什么是ShedLock
ShedLock是一个在分布式环境中使用的定时任务框架,用于解决在分布式环境中的多个实例的相同定时任务在同一时间点重复执行的问题,解决思路是通过对公用的数据库中的某个表进行记录和加锁,使得同一时间点只有第一个执行定时任务并成功在数据库表中写入相应记录的节点能够成功执行而其他节点直接跳过该任务。当然不只是数据库,目前已经实现的支持数据存储类型除了经典的关系型数据库,还包括MongoDB,Zookeeper,Redis,Hazelcast。
如何使用
ShedLock采用非侵入式编程的思想,通过注解的方式来实现相应的功能。
首先引入Maven依赖
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-spring</artifactId>
<version>1.3.0</version>
</dependency>
然后使用@SchedulerLock来对需要定时执行的任务进行注解。
import net.javacrumbs.shedlock.core.SchedulerLock;
...
@Scheduled(...)
@SchedulerLock(name = "scheduledTaskName")
public void scheduledTask() {
// do something
}
@SchedulerLock注解一共支持五个参数,分别是
- name 用来标注一个定时服务的名字,被用于写入数据库作为区分不同服务的标识,如果有多个同名定时任务则同一时间点只有一个执行成功
- lockAtMostFor 成功执行任务的节点所能拥有独占锁的最长时间,单位是毫秒ms
- lockAtMostForString 成功执行任务的节点所能拥有的独占锁的最长时间的字符串表达,例如“PT14M”表示为14分钟
- lockAtLeastFor 成功执行任务的节点所能拥有独占所的最短时间,单位是毫秒ms
- lockAtLeastForString 成功执行任务的节点所能拥有的独占锁的最短时间的字符串表达,例如“PT14M”表示为14分钟
与Spring进行整合
需要配置两个Bean,一个是lockProvider,一个是scheduler
<!-- lock provider of your choice (jdbc/zookeeper/mongo/whatever) -->
<bean id="lockProvider" class="net.javacrumbs.shedlock.provider.jdbctemplate.JdbcTemplateLockProvider">
<constructor-arg ref="dataSource"/>
</bean>
<bean id="scheduler" class="net.javacrumbs.shedlock.spring.SpringLockableTaskSchedulerFactoryBean">
<constructor-arg>
<task:scheduler id="sch" pool-size="10"/>
</constructor-arg>
<constructor-arg ref="lockProvider"/>
<constructor-arg name="defaultLockAtMostFor">
<bean class="java.time.Duration" factory-method="ofMinutes">
<constructor-arg value="10"/>
</bean>
</constructor-arg>
</bean>
由于ShedLock使用了数据库,所以还需要在数据库中建立一张相应的表以供分布式环境中的各个节点进行加锁解锁。
与其他数据存储的整合详见作者的github
原理分析
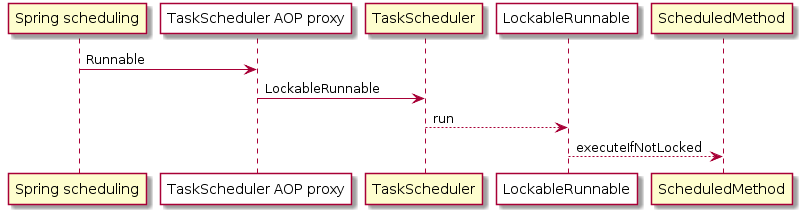
ShedLock使用AOP代理的方式来实现。
可以通过对TaskScheduler类的继承来实现使用者自定义的AOP行为。对于加了@SchedulerLock的方法都会在启动时通过代理的方式加入框架所实现的分布式锁功能。
@Bean
public TaskScheduler taskScheduler() {
return new MySpecialTaskScheduler();
}
对比quartz
相比于quartz,ShedLock只提供了最基本的时间调度格式,而quartz可以提供更加丰富的可供自定义的时间调度方式,但是于quartz相比,ShedLock是轻量级的,通过注解的方式,把所有的一切都交给框架处理,使得代码不会受到影响,更加符合非侵入式编程的思想,使得代码更加简洁明了。