分布式系统原理(5)Quorum 机制
Quorum 机制是一种简单有效的副本管理机制。本节首先讨论一种最简单的副本控制规则
write-all-read-one,在此基础上,放松约束,讨论 quorum 机制
约定
为了简化讨论,本节先做这样的约定:更新操作(write)是一系列顺序的过程,通过其他机制确定更新操作的顺序(例如 primary-secondary 架构中由 primary 决定顺序),每个更新操作记为 wi,i 为更新操作单调递增的序号,每个 wi 执行成功后副本数据都发生变化,称为不同的数据版本,记作 vi。假设每个副本都保存了历史上所有版本的数据
Write-All-Read-One
Write-All-Read-One(简称 WARO)是一种最简单的副本控制规则,顾名思义即在更新时写所有的副本,只有在所有的副本上更新成功,才认为更新成功,从而保证所有的副本一致,这样在读取数据时可以读任一副本上的数据
假设有一种 magic 的机制,当某次更新操作 wi 一旦在所有 N 个副本上都成功,此时全局都能知道这个信息,此后读取操作将指定读取数据版本为 vi 的数据,称在所有 N 个副本上都成功的更新操作为“成功提交的更新操作”,称对应的数据为“成功提交的数据”。 在 WARO 中,如果某次更新操作 wi 在某个副本上失败,此时该副本的最新的数据只有 vi-1,由于不满足在所有 N 个副本上都成功,则 wi 不是一个“成功提交的更新操作”,此时,虽然其他 N-1 个副本上最新的数据是 vi,但 vi 不是一个“成功提交的数据”,最新的成功提交的数据只是 vi-1
这里需要特别强调的是,在工程实践中,这种 magic 的机制往往较难实现或效率较低。通常实现这种 magic 机制的方式就是将版本号信息存放到某个或某组元数据服务器上。假如更新操作非常频繁,那么记录更新成功的版本号 vi 的操作将成为一个关键操作,容易成为瓶颈。另外,为了实现强一致性,在读取数据的前必须首先读取元数据中的版本号,在大压力下也容易因为元数据服务器的性能造成瓶颈
分析一下 WARO 的可用性。由于更新操作需要在所有的 N 个副本上都成功,更新操作才能成功,所以一旦有一个副本异常,更新操作失败,更新服务不可用。对于更新服务,虽然有 N 个副本,但系统无法容忍任何一个副本异常。另一方面,N 个副本中只要有一个副本正常,系统就可以提供读服务。对于读服务而言,当有 N 个副本时,系统可以容忍 N-1 个副本异常。从上述分析可以发现 WARO 读服务的可用性较高,但更新服务的可用性不高,甚至虽然使用了副本,但更新服务的可用性等效于没有副本
Quorum 定义
WARO 牺牲了更新服务的可用性,最大程度的增强读服务的可用性。下面将 WARO 的条件进行松弛,从而使得可以在读写服务可用性之间做折中,得出 Quorum 机制
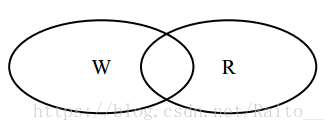
在 Quorum 机制下,当某次更新操作 wi 一旦在所有 N 个副本中的 W 个副本上都成功,则就称该更新操作为“成功提交的更新操作”,称对应的数据为“成功提交的数据” 。令 R>N-W,由于更新操作 wi 仅在 W 个副本上成功,所以在读取数据时,最多需要读取 R 个副本则一定能读到 wi 更新后的数据 vi 。如果某次更新 wi 在 W 个副本上成功,由于 W+R>N,任意 R 个副本组成的集合一定与成功的 W 个副本组成的集合有交集,所以读取 R 个副本一定能读到 wi 更新后的数据 vi。 如图 2-10,Quorum 机制的原理可以文森图表示:
例如:某系统有 5 个副本,W=3,R=3,最初 5 个副本的数据一致,都是 v1,某次更新操作 w2 在前 3 副本上成功,副本情况变成(v2 v2 v2 v1 v1)。此时,任意 3 个副本组成的集合中一定包括v2
在上述定义中,令 W=N,R=1,就得到 WARO,即 WARO 是 Quorum 机制的一种特例
与分析 WARO 相似,分析 Quorum 机制的可用性。限制 Quorum 参数为 W+R=N+1。由于更新操作需要在 W 个副本上都成功,更新操作才能成功,所以一旦 N-W+1 个副本异常,更新操作始终无法在 W 个副本上成功,更新服务不可用。另一方面,一旦 N-R+1 个副本异常,则无法保证一定可以读到与 W 个副本有交集的副本集合,则读服务的一致性下降
例如:N=5, W=2, R=4 时,若 4 个副本异常,更新操作始终无法完成。若 3 个副本异常时,剩下的两个副本虽然可以提供更新服务,但对于读取者而言,在缺乏某些 magic 机制的,即如果读取者不知道当前最新已成功提交的版本是什么的时候,仅仅读取 2 个副本并不能保证一定可以读到最新的已提交的数据
这里再次强调:仅仅依赖 quorum 机制是无法保证强一致性的。因为仅有 quorum 机制时无法确定最新已成功提交的版本号,除非将最新已提交的版本号作为元数据由特定的元数据服务器或元数据集群管理,否则很难确定最新成功提交的版本号。在下一节中,将讨论在哪些情况下,可以仅仅通过 quorum 机制来确定最新成功提交的版本号
Quorum 机制的三个系统参数 N、W、 R 控制了系统的可用性,也是系统对用户的服务承诺:数据最多有 N 个副本,但数据更新成功 W 个副本即返回用户成功。对于一致性要求较高的 Quorum 系统,系统还应该承诺任何时候不读取未成功提交的数据,即读取到的数据都是曾经在 W 个副本上成功的数据
读取最新成功提交的数据
上节中,假设有某种 magic 的机制使得读取者知道当前已提交的数据版本号。本节取消这种假设,分析在 Quorum 机制下,如何始终读取成功提交的数据,以及如何确定最新的已提交的数据
Quorum 机制只需成功更新 N 个副本中的 W 个,在读取 R 个副本时,一定可以读到最新的成功提交的数据。但由于有不成功的更新情况存在,仅仅读取 R 个副本却不一定能确定哪个版本的数据是最新的已提交的数据。对于一个强一致性 Quorum 系统
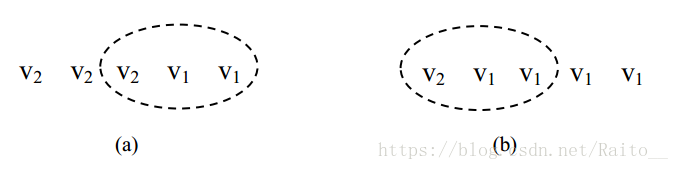
例如:N=5,W=3,R=3 的系统中,某时刻副本最大版本号为(v2 v2 v2 v1 v1)。注意,这里继续假设有 v2 的副本也有 v1,上述列出的只是最大版本号。此时,最新的成功提交的副本应该是 v2,因为从全局看 v2 已经成功更新了 3 个副本。读取任何 3 个副本,一定能读到 v2。但仅读 3 个副本时,有可能读到(v2 v1 v1),如图 2-11(a)。此时,由于 v2 蕴含 v1,可知 v1 是一个成功提交的版本,但却不能判定 v2 一定是一个成功提交的版本。这是因为,图 2-11(b),假设副本最大版本号为(v2 v1 v1 v1 v1),当读取 3 个副本时也可能读到(v2 v1 v1),此时 v2 是一个未成功提交的版本。所以在本例中,仅仅读到(v2 v1 v1)时,可以肯定的是最新的成功提交的数据要么是 v1 要么是 v2,却没办法确定究竟是哪一个
对于一个强一致性系统,应该始终读取返回最新的成功提交的数据,在 quorum 机制下,要达到这一目的需要对读取条件做进一步加强:
- 限制提交的更新操作必须严格递增,即只有在前一个更新操作成功提交后才可以提交后一
个更新操作,从而成功提交的数据版本号必须是连续增加的 - 读取 R 个副本,对于 R 个副本中版本号最高的数据
2.1. 若已存在 W 个,则该数据为最新的成功提交的数据
2.2. 若存在个数据少于 W 个,假设为 X 个,则继续读取其他副本,直若成功读取到 W 个该版本的副本,则该数据为最新的成功提交的数据;如果在所有副本中该数据的个数肯定不满足 W 个,则 R 中版本号第二大的为最新的成功提交的副本
依旧接上面的例子,在读取到(v2 v1 v1)时,继续读取剩余的副本,若读到剩余两个副本为(v2 v2)则 v2 是最新的已提交的副本;若读到剩余的两个副本为(v2 v1)或(v1 v1)则 v1 是最新成功提交的版本;若读取后续两个副本有任一超时或失败,则无法判断哪个版本是最新的成功提交的版本
可以看出,在单纯使用 Quorum 机制时,若要确定最新的成功提交的版本,最多需要读取 R+(W-R-1) =N 个副本,当出现任一副本异常时,读最新的成功提交的版本这一功能都有可能不可用。实际工程中,应该尽量通过其他技术手段,回避通过 Quorum 机制读取最新的成功提交的版本。例如,当 quorum 机制与 primary-secondary 控制协议结合使用时,可以通过读取 primary 的方式读取到最新的已提交的数据
基于 Quorum 机制选择 primary
本节介绍一种基于 quorum 机制选择 primary 的技术。基于 primary-secondary 协议中, primary 负责进行更新操作的同步工作。现在基于 primary-secondary 协议中引入 quorum 机制,即 primary 成功更新 W 个副本(含 primary 本身)后向用户返回成功。读取数据时依照一致性要求的不同可以有不同的做法:如果需要强一致性的立刻读取到最新的成功提交的数据,则可以简单的只读取 primary 副本上的数据即可,也可以通过上节的方式读取;如果需要会话一致性,则可以根据之前已经读到的数据版本号在各个副本上进行选择性读取;如果只需要弱一致性,则可以选择任意副本读取
在 primary-secondary 协议中,当 primary 异常时,需要选择出一个新的 primary,之后 secondary副本与 primary 同步数据。 通常情况下,选择新的 primary 的工作是由某一中心节点完成的,在引入quorum 机制后,常用的 primary 选择方式与读取数据的方式类似,即中心节点读取 R 个副本,选择R 个副本中版本号最高的副本作为新的 primary。新 primary 与至少 W 个副本完成数据同步后作为新的 primary 提供读写服务。首先, R 个副本中版本号最高的副本一定蕴含了最新的成功提交的数据。再者,虽然不能确定最高版本号的数是一个成功提交的数据,但新的 primary 在随后与 secondary 同步数据,使得该版本的副本个数达到 W,从而使得该版本的数据成为成功提交的数据
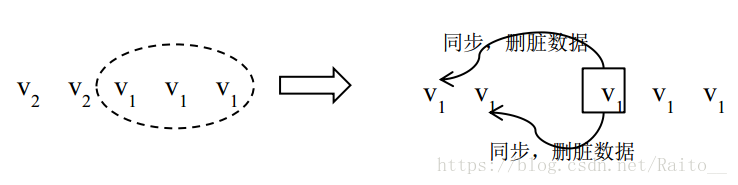
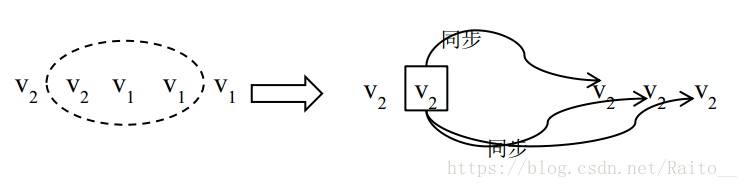
例如:在 N=5,W=3,R=3 的系统中,某时刻副本最大版本号为(v2 v2 v1 v1 v1),此时 v1 是系统的最新的成功提交的数据,v2 是一个处于中间状态的未成功提交的数据。假设此刻原 primary副本异常,中心节点进行 primary 切换工作。这类“中间态”数据究竟作为“脏数据”被删除,还是作为新的数据被同步后成为生效的数据,完全取决于这个数据能否参与新 primary 的选举。下面分别分析这两种情况
第一种:若中心节点与其中 3 个副本通信成功,读取到的版本号为(v1 v1 v1),则任选一个副本作为 primary,新 primary 以 v1 作为最新的成功提交的版本并与其他副本同步,当与第 1、第 2 个副本同步数据时,由于第 1、第 2 个副本版本号大于 primary,属于脏数据,可以按照 2.2.2.4 节中介绍的处理脏数据的方式解决。实践中,新 primary 也有可能与后两个副本完成同步后就提供数据服务,随后自身版本号也更新到 v2,如果系统不能保证之后的 v2 与之前的 v2 完全一样,则新primary 在与第 1、2 个副本同步数据时不但要比较数据版本号还需要比较更新操作的具体内容是否一样
第二种:若中心节点与其他 3 个副本通信成功,读取到的版本号为(v2 v1 v1),则选取版本号为v2 的副本作为新的 primary,之后,一旦新 primary 与其他 2 个副本完成数据同步,则符合 v2 的副本个数达到 W 个,成为最新的成功提交的副本,新 primary 可以提供正常的读写服务
工程投影
| 分布式系统 | Quorum |
|---|---|
| GFS | GFS 使用 WARO 机制读写副本,即如果更新所有副本成功则认为更新成功,一旦更新成功,则可以任意选择一个副本读取数据;如果更新某个副本失败,则更新失败,副本之间处于不一致的状态。GFS 系统不保证异常状态时副本的一致性,GFS 系统需要上层应用通过 Checksum 等机制自行判断数据是否合法。值得注意的是 GFS 中的 append 操作,一旦 append 操作某个 chunck 的副本上失败, GFS 系统会自动新增一个 chunck 并尝试 append 操作,由于可以让新增的 chunck 在正常的机器上创建,从而解决了由于 WARO 造成的系统可用性下降问题。进而在 GFS 中,append 操作不保证一定在文件的结尾进行,由于在新增的 chunk 上重试 append,append 的数据可能会出现多份重复的现象,但每个 append 操作会返回用户最终成功的 offset 位置,在这个位置上,任意读取某个副本一定可以读到写入的数据。这种在新增 chunk 上进行尝试的思路,大大增大了系统的容错能力,提高了系统可用性,是一种非常值得借鉴的设计思路 |
| Dynamo | Dynamo/Cassandra 是一种去中心化的分布式存储系统。 Dynamo 使用 Quorum 机制来管理副本。用户可以配置 N、R、W 的参数,并保证满足 R+W>N 的 quorum 要求。与其他系统的 Quorum 机制类似,更新数据时,至少成功更新 W 个副本返回用户成功,读取数据时至少返回 R 个副本的数据。然而 Dynamo 是一个没有 primary 中的去中心化系统,由于缺乏中心控制,每次更新操作都可能由不同的副本主导,在出现并发更新、系统异常时,其副本的一致性完全无法得到保障。下面着重分析 Dynamo 在异常时副本的一致性情况。首先, Dynamo 使用一致性哈希分布数据,理论上,即使出现一个节点异常,更新操作也可以顺着一致性哈希环的顺序找到 N 个节点完成。不过,这里我们简化其模型,认为始终只有初始的 N 个副本,在实际中可以等效为网络异常造成用户只能和初始的 N 个副本通信。更复杂的是,虽然可以沿哈希环找到下一个节点临时加入,但无法解决异常节点又重新加入的问题,所以这里的这种简化模型是完全合理的。我们通过一个例子来考察Dynamo 的一致性。例如:在 Dynamo 系统中,N=3,R=2,W=2,初始时,数据 3 个副本(A、B、C)上的数据一致,这里假设数据值都为 1,即(1,1,1)。某次更新操作需在原有数据的基础上增加新数据,这里假设为+1 操作,该操作由副本 A 主导,副本 A 成功更新自己及副本 C,由于异常,更新副本 B 失败,由于已经满足 W=2 的要求,返回用户更新成功。此时 3 个副本上的数据分别为(2,1,2)。接着,进行新的更新操作,该操作需要在原有数据的基础上增加新数据,假设为+2 操作,假设用户端由于异常联系副本 A 失败,联系副本 B 成功,本次更新操作由副本 B 主导,副本 B 读取本地数据 1,完成加 2 操作后同步给其他副本,假设同步副本 C 成功,此时满足 W=2 的要求,返回用户更新成功。此时 3 个副本上的数据分别为(2, 3, 3)。这里需要说明的是在 Dynamo 中,副本 C 必须要接受副本 B 发过来的更新并覆盖自身数据,即使从全局角度说该更新与副本 C 上的已有数据是冲突的,但副本 C 自身无法判断自己的数据是否有效。假如第一次副本 A 主导的更新只在副本 C 上成功,那么此时副本 C 上的数据本身就是错误的脏数据,被副本 B 主导的这次更新覆盖也是完全应该的。最后,用户读取数据,假设成功读取副本 A 及副本 B 上的数据,满足 R=2 的需求,用户将拿到两个完全不一致的数据 2 与 3,Dynamo 将解决这种不一致的情况留给了用户进行。为了帮助用户解决这种不一致的情况,Dynamo 提出了一种 clock vector 的方法,该方法的思路就是记录数据的版本变化,以类似 MVCC(2.7 )的方式帮助用户解决数据冲突。所谓 clock vector即记录了数据变化的路径的向量,为每个更新操作维护分配一个向量元素,记录数据的版本号及主导该次更新的副本名字。接着例 2.4.7 来介绍 clock vector 的过程。例如:在 Dynamo 系统中,N=3,R=2,W=2,初始时,数据 3 个副本(A、B、C)上的数据一致,这里假设数据值都为 1,即(1,1,1),此时三个副本的 clock vector 都为空([], [], [])。某次更新操作需在原有数据的基础上增加新数据,这里假设为+1 操作,该操作由副本 A 主导,副本 A 成功更新自己及副本 C,返回用户更新成功。此时 3 个副本上的数据分别为(2,1,2),而三个副本的 clock vector 为([(1, A)], [], [(1, A)]),A、C 的 clock vector 表示数据版本号为 1,更新是有副本 A 主导的。接着,进行新的更新操作,该操作需要在原有数据的基础上增加新数据,假设为+2 操作,假设本次更新操作由副本 B 主导,副本 B 读取本地数据 1,完成加 2 操作后同步给其他副本,假设同步副本 C 成功,。此时 3 个副本上的数据分别为(2, 3, 3),此时三个副本的 clock vector 为([(1, A)], [(1, B)], [(1, B)])。为了说明 clock vector,这里再加入一次+3 操作,并由副本 A 主导,更新副本 A 及副本 C 成功,此时数据为(5, 3, 5),此时三个副本的 clock vector 为([(2, A), (1, A)], [(1, B)], [(2, A), (1, A)])。最后,用户读取数据,假设成功读取副本 A 及副本 B 上的数据,得到两个完全不一致的数据 5与 3,及这两个数据的版本信息[(2, A), (1, A)], [(1, B)]。用户可以根据自定义的策略进行合并,例如假设用户判断出,其实这些加法操作可以合并,那么最终的数据应该是 7,又例如用户可以选择保留一个数据例如 5 作为自己的数据。由于提供了 clock vector 信息,不一致的数据其实成为了多版本数据,用户可以通过自定义策略选择合并这些多版本数据。Dynamo 建议可以简单的按照数据更新的时间戳进行合并,即用数据时间戳较新的数据替代较旧的数据。如果是简单的覆盖写操作,例如设置某个用户属性,这样的策略是有效且正确的。然而类似上例中这类并发的加法操作(例如“向购物车中增加商品”),简单的用新数据替代旧数据的方式就是不正确的,会造成数据丢失 |
| Zookeeper | Zookeeper 使用的 paxos 协议本身就是利用了 Quorum 机制,在后面中有详细分析,这里不赘述。当利用 paxos 协议外选出 primary 后,Zookeeper 的更新流量由 primary 节点控制,每次更新操作,primary 节点只需更新超过半数(含自身)的节点后就返回用户成功。每次更新操作都会递增各个节点的版本号(xzid)。当 primary 节点异常,利用 paxos 协议选举新的 primary 时,每个节点都会以自己的版本号发起 paxos 提议,从而保证了选出的新 primary 是某个超过半数副本集合中版本号最大的副本。新 primary 的版本号未必是一个最新已提交的版本,可能是一个只更新了少于半数副本的中间态的更新版本,此时新primary 完成与超过半数的副本同步后,这个版本的数据自动满足 quorum 的半数要求;另一方面,新 primary 的版本可能是一个最新已提交的版本,但可能会存在其他副本没有参与选举但持有一个大于新 primary 的版本号的数据(中间态版本),此时这样的中间态版本数据将被认为是脏数据,在与新 primary 进行数据同步时被 zookeeper 丢弃 |
| Mola*/Armor* | Mola和 Armor系统中所有的副本管理都是基于 Quorum,即数据在多数副本上更新成功则认为成功。Mola 系统的读取通常不关注强一致性,而提供最终一致性。对于 Armor*,可以通过读取副本版本号的方式,按 Quorum 规则判断最新已提交的版本。由于每次读数据都需要读取版本号,降低了系统系统性能,Doris系统在读取 Armor数据时采用了一种优化思路:由于Doris系统的数据是批量更新,Doris维护了 Armor副本的版本号,并只在每批数据更新完成后再刷新 Armor副本的版本号,从而大大减少了读取 Armor*副本版本号的开销 |
| Big Pipe* | Big Pipe中的副本管理也是采用了 WARO 机制。值得一提的是,Big Pipe 利用了 zookeeper 的高可用性解决了 WARO 在更新失败时副本的不一致的难题。当更新操作失败时,每个副本都会尝试将自己的最后一条更新操作写入 zookeeper。但最多只有一个副本能写入成功,如果副本发现之前已经有副本写入成功后则放弃写入,并以 zookeeper 中的记录为准与自身的数据进行同步。另一方面,与 GFS 更新失败后新建 chunck 类似,当 Big Pipe更新失败后,会将更新切换到另一组副本,这组副本首先读取 zookeeper 上的最后一条记录,并从这条更新记录之后继续提供服务。例如,一共有 3 个副本 A、B、C,某次更新操作在 A、B 上成功,各副本上的数据为(2,2,1),此时 3 个副本一旦探测出异常,都会尝试向 zookeeper 写入最后的记录。如果 A 或 B 写入成功,则意味着最后一次的更新操作成功,副本 C 会尝试同步到这条更新,新切换的副本组也会在数据 2的基础上继续提供服务。如果 C 写入成功,则相当于最后一次更新失败,当副本 A、 B 读到 zookeeper上的信息后会将最后一个更新操作作为“脏数据”并回退掉最后一个更新操作,新切换的副本组也只会在数据 1 的基础上继续提供服务。从这里不难看出,当出现更新失败时,Big Pipe*中这条中间态数据的命运完全取决于是哪个副本抢先完成写 zookeeper 的过程 |