版权声明:Oce2ns的大板 https://blog.csdn.net/weixin_39392653/article/details/84001677
排序是数据结构中的重要一节,也是算法的重要组成部分。主要分为内部排序以及外部排序,今天我们讲内部排序,也就是八大排序。
插入排序
直接插入排序
算法思想
名字已经暴露了他的算法,就是往里面插入数据,就拿我们生活中的例子来说,打扑克牌。我们往手里码牌的时候,是一张一张的码,先码一张,抓手心,不需要修改位置,因为只有一张牌,一定是有序的。再接一张,和手里的牌对比大小,调整位置,选择放在它的左边或者右边。然后接着码,又接到一张牌,拿到先和右边的牌比,比右边还大就放到最右边,如果比右边这张小呢,在和左边这张比。同样,我们这里也是这样的,首先我们默认第一个元素,一定是有序,OK吧。然后第二个,元素比较,大,放到左边,小放到右边。然后第三个元素,直到第N个,比它前一个大,继续往前找位置,直到找到对应位置了,就是有序数列了。(当然每次找位置都是在一个有序的序列中找,所以完全可以用二分查找找位置,数据大的话,二分明显快于我们一张一张比)
算法图解

算法分析
时间复杂度:O(n^2)
空间复杂度:O(1)
稳定性:稳定
算法实现
void InsertionSort(int arr[], int size)
{
int key;//对比牌(要插入的牌)
int i = 0;
int j = 0;
for (i = 1; i < size; i++)//需要排的牌的张数,默认第一张有序,所以数组从1开始
{
key = arr[i];
for (j = i - 1; j >= 0; j--)
{
if (key < arr[j])
{
arr[j + 1] = arr[j];
}
else
{
break;//比它大了,那就是找到正确的位置了,跳出,插牌进去
}
}
arr[j + 1] = key;
}
}
希尔排序
算法思想
名字好听,其实就是直接插入的升级版,主要是插牌的性能差距太大,如果有序,那么插排的事件负责度就是O(N)但是如果排一个逆序他就是O(N^2)。那么引进希尔排序,它就是做一次(多次)预排序让你的排序,尽可能的有序,然后再插排。这样复杂度就明显减小。首先我们将无序数组先进行分组,三个一分,五个一分,十个一分,都行。把小组内成员,进行插排。然后排好的序列其实已经很接近有序了(分的越少越接近,但是分的太少,复杂度也就越大,分组越多,排序次数也就越少。)所以希尔就提出了一个动态的去选择分组的方法。gap=size/3+1(组),例如20个元素,第一次分7组,第二次7/3+1=3组,然后2组,然后1组。
算法图解
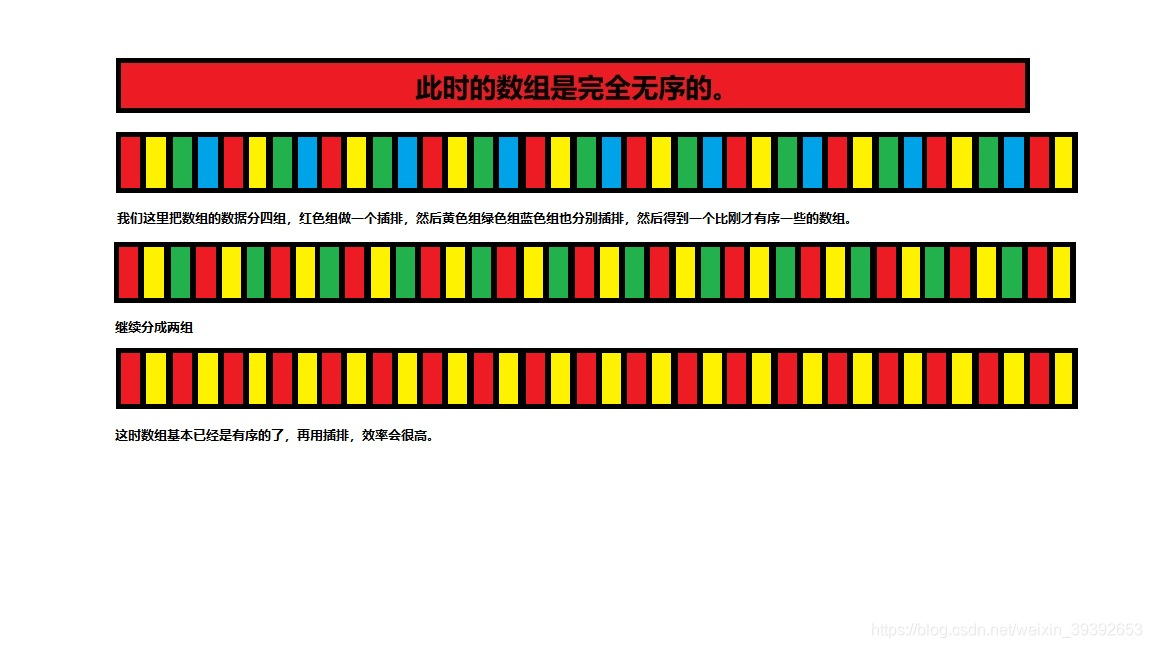
算法分析
时间复杂度:O(n^1.3)
空间复杂度:O(1)
稳定性:不稳定
算法实现
void MultipleInsertionSort(int arr[],int size,int gap)
{
int g = 0;
for (g = 0; g < gap; g++)
{
int key;
int i = 0;
int j = 0;
for (i = g + gap; i < size; i+=gap)
{
key = arr[i];
for (j = i - gap; j >= 0; j-=gap)
{
if (key < arr[j])
{
arr[j + gap] = arr[j];
}
else
{
break;
}
}
arr[j + gap] = key;
}
}
}
void ShellSort(int arr[], int size)
{
int gap = size;
while (gap)
{
gap = gap / 3 + 1;
MultipleInsertionSort(arr, size, gap);
if (gap == 1)
{
break;
}
}
}
选择排序
简单选择排序
算法思想
对数列进行遍历,每一次遍历都找出(选择)其中最大的数,然后把他放到最后面,然后对其他的数继续遍历。进行到最后一次,也就是只有一个元素了,没有遍历了,一个元素直接有序。整个数组就有序了。这是一个基本排序,直接上代码了。(我是按一头找,找最大,也可以双头找,找最大最小,速度快一倍)
算法图解
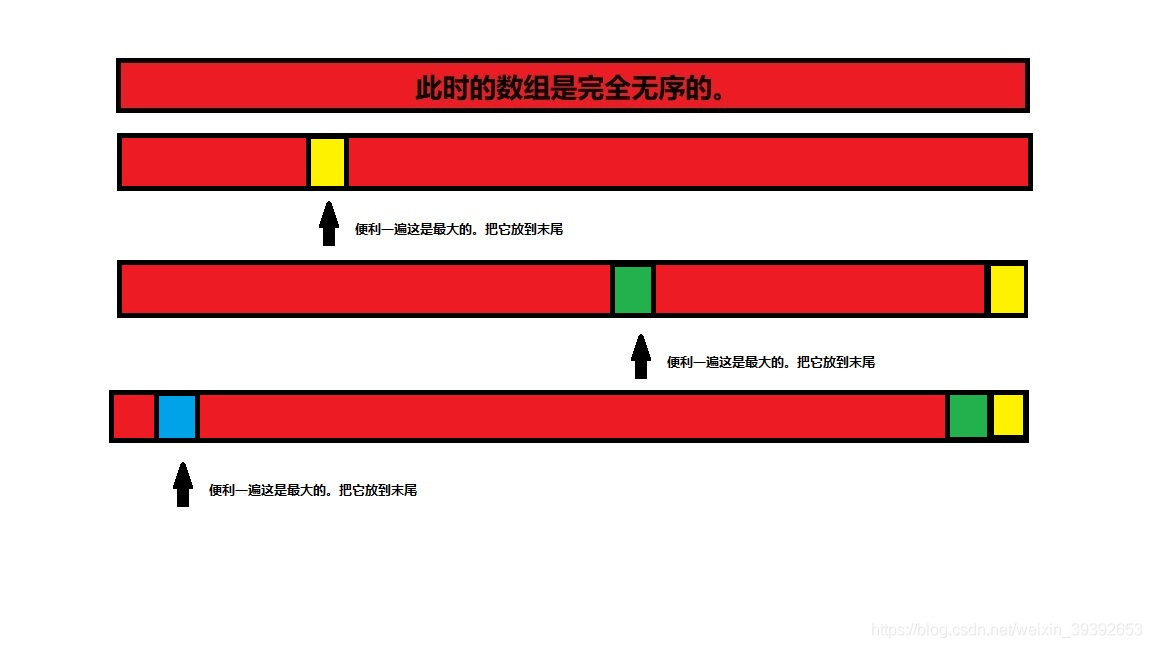
算法分析
时间复杂度:O(n^2)
空间复杂度:O(1)
稳定性:不稳定
算法实现
void SelectionSort(int arr[], int size)
{
int i = 0;
int j = 0;
for (i = size; i > 1; i--)
{
int MAX = 0;
for (j = 0; j < i; j++)
{
if (arr[j]>arr[MAX])
{
MAX = j;
}
}
int tmp = arr[i - 1];
arr[i - 1] = arr[MAX];
arr[MAX] = tmp;
}
}
堆排序
算法思想
这里需要对堆有一定的了解,堆就是一个比较特殊的完全二叉树,在最大堆里,每个节点的值都大于其左右两个孩子节点的值。这就是最大堆。反之就是最小堆。拿最大堆举例子,每次堆顶的元素值,不就是当前数列的最大吗?这不就成选择排序里的简单排序了吗?找完之后,将他和完全二叉树里最后一个结点的值进行交换,然后做一个自顶向下的自我调整,将他再次调整成一个完全二叉堆。第二次取最大的树,这时我们需要将上一次找到的结点屏蔽掉,不然会陷入一个死循环。无数次找完之后,再按层序的思想将二叉树里的数据遍历到一个数组当中,这时的数组为一个有序的数组。
这里有一个需要自己理解的就是在选择建大堆和建小堆的选择,我们对比说明为什么建大堆,比建小堆要好。每次拿走元素和末尾元素交换,调整时大堆交换完,下面也是满足最大堆的要求,下面接着调整,可以调整成为一个完全二叉大堆。而选择最小堆的话,无法自顶向下的调整,而需要自低向上的去调整,就等于重现建堆。如果我们学过了最大堆和最小堆都知道,最大堆的调整难度完全小于新建一个最小堆。所以优选建大堆。
算法图解
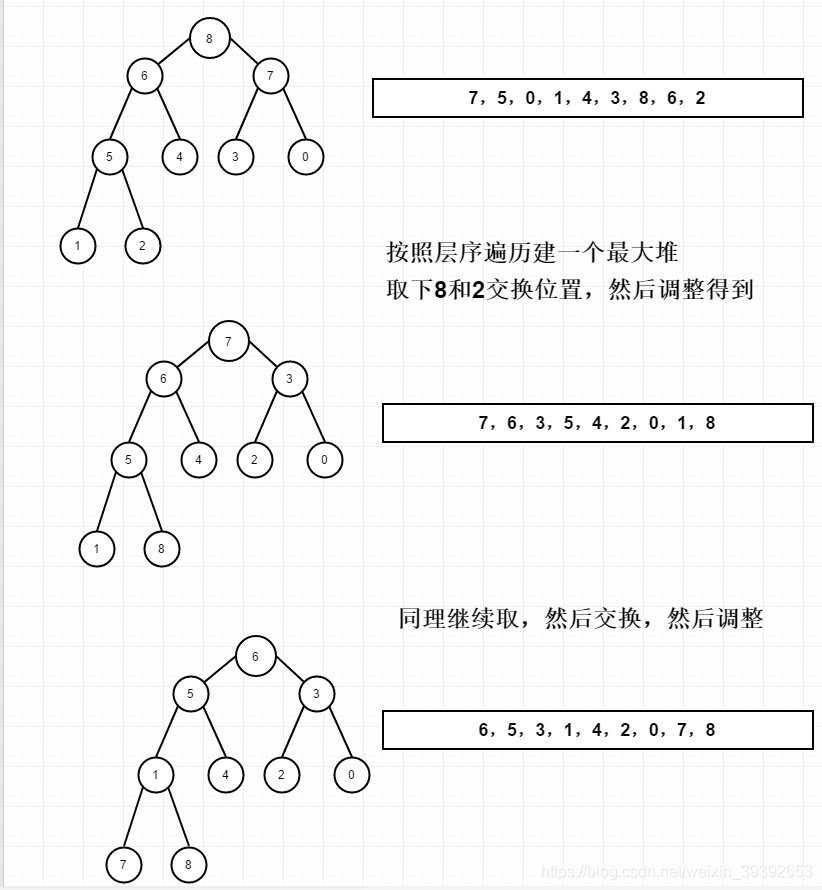
算法分析
时间复杂度:O(nlog2n)
空间复杂度:O(1)
稳定性:不稳定
算法实现
void AdjustDown(int arr[], int size, int root)
{
int left = 2 * root + 1;
int right = 2 * root + 2;
if (left >= size)
{
return;
}
int max = left;
if (right < size && arr[right] > array[left])
{
max = right;
}
if (arr[root] >= arr[max])
{
return;
}
Swap(arr + root, arr + max);
AdjustDown(arr, size, max);
}
void CreateHeap(int arr[], int size)
{
for (int i = size / 2 - 1; i >= 0; i--)
{
AdjustDown(arr, size, i);
}
}
void HeapSort(int arr[], int size)
{
CreateHeap(arr, size);
for (int i = 0; i < size; i++)
{
Swap(&arr[0], &arr[size - 1 - i]);
AdjustDown(arr, size - i - 1, 0);
}
}
交换排序
冒泡排序
算法思想
这个应该是最基础的排序,我大学接触的第一个排序,冒牌排序,拿数组第一个元素和第二个元素比,然后拿第二个在和第三个比,然后第三个和第四个比。第一遍遍历结束,最大的数来到最末端,然后下次对剩下的比较。这里我们叫一个FLAG,也是就是说如果冒泡一遍,完全没有发生交换,那就是剩下的数字已经有序了,可以跳出,不需要再执行剩下的比较,完全是浪费。
算法图解
求你了,冒泡实在不想画了,画图真的费时间,冒泡的图能把人画疯。。。冒泡看不懂聊我QQ292217869
算法分析
时间复杂度:O(n^2)
空间复杂度:O(1)
稳定性:稳定
算法实现
void BubbleSort(int arr[], int size)
{
int i = 0;
int j = 0;
for (i = 0; i < size-1; i++)
{
for (j = 0; j < size-1-i; j++)
{
int count = 0;
if (arr[j] > arr[j + 1])
{
int tmp = 0;
tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
count++;
}
if (count == 0)
{
return;
}
}
}
}
快速排序
算法思想
我们老师给我们花了100个星星的重要,那就是非常重要,快速排序。名字就很嚣张。。。言归正传,快排采用了分治算法。把大问题,分解成小问题。首先我们先找一个基准值,基准值的寻找法,有很多,这里我先用一个取边上值得方法,找到基准值以后呢拿着这个基准值和所有数组比较,使这个数组中比基准值小的都放左边,比基准值大的都放到右边,然后就把原来数组分成三块,中间基准值,左边都是比它小的,右边都是比它大的。然后这两个数组,继续分,一直分。直到他的终止条件,也就是小数组有序了就停止,那么什么时候有序停止呢?小区间长度为1或者长度为0的时候,就是有序了。所有小数组都有序了,那么就是整个数组有序了。只是原理,那么问题,又来了,怎么放左放右呢?我目前会三种。
Hover法,什么意思呢?假设最边上是基准值,剩下的元素最右是一个Begin指针,最左是一个End指针,之前说放右边的,放Begin的右边,指针向左移动,之前放左边的放End左边,所以End指针向右移动。慢慢的慢慢的,Begin和End指针指向了同一块空间,就代表着结束了,那么我们的基准值的位置,就是这个相同地址的位置。
挖坑法,挖坑法应该叫边挖边填坑法比较好。主要就是先把基准值(我们这里找最右边的)的位置,挖下来,赋值给pivot,那么最右边的位置是坑,然后左边的指针寻找比pivot大的,找到了,放进坑里,这个位置形成了一个新的坑,然后从右再往左找。遇见了,再挖再填,直到两个指针指向相同的空间。把最新挖出的数,填进去,一遍就好了。那么整个数组就变成有序的数组了。
左右指针法,怎么说呢,HOVER法的图形画出来,不就是,小的,不知道的,大的,基准值。而左右指针法,就是小的,大的,不知道的,基准值。就是开始定义两个指针(其实也可以不用),他们都指向最左边,一个叫cur,一个叫div,我们保证,div的左边都是比基准值小的。然后开始遍历cur,当cur比基准值小的时候,cur和div换一下数据,然后,div往前走一格,保证左边比它小。cur继续遍历,直到cur走到基准值身边,代表遍历完了,交换cur和div的值。就好了。
算法图解
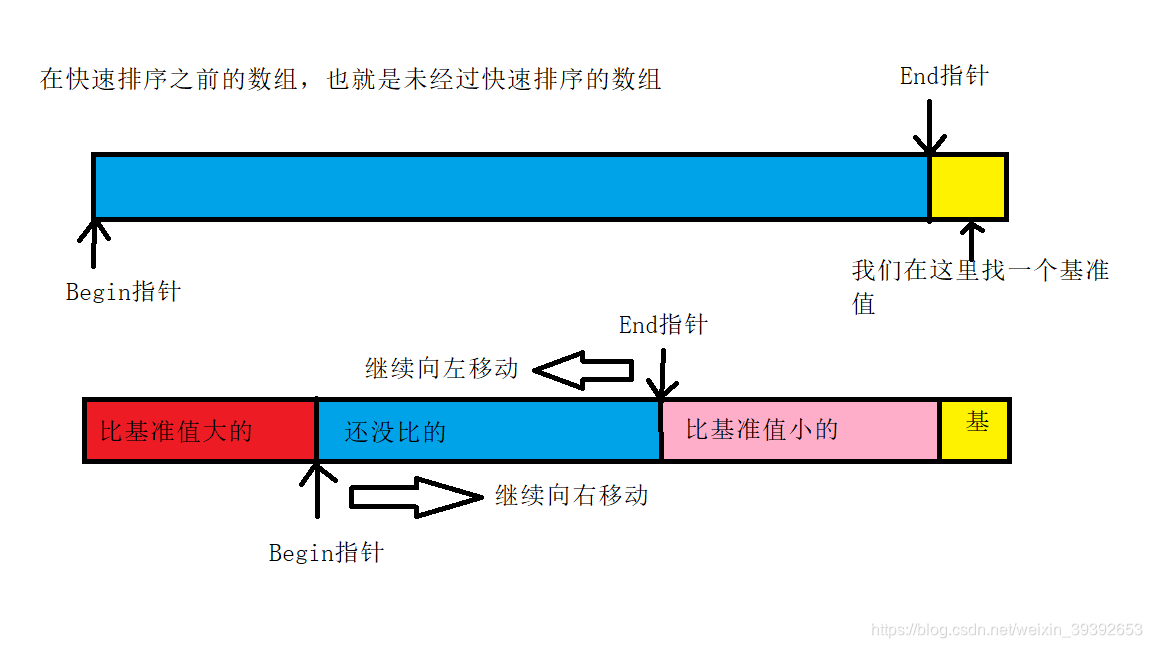

算法分析
时间复杂度:O(nlog2n)
空间复杂度:O(nlog2n)
稳定性:不稳定
算法实现
int Partition3(int arr[], int left, int right)//左右指针法
{
int cur = left;
int div = left;
while (cur < right)
{
if (arr[cur] < arr[right])
{
int tmp = arr[cur];
arr[cur] = arr[div];
arr[div] = tmp;
div++;
}
cur++;
}
int tmp = arr[cur];
arr[cur] = arr[div];
arr[div] = tmp;
return div;
}
int Partition2(int arr[], int left, int right)//挖坑法
{
int begin = left;
int end = right;
int pivot = arr[end];
while (begin < end)
{
while (begin < end&&arr[begin] <= pivot)
{
begin++;
}
arr[end] = arr[begin];
while (begin < end&&arr[end] >= pivot)
{
end--;
}
arr[begin] = arr[end];
}
arr[begin] = pivot;
return begin;
}
int Partition1(int arr[], int left, int right)//hover法
{
int begin = left;
int end = right;
while (begin < end)
{
while (begin < end&&arr[begin] <= arr[right])
{
begin++;
}
while (begin < end&&arr[end] >= arr[right])
{
end--;
}
int tmp = arr[begin];
arr[begin] = arr[end];
arr[end] = tmp;
}
int tmp = arr[begin];
arr[begin] = arr[right];
arr[right] = tmp;
return begin;
}
void __QuickSort(int arr[], int left, int right)
{
if (left == right)
{
return;
}
if (left > right)
{
return;
}
int div = Partition1(arr, left, right);//这里选择三种方法
__QuickSort(arr, left, div - 1);
__QuickSort(arr, div + 1,right);
}
void QuickSort(int arr[], int size)
{
__QuickSort(arr, 0, size - 1);
}
归并排序
算法思想
这里和快排一样,老师依旧是直接打了100个星星,太重要啦。归并排序和快排很容易混淆,因为归并排序也用到了分治算法的思想。思路是,现在对一个数组进行排序,我们把数组分为两份,如果左边数组是有序的数组了,右边也是一个有序的数组了,那么我们把两个数组合并起来,整个数组就有序了,如果这两个数组不是有序呢?那我们继续分,分分分,直到小区间只剩下一个元素的时候,那么整个小区间就是有序的了。
算法图解
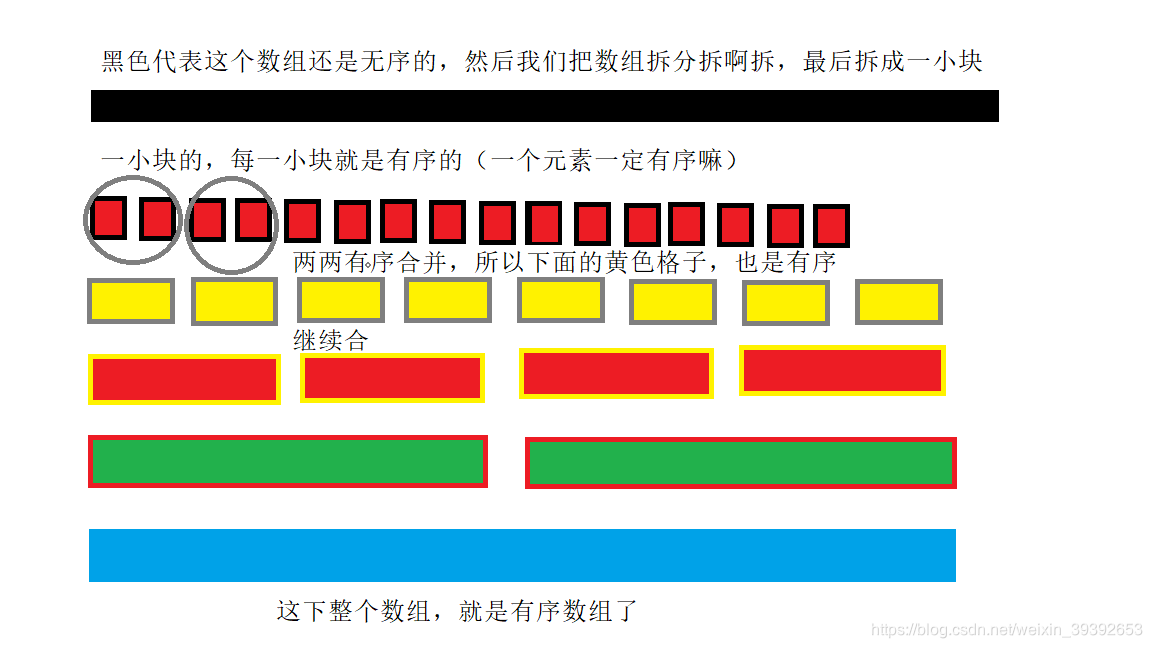
算法分析
时间复杂度:O(nlog2n)
空间复杂度:O(1)
稳定性:稳定
算法实现
void Merge(int arr[], int left, int mid, int right,int extra[])
{
int left_i = left;
int i = left;
int right_i = mid;
while (left_i < mid&&right_i < right)
{
if (arr[left_i] <= arr[right_i])
{
extra[i++] = arr[left_i++];
}
else
{
extra[i++] = arr[right_i++];
}
}
while (left_i < mid)
{
extra[i++] = arr[left_i++];
}
while (right_i < right)
{
extra[i++] = arr[right_i++];
}
for (i = left; i < right; i++)
{
arr[i] = extra[i];
}
}
void __MergeSort(int arr[], int left, int right,int extra[])
{
if (left == right - 1)
{//区间只有一个元素,就代表有序
return;
}
if (left >= right)
{//区间没有元素了
return;
}
int mid = left + (right - left) / 2;
__MergeSort(arr, left, mid,extra);
__MergeSort(arr, mid, right,extra);
Merge(arr, left, mid, right,extra);
}
void MergeSort(int arr[], int size)
{
int *extra = (int *)malloc(sizeof(int)*size);
__MergeSort(arr, 0, size,extra);
free(extra);
}
基数排序
算法思想
基数排序是对哈希算法的运用,我们将一个数组,每一个数据,按照个位0-9存入哈希桶,得到一个个位排序的数列,并在哈希桶里对重复数字进行标记。取出,然后在对十位进行同样的操作,百位,千位。等等。直到最大的数据,的最高位。经过这无数次排序后,一个数列就有序了。
算法图解

算法分析
时间复杂度:O(d(r+n))
空间复杂度:O(rd+n)
稳定性:稳定
算法实现
int GetMaxDigit(int arr[], int size)
{
int digit = 1;
int base = 10;
int i = 0;
for (i = 0; i < size; i++)
{
while (arr[i] >= base)
{
++digit;
base *= 10;
}
}
return digit;
}
void RadixSort(int arr[], int size)
{
int i = 0;
int j = 0;
int k = 0;
int digit = GetMaxDigit(arr, size);
Node **array = (Node *)malloc(sizeof(Node)*size);
for (k = 0; k < digit; k++)
{
for (i = 0; i < size; i++)
{
array[i] = NULL;
}
for (i = 0; i < size; i++)
{
int index = (arr[i] / pow(10, digit)) % 10;
Node *node = (Node *)malloc(sizeof(Node));
node->Data = arr[i];
if (array[index] == NULL)
{
array[index] = node;
node->Next = NULL;
}
Node *cur = array[index];
while (cur->Next != NULL)
{
cur = cur->Next;
}
cur->Next = node;
node->Next = NULL;
}
for (i = 0; i < 10; i++)
{
Node *cur = array[i];
while (cur->Next != NULL)
{
arr[j++] = cur->Data;
cur = cur->Next;
}
}
}
free(array);
}
总结
算法对比
再写博客期间也看了很多博客,忘记从哪里搞到一张排序的时间空间复杂度的对比图(其实是作者懒癌发作)

再给大家一个高精度计时器的代码,可以自己测一下每种排序所消耗的时间。建议数据大一点,现在计算机跑这些500,1000个数据的代码,宛如张飞吃豆芽,大一点才能看到结果。
class HighPrecisionTimer
{
public:
HighPrecisionTimer(void)
{
QueryPerformanceFrequency(&CPU频率);
}
~HighPrecisionTimer(void){}
void 开始()
{
QueryPerformanceCounter(&开始时间);
}
void 结束()
{
QueryPerformanceCounter(&结束时间);
间隔 = ((double)结束时间.QuadPart - (double)开始时间.Quadpart)/(double)CPU频率.QuadPart;
}
double 间隔毫秒()const
{
return 间隔 *1000;
}
pricate:
double 间隔;
LARGE_INTEGER 开始时间;
LARGE_INTEGER 结束时间;
LARGE_INTEGER CPU频率;
};
排序心得
写大大的!快排,快排,快排!归并!归并!归并!选择选择选择!!
你们懂我意思吧!重中之重。
排序是数据结构中我认为最经典的东西。因为数据的有序,不仅对用户来说,视觉的舒服。也方便我们再写其他的功能使用。刚开始学习需要极度认真听老师讲。但是最重要的,是自己练,我加大一下字体
自己练
一定要动手,哪怕错的,哪怕写代码卡的再久再久,也要动手。不卡说明你没理解,卡了才是真的思考。比如1.就是堆排序的选择上。我卡了1天。基数排序,一开始思想错的,卡了好久。但是却能解决,写了300多行没用的代码。直到想明白了哈希。瞬间写出基数排序的代码。所以思考远比代码重要(当然,该码的你还得码)