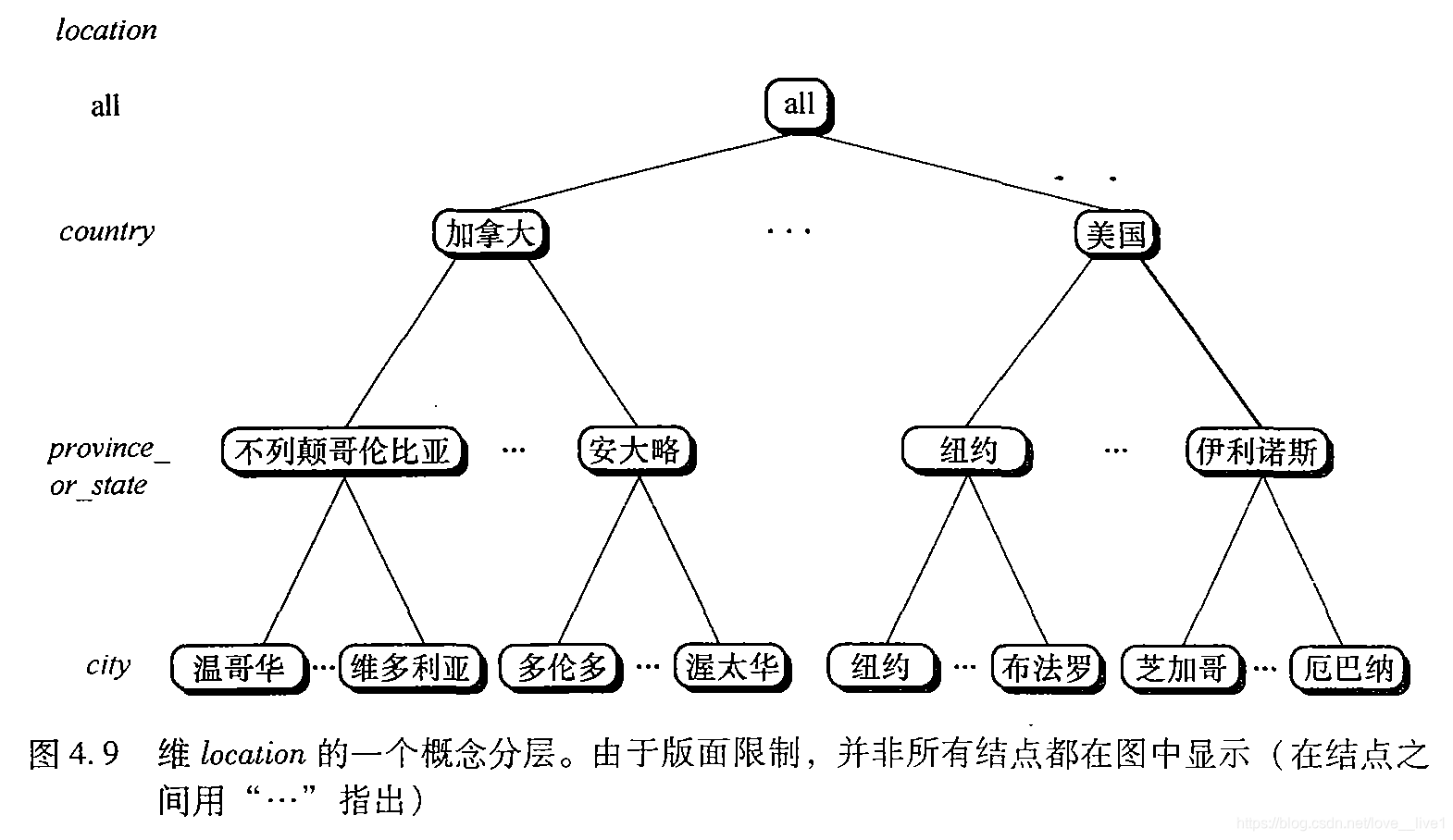
- 形成数据库模式中属性的全序或偏序的概念分层称做模式分层。
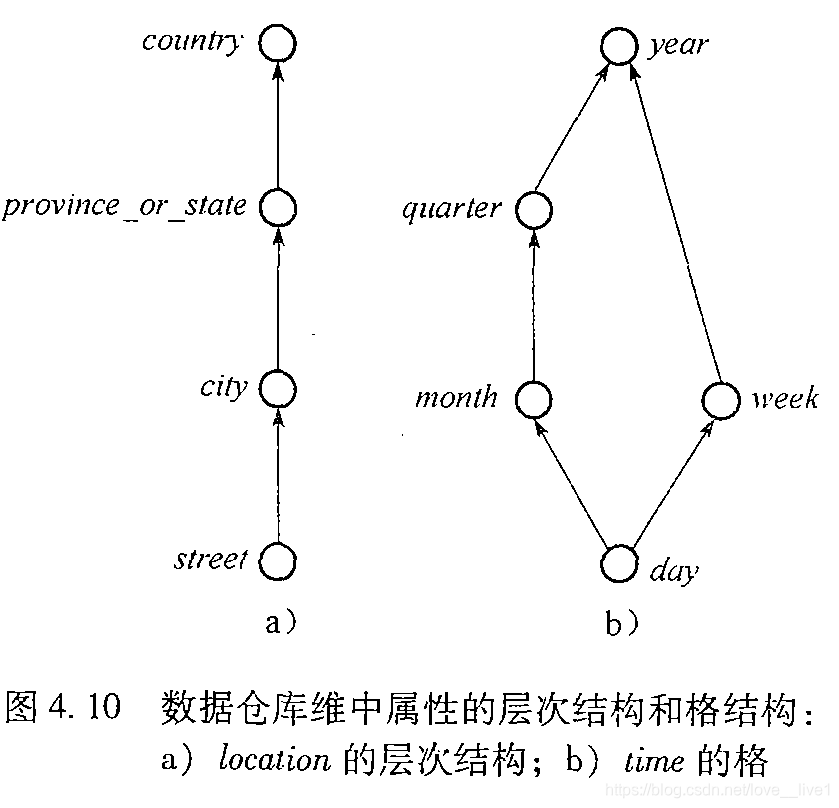
- 数据挖掘系统应当为用户提供灵活性,允许用户根据他们的特殊需要裁剪预定义的分层,也可以通过将给定维或属性的值离散化或分组来定义概念分层,产生集合分组分层。
度量的分类和计算
- 数据立方体空间的多维点可以用维-值对的集合来定义。
- 数据立方体度量(measure)是一个数值函数,该函数可以对数据立方体空间的每个点求值。
- 度量根据所用的聚集函数可以分为三类:分布的、代数的和整体的。
- 分布式的:如果将数据划分为n个集合,将函数用于每一部分,得到n个聚集值。如果将函数用于n个聚集值得到的结果与将函数用于整个数据集得到的结果一样,这该函数可以用分布方式计算。
- 代数的:一个聚集函数如果能用一个具有M个参数的代数函数计算,而每个参数都可以用一个分布聚集函数求得,则它是代数的。
- 整体的:一个聚集函数如果描述它的子聚集所需的存储没有一个常数界,则它是整体的。也就是不存在一个具有M个参数的代数函数进行这一计算。
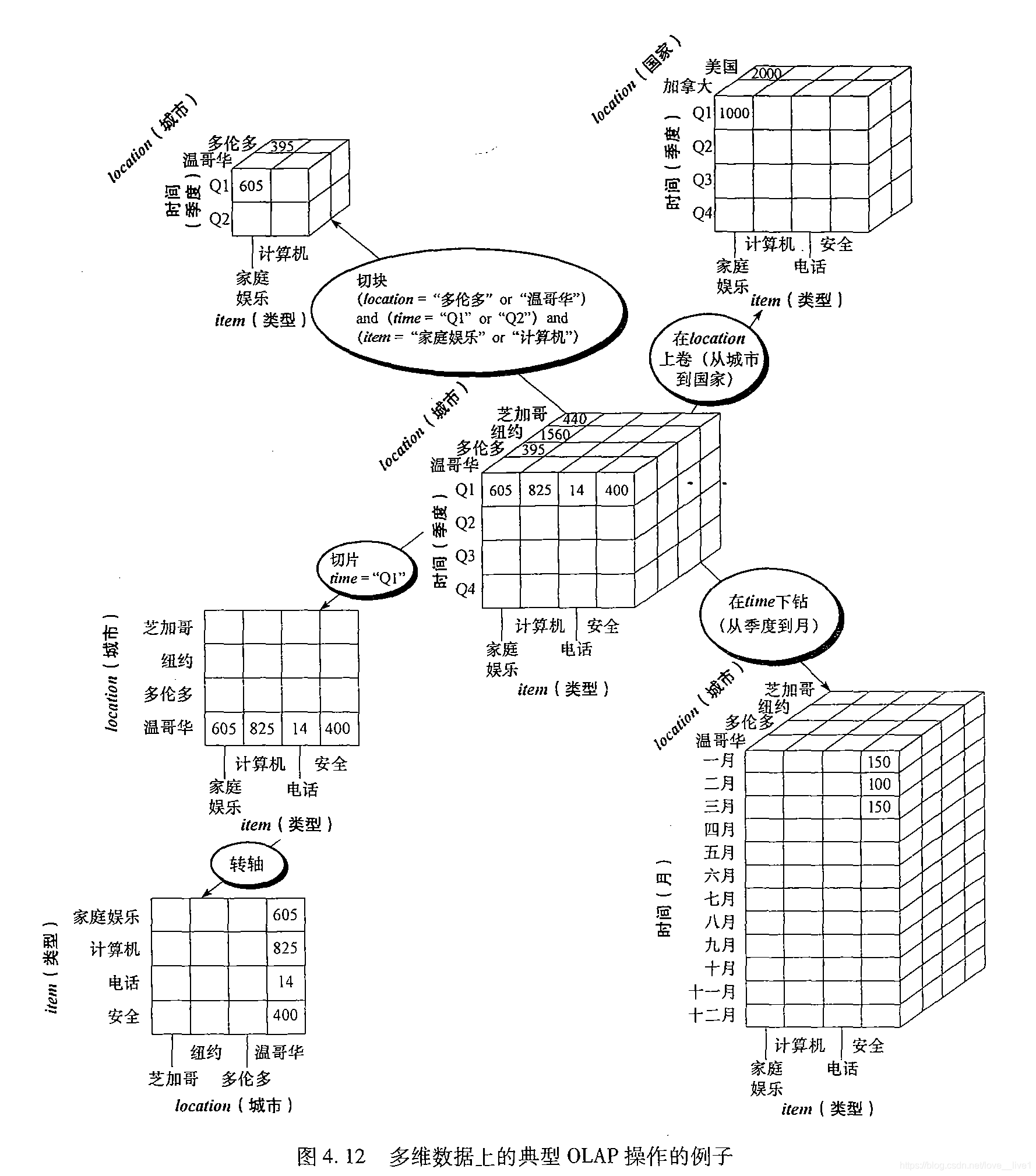
典型的OLAP操作
在"在OLAP中,如何使用概念分层",在多维数据模型中,数据组织在多维空间,每维包含由概念分层定义的多个抽象层。
OLAP操作
-
上卷(roll-up):上卷操作(也称为上钻(drill-up)操作)通过沿一个维的概念分层向上攀升或者通过维归约在数据立方体上进行聚集。
-
下钻(drill-down):下钻是上卷的逆操作,它由不太详细的数据到更详细的数据。下钻可以通过沿维的概念分层向下或引入附加的维来实现。
-
切片和切块:
- 切片(slice)操作在给定的立方体的一个维上进行选择,导致一个子立方体。
- 切块(dice)操作通过在两个或多个维上进行选择,定义子立方体。
-
转轴(pivot):转轴(又称旋转(rotate))是一种目视操作,它转动数据的视角,提供数据的替代表示。
其他OLAP操作: -
钻过(drill-across)执行涉及多个事实表的查询。
-
钻透(drill-through)操作使用关系SQL机制,钻透到数据立方体的底层,到后端关系表。
查询多维数据库的星网查询模型
- 多维数据库查询可以基于星网模型(starnet model)。
- 星网模型由从中心点发出的射线组成,其中每一条射线代表一个维的概念分层。
- 概念分层上的每个“抽象级”称为一个足迹(footprint),代表诸如上卷、下钻等OLAP操作可用的粒度。
- 通过用较高层抽象值替换低层抽象值,概念分层可以用于泛化数据。
- 通过用低层抽象值替换高层抽象值,概念分层也可以特殊化数据。
数据仓库的设计与使用
“如何设计数据仓库?如何使用数据仓库?数据仓库和OLAP与数据挖掘有何联系?”
数据仓库的设计的商务分析框架
关于数据仓库的设计,必须考虑四种不同的视图:
- 自顶向下视图:使得我们可以选择数据仓库所需的相关信息。
- 数据源视图:揭示被操作数据库系统收集、存储和管理的信息。
- 数据仓库视图:包括事实表和维表。
- 商务查询视图:是从最终用户的角度透视数据仓库中的数据。
数据仓库的设计过程
数据仓库可以使用自顶向下方法、自底向上方法、或二者结合的混合方法设计。
- 自顶向下:由总体设计和规划开始。
- 自底向上:以实现和原型开始。
- 混合方法:一个组织既能利用自顶向下方法的规划性和战略性特点,又能保持像自底向上方法一样快速实现和立即应用。
一般而言,数据仓库的设计过程包含以下步骤:
- 选取待建模的商务处理
- 选择商务处理的粒度
- 选取用于每个事实表记录的维
- 选取将安放在每个事实表记录中的度量
数据仓库用于信息处理
有三类数据仓库应用:
- 信息处理:支持查询和基本的统计分析,并使用交叉表、表、图表或图进行报告。
- 分析处理:支持基本的OLAP操作,包括切片与切块、下钻、上卷和转轴。
- 数据挖掘:支持知识发现,包括找出隐藏的模式和关联,构造分析模型,进行分类和预测,并使用可视化工具提供挖掘结果。
数据挖掘的涵盖面要比简单的OLAP操作宽的多,因为它不仅执行数据汇总和比较,而且执行关联、分类、预测、聚类、时间序列分析和其他数据分析任务。
从联机分析处理到多维数据挖掘
- 数据挖掘对关系数据、数据仓库的数据、事务数据、时间序列数据、空间数据、文本数据和一般数据进行挖掘。
- 多维数据挖掘(又称探索式多维数据挖掘、联机分析挖掘或OLAM)把数据挖掘与OLAP集成在一起,在多维数据库中发现知识。
多维数据挖掘特别重要的原因:
- 数据仓库中数据的高质量
- 环绕数据仓库的信息处理基础设施
- 基于OLAP的多维数据探索
- 数据挖掘功能的联机选择
数据仓库的实现
数据立方体的有效计算:概述
compute cube操作与维灾难
- 多维数据分析的核心是有效计算许多维集合上的聚集。用SQL的术语,这些聚集称为分组(group-by)。
- 每个分组可以用一个方体表示,而分组的集合构成数据立方体。
- 顶点方体或0-D方体表示分组为空的情况,基本方体是最低泛化的方体。
- 对于n维立方体,包括基本方体总共有2^n个方体。
- 大多数OLAP产品都借助于多维聚集的预计算。
- 如果数据立方体的所有方体都预先计算,所需的存储空间可能爆炸,特别是当立方体包含许多维时。当许多维都具有相关联的概念分层,具有多层时,存储需求甚至更多,这个问题称作维灾难。
- 预计算并物化由数据立方体可能产生的所有方体是不现实的,更合理的选择是部分物化。
部分物化:方体的选择计算
- 部分物化:有选择的计算整个可能的方体集中一个适当的子集。我们也可以计算立方体的一个子集,它只包含满足用户指定的某种条件(如每个单元的元组计数大于某个阈值)的那些单元,这种情况我们称为子立方体。
- 冰山立方体(iceberg cube):一个数据立方体,它只存放其聚集值大于某个最小支持度阈值的立方体单元。
- 外壳立方体(shell cube):预计算数据立方体的只有少量维(例如3到5维)的方体。
索引OLAP数据:位图索引和连接索引
- 为了提供有效的数据访问,大部分数据仓库系统支持索引结构和物化视图。
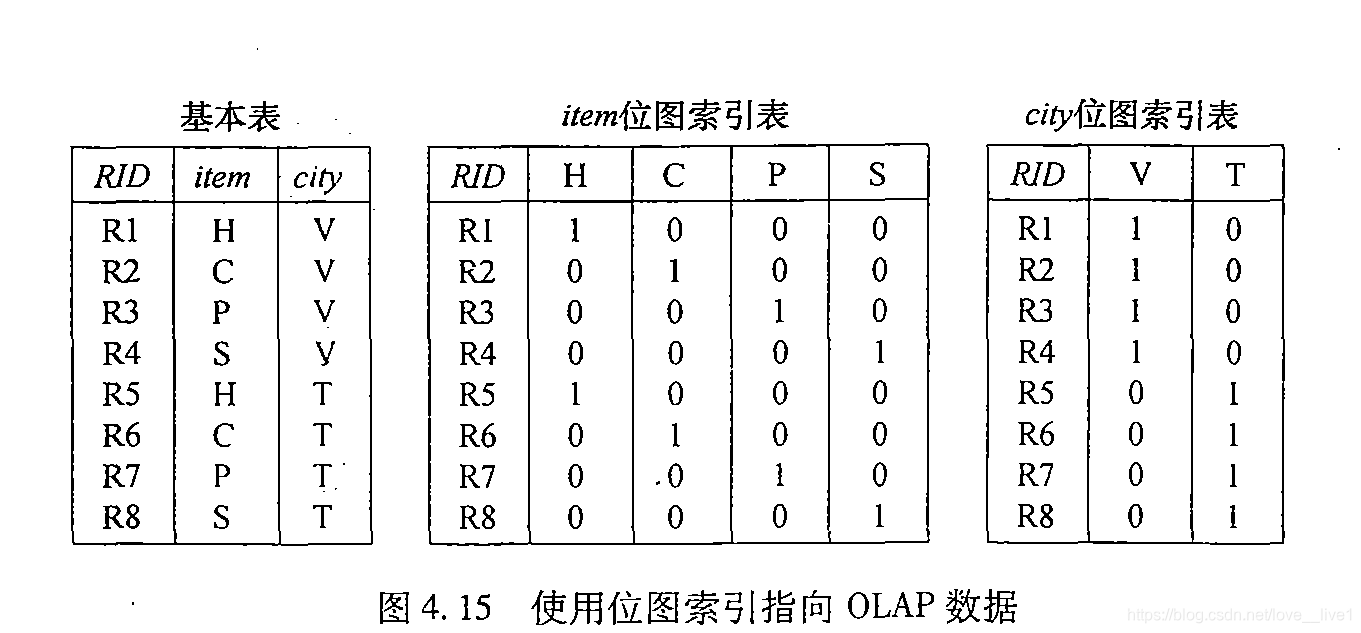
- 位图索引(bitmap indexing):record_ID列表的一种代替表示。如果给定的属性域包含n个值,则位图索引中每项需要n个位(即n维向量)。如果数据表给定行上该属性值为v,则在位图索引的对应行,表示该值的位为1,该行的其他位均为0。
- 对于基数较小的值域特别有用,因为比较、连接和聚集操作都简化为位算术运算,大大减少了处理时间。
- 由于字符串可以用单个二进位表示,位图索引显著降低了空间和IO开销。
- 对于基数较高的值域,可以使用压缩技术。

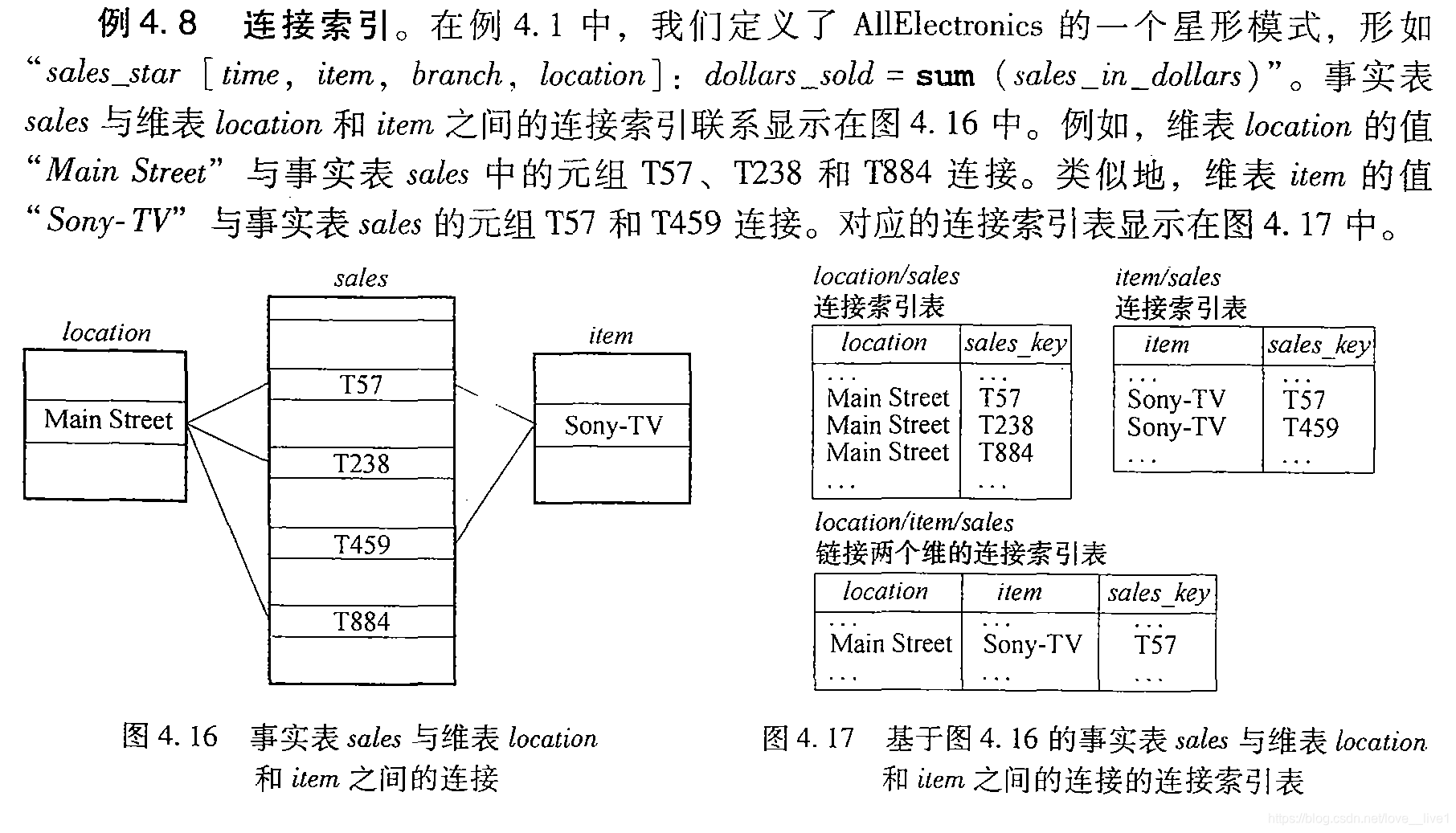
- 连接索引(join indexing):连接索引登记来自关系数据库的两个关系的可连接行。
- 与传统的索引将给定列上的值映射到具有该值的行的列表上不同。
- 连接索引记录能够识别可连接的元组,而不必执行开销很大的连接操作。
- 连接索引可以跨越多维,形成复合连接索引。
- 为进一步加快查询处理,我们可以将连接索引与位图索引集成,形成位图连接索引。
OLAP查询的有效处理
给定物化的视图,查询处理应按如下步骤进行:
- 确定哪些操作应当在可利用的方体上执行。
- 确定相关操作应当使用哪些物化的方体。

OLAP服务器结构:ROLAP、MOLAP、HOLAP的比较
用于OLAP处理的数据仓库服务器的实现包括:
- 关系OLAP(ROLAP)服务器:使用关系的或扩充关系的DBMS存储并管理数据仓库数据,而OLAP中间件支持其余部分。具有比MOLAP更好的可伸缩性。
- 多维OLAP(MOLAP)服务器:通过基于数组的多维存储引擎,将多维视图直接映射到数据立方体数组结构。如果数据集是稀疏的,存储利用率会很低,应当使用稀疏矩阵压缩技术。
- 混合OLAP(HOLAP)服务器:结合ROLAP和MOLAP技术,得益于ROLAP较大的可伸缩性和MOLAP的快速计算。
- 特殊的SQL服务器:一些数据库供应商实现了特殊的SQL服务器,提供高级查询语言和查询处理,在只读环境下,在星型和雪花型模式上支持SQL查询。
数据如何存放在ROLAP结构中:
- 与基本方体相关联的事实表称为基本事实表。
- 基本事实表存放的数据所处的抽象级由给定的数据立方体的模式的连接键指出。
- 聚集数据也能存放在事实表中,这种表称为汇总事实表。
数据泛化:面向属性的归纳
- 数据泛化通过把相对低层的值用较高层概念替换来汇总数据,或通过减少维数,在涉及较少维数的概念空间汇总数据。
- 概念通常指数据的汇集。概念描述产生数据的特征和比较描述。
- 当被描述的概念涉及对象类时,有时也称概念描述为类描述。
- 特征提供给定数据汇集的简洁汇总,而概念或类的比较也称作区分,提供两个或多个数据集合的比较描述。
- 与数据立方体方法相比,数据特征和泛化的面向属性的归纳方法提供了另一种数据泛化方法,用于复杂的数据类型并依赖数据驱动的泛化过程。
- 不局限与关系数据
- 不需要预先计算数据立方体
- 可以把自动分析加入这种归纳过程,自动过滤不相关或不重要的属性。
- 不能有效支持下钻到比被泛化的关系提供的抽象层还深的层。
数据特征的面向属性的归纳
基本思想:
- 首先使用数据库查询收集任务相关的数据(数据聚焦)
- 通过考察任务相关数据中每个属性的不同值的个数进行泛化(通过属性删除或通过属性泛化进行)。
- 聚集通过合并相同的广义元组,并收集它们对应的计数值进行。
属性删除:如果初始工作关系的某个属性有大量不同的值,但是在该属性上没有泛化操作符,或者它的较高层概念用其他属性表示,则应当将该属性从工作关系中删除。
属性泛化:如果初始工作关系的某个属性有大量不同的值,并且该属性上存在泛化操作符的集合,则应当选择一个泛化操作符,并将它用于该属性。
多大才算“属性具有大量不同值”,控制泛化过程的方法:
- 属性泛化阈值控制:对所有的属性设置一个泛化阈值,或对每个属性设置一个阈值。
- 广义关系阈值控制:为广义关系设置一个阈值。
这两种技术可以顺序使用,先用属性泛化阈值控制技术泛化每个属性,然后使用关系阈值控制进一步压缩广义关系。
泛化过程将导致相同元组的分组,这些相同的元组合并成一个,同时累计它们的计数值。
面向属性归纳的有效实现
算法的有效性分析如下:
- 算法的第1步基本上是关系查询,把任务相关的数据收集到工作关系W中。其有效性依赖与所用的查询处理方法。
- 第2步收集初始关系上的统计量。最多需要扫描一次该关系。计算开销依赖与每个属性的不同值的数量,小于初始关系的元组个数|W|。可使用工作关系的一个样本得到统计量。
- 第3步导出主关系P。所有广义元组的时间复杂度为O(N)。

类比较的面向属性归纳
- 类区分或比较挖掘区分目标类和它的对比类的描述。
- 目标类和对比类必须是可比较的,意指它们具有相似的维或属性。
如何进行类比较?
- 数据收集:通过查询处理收集数据库中相关数据,并把它划分成一个目标类和一个或多个对比类。
- 维相关分析:如果有多个维,则应当在这些类上进行维相关分析,仅选择与进一步分析高度相关的维。
- 同步泛化:泛化在目标类进行,产生主目标类关系。对比类的概念泛化到与主目标类关系相同的层次,形成主对比类关系。
- 导出比较的表示:结果类比较描述可以用表、图或规则的形式可视化。