魅族推送平台架构及优化
内容简介
平台从支撑魅族内部业务到对外能力开放过程中一系列的系统架构优化及扩张,
支撑亿级高并发消息实时推送,包括服务高可用、监控、容灾、流量调度、海量存储等方面的实践与探讨。
平台介绍
魅族推送平台在2016年9月之后开始对外开放,目前接入的APP大概有2000+,日推送总量达到6亿,
整个通道平台推送的峰值可以达到600万/分钟,理论峰值在整个集群部署架构下还可以在此基础上翻一倍,
达到1200万/分钟。
架构与实践
主要分为:推送平台服务、魅族推送通道,基本流程是终端接入推送通道(TCP),
接入应用服务端通过推送平台服务将消息分流到推送通道,然后通过通道push到设备端。
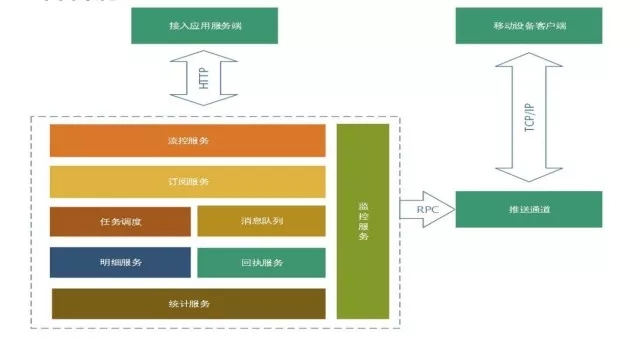
如图所示,推送平台的组成模块包括:
-
接入层的流控服务: 我们对推送流量的平衡和过载保护做了全局的分布式流控服务。
-
订阅服务: 简单来说客户端接入SDK之后上报的应用数据和标签数据还有别名数据,都是在订阅服务做储存。
-
业务逻辑层: 有一个任务调度,主要是做消息后台任务推送的模块,我们做了一个高可用分片的任务推送。
-
消息队列服务: 共享和独立通道。
-
消息推送明细服务: 会将整个消息推送流程链路全部上报到这个服务,这个服务的能力也是对外开放的,问题排查主要涉及这个服务。
-
消息回执服务: 主要将推送消息的到达和点击回执到第三方接入的应用服务。
-
平台提供的实时统计服务
-
整个平台的监控服务
微服务
2016年9月份之前,推送平台的架构是高耦合的,只提供单独对外接入和对内消息推送的模块,
所有的订阅、推送、分发都在一个模块里。
开放之后我们对服务做了详细拆分,除了前面提到的大的模块以外,我们还做了服务治理。
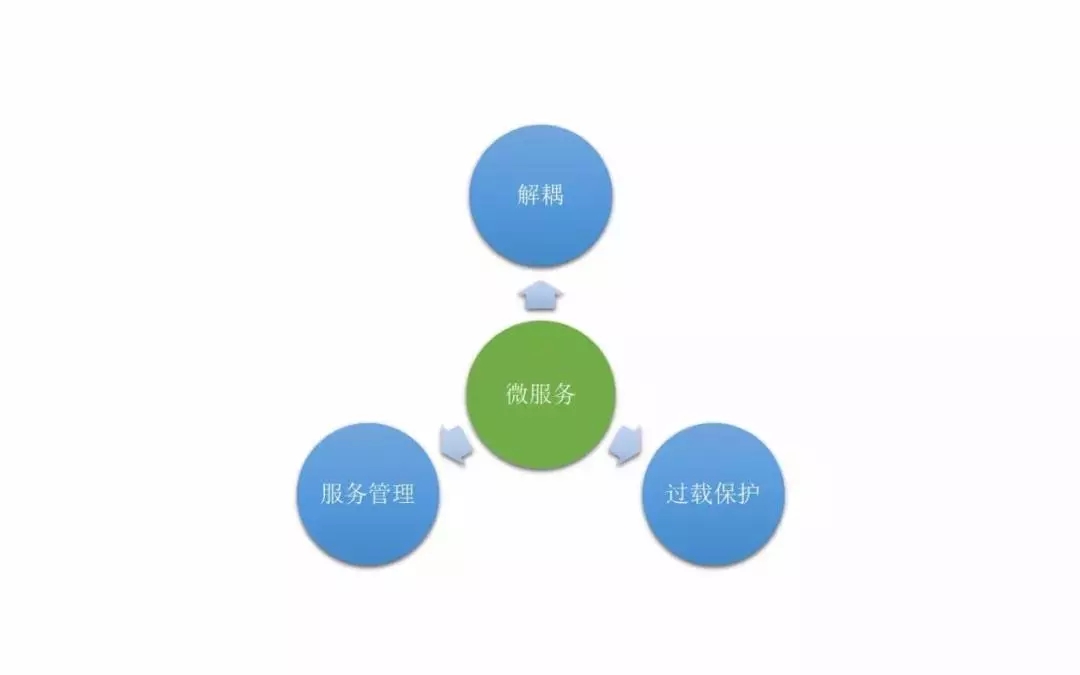
魅族有一个自己提供的RPC服务的框架,可以提供高质量的服务管理,对服务自动注册、发现、监控等都有体现。
还有系统过程中的过载保护策略,
因为我们是面向大量消息推送的平台,对海量消息推送,要对这个平台的容灾性做可靠性保障。
过载保护
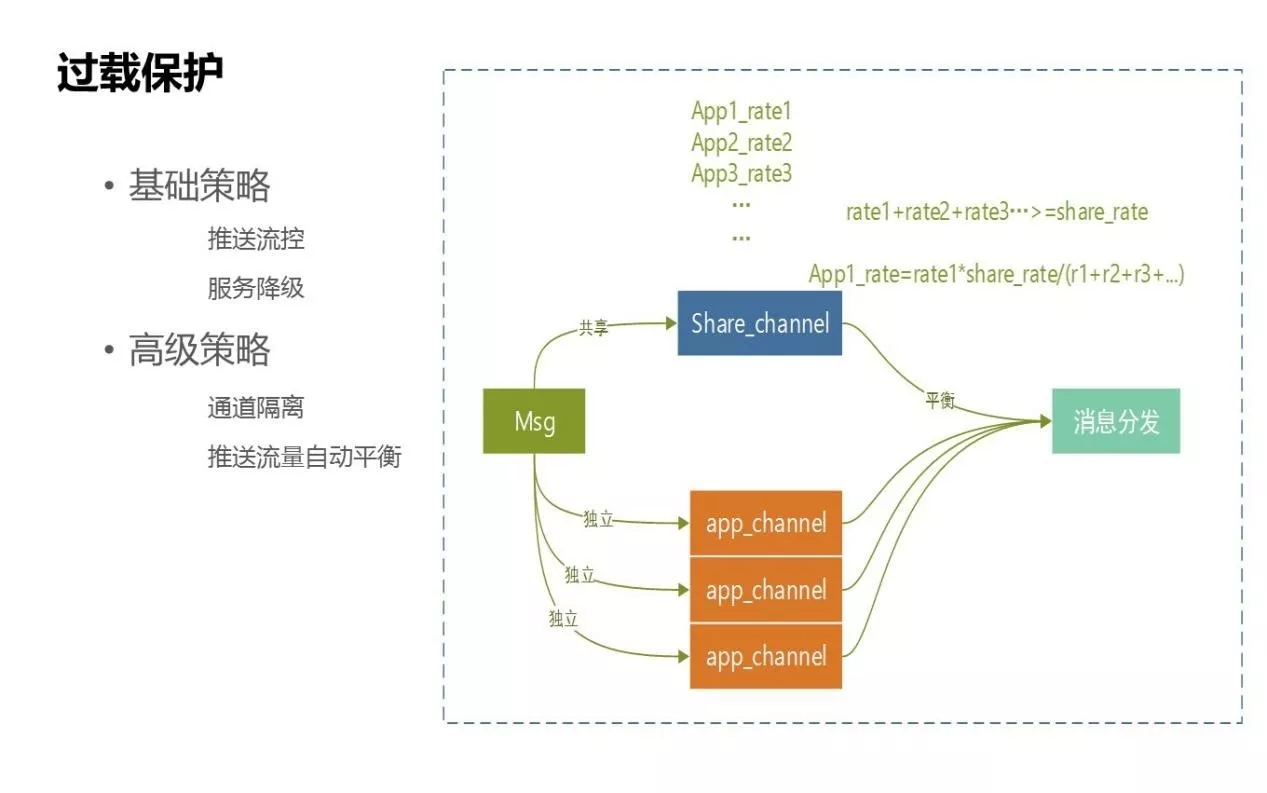
过载保护的策略分为两种:基础策略和高级策略。
- 基础策略:
比如流控的控制,常用的是对IP访问的阻断、推送频率的控制等,我们有这样的基础服务。还有一个基础策略是服务降级,我们用了一些开源组件。
- 高级策略:
我们为过载消息保护提供了通道,策略化主要是针对过载保护方面的,如图所示是整个消息下发到通道的吞吐量,比如高峰每秒钟是20万,要保证接入消息后还能平衡后面的业务推送通道。
- 独立通道:
针对的是APP级,每个APP会走独立自主通道,每个通道的速率和资源都是隔离的,APP通道不会受其他APP之间推送速率的影响。我们一般会申请为优先级高的应用配一个独立通道。
- 共享通道:
是除了独立通道之外的通道,其他APP也会走到共享通道。整个通道的并发能力是80万/每秒。通过给通道划分资源,为平衡速率,整个下来是不会超过上限的。比如目前有三个APP进入独享通道,每个APP速率都是不一样的,我们做了很简单的速率平衡,当整个的速率大于通道设置的阈值,就会算出等比压缩后每个APP的速率,保证三个APP对应的速率都不会超过整个通道的速率,以实现后端速率的过载保护。
有人会问,为什么要在消息这个地方做通道,而不是在流控的地方前置这个操作呢?
上游流控过载保护是指保护资源的流控限制,消息下游服务推送保护的是下游通道的资源过载,
通过这两个策略保证整个推送通道服务可用性。
熔断利器-Hystrix
过载保护还用到了自动降级熔断的组件,开源的Hystrix,这个组件对一个系统的熔断保护首先关心的条件是系统什么时候会触发熔断降级。
触发的条件包括服务的健康度是否正常。服务健康度包括服务错误率、服务是否超时、超时是否超过设定的阈值比例,比如单位时间内达到20%,
我认为下游比例就是过高的,这时相当于触发了熔断条件。
初步处理。时间窗临时禁止服务,在单位时间内,禁止对下游服务的调用,首先会保证当前服务的可用性,
不会出现由于通过下游服务的服务异常导致上游服务出现雪崩的情况。时间窗是临时禁止的,下游服务会出现完全挂掉或不可提供服务的情况。
进一步处理分两种。最简单最直接的方式是服务降级,我们这边对当前推送的消息做了异步处理,
当下游通道服务不可用的情况下,能够保证消息不能丢失,等服务恢复正常,消息继续通过通道下发到设备。
最粗暴的方式是直接拒绝当前服务调用的能力,把这个能力直接降级,这样的方式只会在出现很严重的问题时才会采用,比如整个服务出现不可用情况。
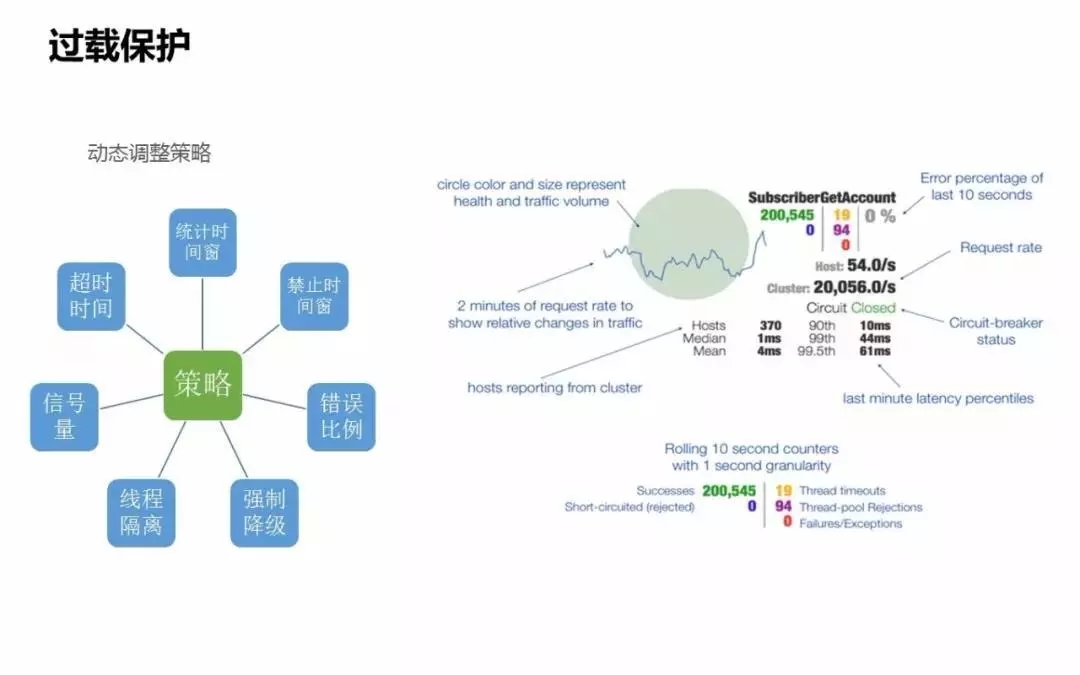
上图是Hystrix提供的后台监控表,它其实是服务健康度的大盘。大圈会实时显示依赖服务的健康度,还有服务的名称,通过健康度可以看到当前最关心的服务最近十秒钟内的健康情况。
还有依赖服务的QPS,可以很明确看到依赖下游服务,当前的流量是达到了什么峰值。
Hosts是有多少台机器接入服务,像图中的点显示有370台,表示上游部署了370台机器或服务节点来接入下游服务,可以很明确看到服务的节点数。从侧面也可以反馈到上游服务当前的服务健康度。
绿色的是当前依赖下游服务的健康度,这是一个熔断过载的状态,处于关闭的状态,表示当前服务是正常的,没有触发熔断。如果下游的服务达到熔断策略的话,这个状态会变成open状态,提示服务发送熔断预警。
还有一些很细的指标可以体现整个健康度的状态,下面还提供了很多对服务做隔离的指标,可以明确看到当前服务的健康度,有多少超时、多少被拒绝、多少执行失败。
过载的策略化
- 超时时间:
一般是A服务到B服务,我们最关心的是服务之间的超时时间,上游服务依赖下游服务,如果调用时间超过3秒钟,就认为下游服务是触发到熔断降级策略。
- 统计时间窗:
这里有个错误百分比,要在一定的时间内计算出来,这个策略统计时间窗也可以是动态调整的。比如10秒钟整个请求的调用通过是10%,我认为这个服务有质量问题,这是应该触发降级状态。
- 禁止时间:
降级之后紧接着是临时禁止时间,禁止时间窗时间是可以设置的,比如可以设置成10秒钟,当上下游服务依赖超过这个时间,在统计时间窗内错误百分比达到预设值,就禁止对下游服务的调用。这个调用是禁止使用的时间窗时间,比如禁止10秒钟时间不再进行调用。
- 错误比例:
结合统计时间的策略,配置错误百分比,错误百分比也是可以动态配置的。
- 线程隔离:
服务到服务之间的隔离,这个服务里可能有多个模块。如果想把A服务的调用跟B服务的调用做线程级别隔离,当A服务出现问题不会影响B服务的调用,可以设置当前服务用的是哪个线程栈,队列大小是什么。
- 强制降级:
如果出现熔断策略触发了降级,认为下游服务不可用的时候,需要开启强制降级。可以人工在后台通过配置对依赖服务做强制降级,这个降级状态直接变成Open状态,表示对下游服务的降级,从而能够保障当前服务的依赖,避免由于雪崩情况的发生而导致服务不可用。
问题和心得
推送性能问题
要做高性能就等于高并发或异步,针对性能的提升无非也是从这三点触发:怎么提高系统的并发度、和系统的缓存化、还有异步。
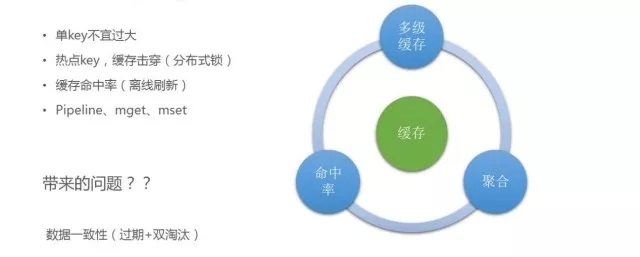
- 单key的问题:
当时做一个数据统计服务,我们设置的值过大,造成了数据划分的偏移,对整个集群的性能有很大影响,所以单key不宜设计过大,要做足够精细化的拆分。
- 热点key的问题:
缓存key其实是使用率很高的key,但一般缓存设置了过期机制,缓存过期之后,大量请求会到下游存储,比如DB层,这时整个系统的可靠性非常差。在缓存命中的时候,整个接口提供的QPS达到理想值,当热点key消失,大量请求击穿到DB层,性能下降。我们用了一个分布式锁,当多个服务要拿到热点Key的时候,简单加一个锁,只有其中进来一个请求,才可以落地到DB,把数据重新加载到缓存中,从而避免大量请求击穿到DB层。
- 缓存命中率的问题:
虽然系统做了缓存化,但整个系统的缓存命中率是比较低的,只有70%的命中率,因为缓存过期,请求进来之后要把缓存热加载到缓存中,这就有落地到DB的请求进来,导致整个缓存命中率降低。我们的策略是对一些热点key做离线定时刷新,有一个后台进程监测,如果key不在了,定时任务会把数据热加载到缓存中,从而提高缓存命中率。我们通过这个机制将缓存命中率从原来的70%多提高到了现在的99%。
在缓存使用过程中,要尽量做到聚合。之前有一个订阅服务,对当前推送目标是否有效都是通过缓存来进行处理的,对服务可用性和性能要求特别高。我们可以达到10万/秒,所有推送目标全部落到订阅服务来校验转化,之前我们认为平台的缓存性能很高,粗暴地采用轮询方式,后来发现当效率达到一定量级的时候对整个性能是有影响的,后来我们对于能够聚合的操作提供pipeline机制。
用了缓存不可避免会带来数据一致性问题,万一出现数据不一致,会对业务造成影响。
一方面我们做了时间有效期,敏感数据过期时间不能太长,比如只设置5-10分钟,还要对它进行离线刷新,保证数据一致性;
另一方面还有双淘汰的策略。一般对缓存数据与落地数据的更新,常规做法是我要更新一个数据,先把DB更新,再更新缓存,在更新DB的时候已经有数据拿出去了,把缓存中的数据清掉,上次拿掉没有更新之前的数据,又会把之前的数据重新加载,这样高并发的话很容易造成数据一致性问题。我们实行双淘汰,更新前后对缓存都做一次清理,达到数据一致性状态。
- 并发:
之前在消息推送时,严重依赖于MQ的队列组件,队列给我们提供的并发度是topic乘以分区数,存在的问题是:当推送消息量达到高峰的时候,比如线上达到五万,推送服务下发通道达到高峰,IO严重延迟,在不改变下游通道能力的前提下,要实现消息推送只能提高并发,也就是要增加分区数。增加分区数又会带来一个问题:增加分区会导致服务端的过载能力过高,导致队列集群负载高。我们把业务的整个并发度改成topic乘以线程池,最简单的就是在每次注册topic的时候,对单个topic做线程池的绑定。
这里修改完之后,我们在线上又发现了一个问题:推送过程中,整个消息的吞吐量已经上来了,服务重启的时候,所有消息拉取到本地之后其实是在内重启的,内重启会导致消息丢失,这是不能容忍的。因此我们在服务重启的时候加了一个线程hook,可以对整个topic拿到的消息做一个停止,不再拉取新的消息,等线程池里全部消息到手机终端,才会终止服务,从而保证在内存级别的消息不丢失。
还有一个缺点,服务如果出现非正常退出,比如机器挂了或者进程突然消失,内存级别的数据也会处于丢失状态,所以线程池的队列要在满足消息推送的总能力下设置得尽可能合理来规避这个问题。
-
海量数据明细存储问题:
-
明细队列数据积压:
海量数据流转的时候是上到队列,通过队列写入hbase,但高峰的时候仍然有数据积压,比如一条消息推送,我们会发消息到明细日志里,如果客户点击了,我们又会把消息写入队列,整个消息的聚合度是不够的,到了后端hbase都是根据上报粒度写的,基本上是一条一条写,这时在上报过程中做了消息的压缩,在每个服务拿到消息之后都做了队列压缩,跟上面提到的问题一样,要注意服务重启的时候,队列里面的数据也会结合数据重启。
-
hbase rowkey热点问题:
设备标识IMEI,每个IMEI都是有规则的,比如以8600开头的规则。我们是用rowkey,导致了写入集群的时候出现数据热点,海量数据都到一个点对集群的性能也有很大影响,这时要解决热点问题。我们对设备做一个逆序,在此基础上再根据集群做简单的哈希,追加到写入的key前,基本上就可以保证写入的数据能够均匀落到后端hbase服务的每个节点上,从而保障整个集群的可用性。
-
监控和灰度发布
监控
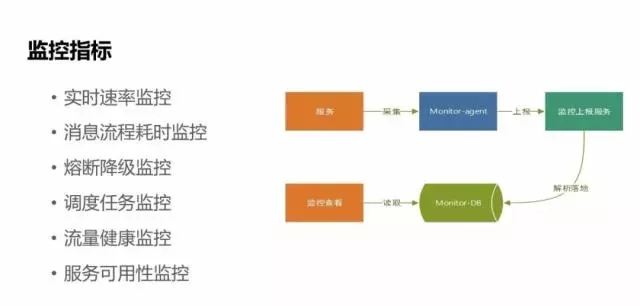
-
实时速率监控:
能够实时看到应用在系统中推送的一天流量变化峰值,预判推送服务的可靠性。
-
消息推送流程的耗时监控:
每套消息的整个推送流程可能涉及到几百个服务,我们在每个服务之间的耗时都做了很详细的埋点监控。
-
熔断降级监控和推送任务调度监控:
如果有失败,我们会有监控点上报通知。
-
流量健康监控:
针对到每个APP的健康指标监控。
-
服务可用性监控:
对服务指标的采集流程也是比较简单的,只是服务来上报指标,通过监控政策来上报统一到监控服务,然后监控服务对这些指标进行监控查看,如果触发监控指标,通过指标库来做预警。
灰度发布
灰度主要针对三个点:
-
流量灰度: 通过自动化运维平台实现;
-
APP灰度:
-
设备灰度: 可以针对固定的设备或者某一机型设备来做灰度发布。
魅族在发布方面已经有容器化平台,很明显的特点是可以做到在线自动化扩容缩容。