最近人工智能太火了,大家都在说什么Deeplearning、神经网络、深度学习,各行各业都搞起了这方面的业务,诚然,深度学习确实有很大的技术改进优势,但是也不是马上就能秒杀一切传统的技术的。针对于图片文字识别OCR这方面,我想跟大家探讨几个方面的问题。
首先我要跟大家说明的是:我不是技术开发人员,对各种OCR算法有一些基础认识,但了解内容有限,我仅仅是针对目前遇到的一些现状,并结合实际场景应用,与大家做个分享与讨论,有不当之处,大家可以留言或者联系我进行交流沟通。
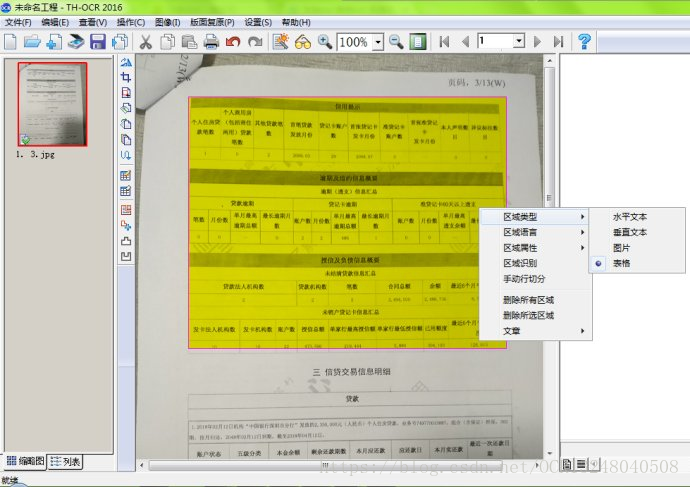
首先我这边要说的是传统的的文档OCR文字识别技术,他是有对图片上的内容进行认识分析的过程,其中比较重要的就是有个四要素,横排文本、竖排文本、表格、配图;每一个人们写的材料,文章等文件中都是由这四个基本要素组成。
在传统的文档OCR识别技术中,算法会先分析图片中有几个布局区域,然后分析出水平横向文字,竖向垂直文字,表格和配图照片等区域,然后在针对各自的特点进行切分字符,保留区域类型,进行OCR识别调整;所以可以适应各种类型的文本识别。有些小角度的倾斜文本,OCR程序也可以进行智能调整识别;
深度学习的OCR技术是最近一年兴起来的,这个技术的抗干扰能力很强,可以识别比较复杂背景情况下的图片,但是现在的深度OCR识别技术并没有专门的公司去做深度研究和技术演练,目前的情况是可以很好地输出“行文字信息”以及“列文字信息”,所以如果想用深度学习的OCR技术去处理文档资料的话,会很不合适!
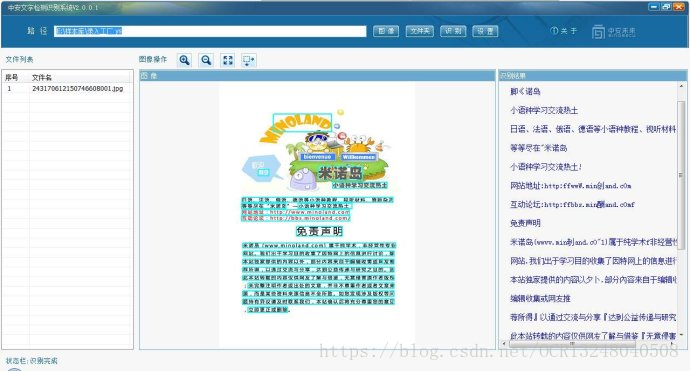
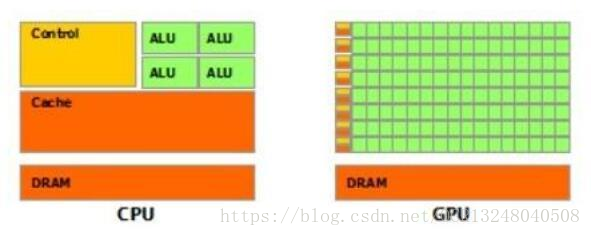
但是如果用来处理各种非文档类型的,场景照片中文字,广告海报中的文字,那么深度学习技术的OCR程序就会很有优势,如果您想做这方面的技术应用,就需要配备一台显卡比较牛的服务器,因为深度学习的技术跑的是GPU,对显卡的等级要求很高,不像跑CPU的传统OCR文字识别技术。
好了,先讨论分享这么多,大家还有什么想了解的,可以与我沟通!