首先,我配上一张图,可以很好的解释问题:
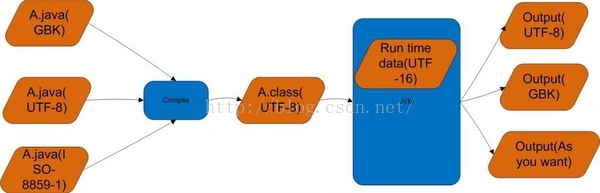
这张图表明,不论java文件是什么字符编码的,经过编译器编译后,字符在class文件中都会变成UTF-8编码,实际上是一种modified UTF-8,modified utf-8是java对utf-8作了修改的版本。
后面,当JVM把这个class文件载入内存后,就会把字符转换为UTF-16编码存放在内存中。因此,在运行时,内存中字符串的编码都是用UTF-16方式编码的。
下面,说正事。
最初,Unicode字符集设想用两个字节就能表示所有的字符了,所以Java也把char类型设定为2字节的大小。但是,后来东亚文字的加入使得两个字节不足以表示所有的字符。于是, Unicode开始扩展,把编码范围变为0x0到0x10FFFF。Java把这个编码值称为代码点。Unicode的代码点可以分成17个代码级别(code plane)。第一个代码级别称为基本的多语言级别,代码点从U+0000到U+FFFF,这包括了经典的Unicode代码。其余的是16个附加级别,代码点从U+10000到U+10FFFF,其中包括了一些辅助字符(supplementary character)。其实就是每个级别分别占据着65536个位置,即16位。
Java程序在运行时,即JVM内部,对于字符采用UTF-16编码。K这个编码方式采用不同的编码表示所有的Unicode代码点。在基本的多语言级别中,每个字符用16位表示,称为一个代码单元。所以说,一个char类型就是一个代码单元。而对于辅助字符,Java采用一对连续的代码单元来进行编码,即32位。因为基本的多语言级别中有2048个位置是空闲的(U+D800到U+DFFF),所以用来编码辅助字符的代码单元的值必然要落在这个空闲区间中,通常称为替代区域(surrogate area)。其中,U+D800~U+DBFF用于第一个代码单元,U+DC00~U+DFFF用于第二个代码单元。这样做,我们就可以迅速判断这是用一个代码单元还是两个,还能迅速判断是第几个代码单元。至于,UTF-16具体是如何用两个代码单元来编码一个代码点的,这里我就不说了,自己百度吧。
说到这里,就可以知道java中的char类型其实是比较底层的,有时候一个char类型不一定就表示一个字符,对于比较生僻的字符要两个才行。所以,有时候String的length返回值不一定与能看到的字符数相等,因为length方法返回的是char类型的数量。
最后再讲一下JVM的默认编码,即defaultCharset。这个不是指UTF-16,JVM内部的字符串永远都是UTF-16编码的,而是指把JVM内部的UTF-16字符串转换成Byte数组时或输出时的默认转换编码,即要把字符串从UTF-16编码转换为这个默认编码。我觉得也可以理解为,当一个方法需要一个指定字符编码的参数时,如果默认不写就会用这个默认编码。这个默认编码通常就是操作系统的默认编码,中文Windows通常就是GBK编码。当然,我们也可以改,就是在运行程序的时候加上参数-Dfile.encoding=xx来修改这个默认编码。