新的卷积计算方法
这种是直接提出新的卷积计算方式,从而减少参数,达到压缩模型的效果,例如SqueezedNet,mobileNet
1. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size
代码地址:https://github.com/DeepScale/SqueezeNet
下图是论文中的Fire Module,将上一层的输出分别输入到1*1的卷积核3*3的卷积层中。
使用以下三个策略来减少SqueezeNet参数 :
(1)使用1∗1卷积代替3∗3 卷积:卷积模板的选择,从12年的AlexNet模型一路发展到2015年底Deep Residual Learning模型,基本上卷积大小都选择在3x3了,因为其有效性,以及设计简洁性。本文替换3x3的卷积kernel为1x1的卷积kernel可以让参数缩小9X。但是为了不影响识别精度,并不是全部替换,而是一部分用3x3,一部分用1x1。
(2)减少输入3x3卷积的input feature map数量 :这一部分使用squeeze layers来实现 。参数量=通道数*filter数*卷积窗口,因此减少feature map的输入数量就可以一定程度上的减少参数量。
(3)将欠采样操作延后,可以给卷积层提供更大的激活图:更大的激活图保留了更多的信息,可以提供更高的分类准确率 。在具体实现时,只在卷积第1、4、8层做了max pooling,在conv10做了全局平均pooling
其中,(1)和(2)可以显著减少参数数量,(3)可以在参数数量受限的情况下提高准确率。
另外论文中还使用了global average pooling代替全连接层的策略来进一步减少参数量(关于GAP要复习一下NIN)。
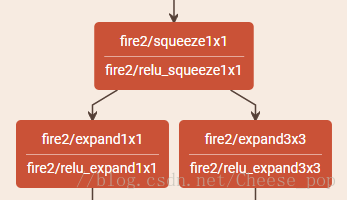
可以看出,Squeeze层由于使用1∗1卷积极大地压缩了参数数量,并且进行了降维操作,但是对应的代价是输出特征图的通道数(维数)也大大减少。之后的expand层使用不同尺寸的卷积模板来提取特征,同时将两个输出连接到一起,又将维度升高。但是3∗3的卷积模板参数较多,远超1∗1卷积的参数,对减少参数十分不利,所以作者又针对3∗3卷积进行了剪枝操作以减少参数数量。从网络整体来看,feature map的尺寸不断减小,通道数不断增加,最后使用平均池化将输出转换成1∗1∗1000完成分类任务。
2.MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
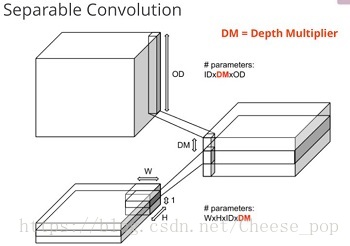
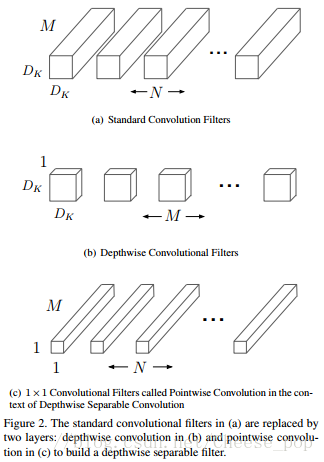
这篇文章主要基于深度可分离卷积(具体参考有道云笔记)。
深度可分离卷积是基于Xception的,在Xception中是先做channelwise的卷积再做pointwise的卷积,例如:在经典的卷积操作,如果output channel是256,input channel是128,卷积核大小3*3,那么参数量为128∗3∗3∗256=294912128∗3∗3∗256=294912,而Spearable卷积方法,假如DM=4,这样中间层的channel数为128*4=512,再经过1*1卷积降维到256个channel,需要的总参数为:128*3*3*4 + 128*4*1*1*256=135680,参数量相当于普通卷积的46%,还增加了通道数(128*4=512)增强了特征表达能力。
在MobileNet中,作者也是先做深度方向上的卷积,再做点卷积。
对MobileNet的参数量分析:

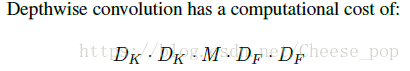
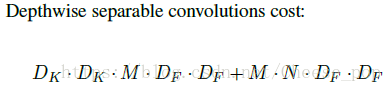

3.ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile
做模型压缩的连起名字的方式都是类似的么。。。
具体讲解参考:https://blog.csdn.net/u011974639/article/details/79200559,这里的关于shuffle的图例很清晰明了。
文章的主要基于两个点:1)深度可分离卷积;2)Group Convolution。
主要的贡献点就是做了一个通道混洗(Channel shuffle)
已训练好的模型上做裁剪
方法
这种就是在训练好的模型上做一些修改,然后在fine-tuning到原来的准确率,主要有一些方法:
剪枝:神经网络是由一层一层的节点通过边连接,每个边上会有权重,所谓剪枝,就是当我们发现某些边上的权重很小,可以认为这样的边不重要,进而可以去掉这些边。在训练的过程中,在训练完大模型之后,看看哪些边的权值比较小,把这些边去掉,然后继续训练模型;
权值共享:就是让一些边共用一个权值,达到缩减参数个数的目的。假设相邻两层之间是全连接,每层有1000个节点,那么这两层之间就有1000*1000=100万个权重参数。可以将这一百万个权值做聚类,利用每一类的均值代替这一类中的每个权值大小,这样同属于一类的很多边共享相同的权值,假设把一百万个权值聚成一千类,则可以把参数个数从一百万降到一千个。
量化:一般而言,神经网络模型的参数都是用的32bit长度的浮点型数表示,实际上不需要保留那么高的精度,可以通过量化,比如用0~255表示原来32个bit所表示的精度,通过牺牲精度来降低每一个权值所需要占用的空间。
神经网络二值化:比量化更为极致的做法就是神经网络二值化,也即将所有的权值不用浮点数表示了,用二进制的数表示,要么是+1,要么是-1,用二进制的方式表示,原来一个32bit权值现在只需要一个bit就可以表示,可以大大减小模型尺寸。
论文
XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks
网络权重二值化、输入二值化,从头开始训练一个二值化网络,不是在已有的网络上二值化
Learning both Weights and Connections for Efficient Neural Networks
学习重要的连接,根据连接的权重进行裁剪,fine-tuning让网络保持稀疏的连接
Exploiting linear structure within convolutional networks for efficient evaluation.
对已经训练好的网络应用奇异值分解
Eie: Efficient inference engine on compressed deep neural network.
加速器
Deep compression: Compressing DNNs with pruning, trained quantization and huffman coding.
裁剪(阈值)、量化(8bit,存储方式)、哈夫曼编码
http://blog.csdn.net/may0324/article/details/52935869
Deep Model Compression: Distilling Knowledge from Noisy Teachers
Teacher-student Framework,一个网络指导另外一个网络的训练
PerforatedCNNs: Acceleration through Elimination of Redundant Convolutions
在一些稀疏位置跳过CNN求值,加速效果不明显,且不能压缩模型
Binarized Neural Networks: Training Neural Networks with Weights and Activations Constrained to +1 or −1
训练二值化网络
https://tensortalk.com/?cat=model-compression-parameter-pruning
PRUNING FILTERS FOR EFFICIENT CONVNETS
计算filter的L1范数,直接过滤掉较小L1范数对应的feature map, 然后再次训练,有两种,一是每裁剪一层训练一下,一是直接裁剪整个网络,然后fine-tuning. 相比权值连接的裁剪,这种比较暴力,好处就是不会引入稀疏矩阵的计算,从而也不需要稀疏矩阵库,坏处就是可能无法恢复到最开始的准确率。