版权声明:本文为博主原创文章,转载请注明出处。 https://blog.csdn.net/Eiceblue/article/details/82592566
本文将介绍如何在Java应用程序中读取PDF文件的文本内容。
在Java应用程序中读取PDF,我们可以借助第三方PDF控件,本文所使用的控件是免费Java PDF组件Free Spire.PDF for JAVA。
在使用以下代码前,你需要下载Free Spire.PDF for JAVA包并解压缩,然后从lib文件夹下,导入Spire.Pdf.jar包和Spire.Common.jar包到你的Java应用程序中:

Extract_Text.Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import java.io.*;
public class Extract_Text {
public static void main(String[] args) {
//创建PdfDocument实例
PdfDocument doc= new PdfDocument();
//加载PDF文件
doc.loadFromFile("test.pdf");
StringBuilder sb= new StringBuilder();
PdfPageBase page;
//遍历PDF页面,获取文本
for(int i=0;i<doc.getPages().getCount();i++){
page=doc.getPages().get(i);
sb.append(page.extractText(true));
}
FileWriter writer;
try {
//将文本写入文本文件
writer = new FileWriter("ExtractText.txt");
writer.write(sb.toString());
writer.flush();
} catch (IOException e) {
e.printStackTrace();
}
doc.close();
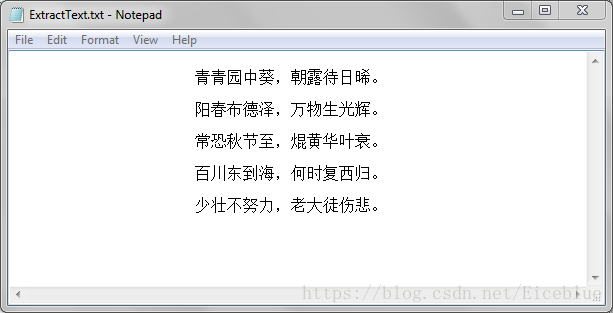
}PDF文件:
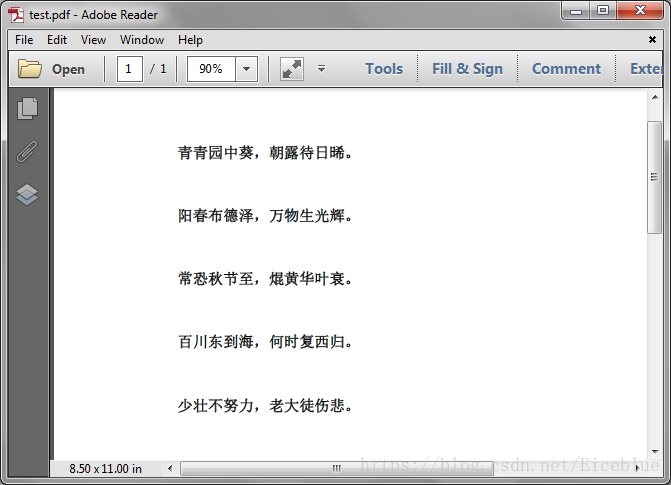
输出文本文件: