机器学习的定义:假设用P来评估计算机程序在某任务类T上的性能,若一个程序通过利用经验E,使其在T中任务获得了性能改善,我们则说关于任务类T和P,该程序对经验E进行了学习(Mitchell, 1997)。
机器学习的研究内容:关于在计算机上从数据中产生模型的算法,即学习算法(learning algorithm)。
1.名词定义
数据集 (Data set):数据的集合,其中每条数据都称为一条样本 (Sample)或示例 (Instance)。即:
样本 (Sample) = 示例 (Instance)
属性 (Attribute) = 特征 (Feature)
属性空间 (Attribute space) = 样本空间 (Sample space) = 输入空间 (Input space)
E.g. 如图所示,若某数据集中的数据拥有三种属性,则可以看作是三维空间内对应坐标的点。而该坐标张成的空间即为属性空间。
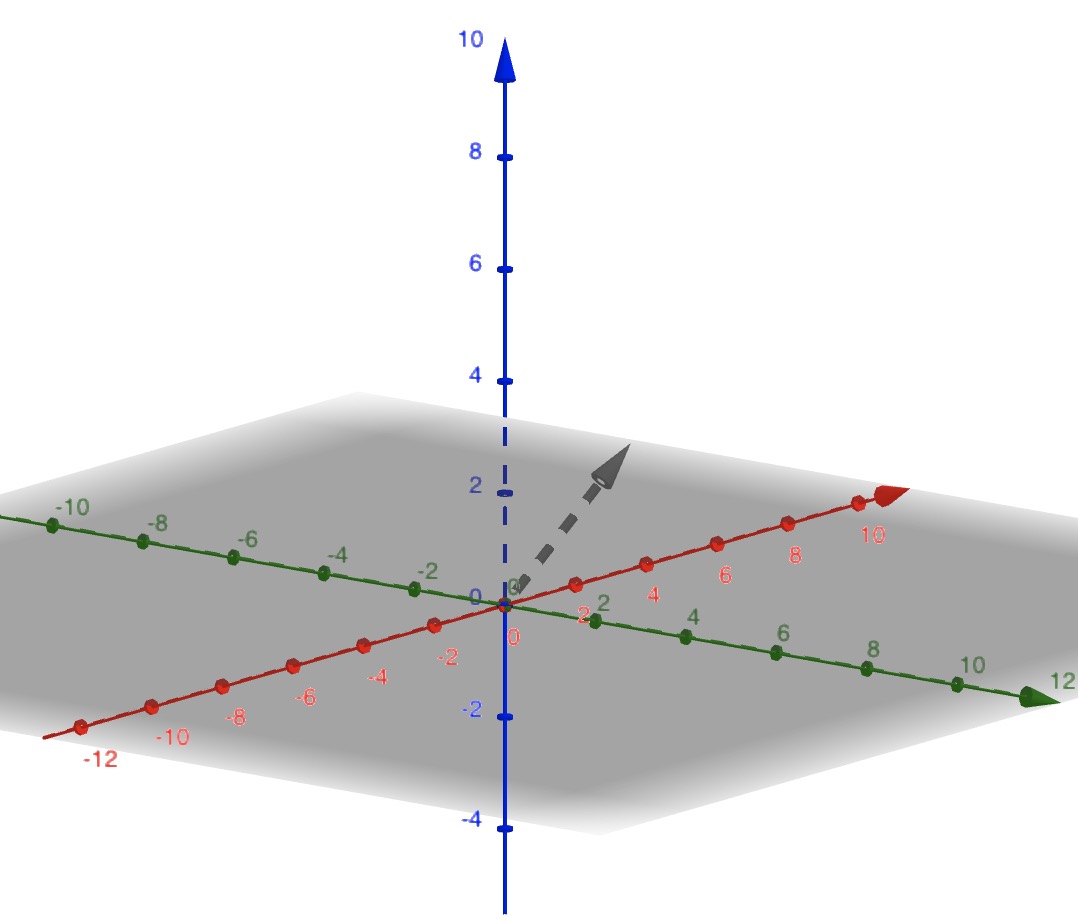
即:数据集 D = {x1, x2, ......, xm}, 其中,样本 x = {x11, x22, ......, x1d},d为该条数据的维数(属性或特征的个数),xij 则是第 i 条数据中第 j 条属性或特征的值。
学习 (Learning) / 训练 (Training):从数据中学得模型的过程。
训练数据 (Training data):训练过程中使用的数据,其中的每个样本称为一个训练样本。
训练集 (Training set):训练样本所组成的集合。
标记 (Label):关于样本结果的信息。
样例 (Example):拥有标记的样本/示例即样例。即:
示例 (Instance) / 样本 (Sample) + 标记 (Label) = 样例 (Example)
(xi, yi)
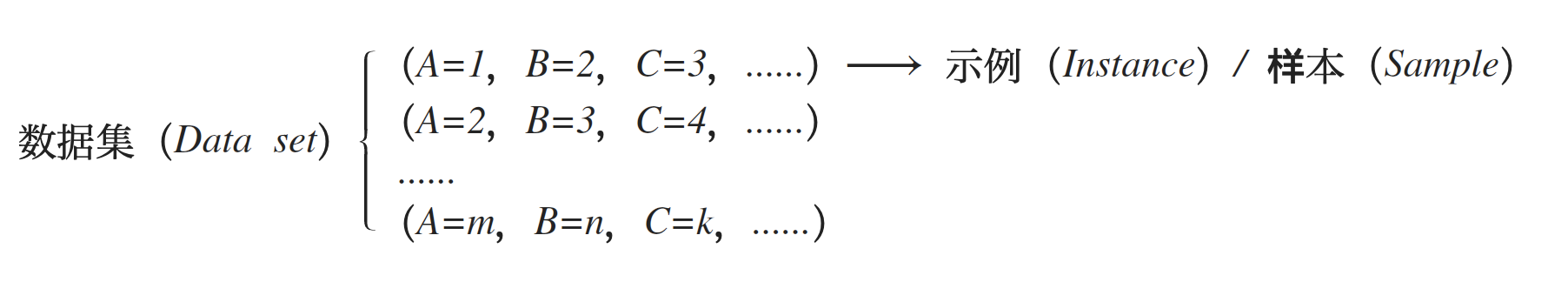
测试 (Testing):使用学得的模型进行预测的过程。
测试集 (Testing Set):测试样本所组成的集合,应尽量与训练集互斥。
泛化 (Generalization):学得的模型适用于新样本的能力。
独立同分布 (Independent and identically distributed, i.i.d):假设样本空间中的全体样本服从一个未知的分布D,我们获得的每个样本都是独立地从这个分布上采样获得的,这也是统计机器学习算法的基本依据。
奥卡姆剃刀 (Occam's razor):如果有多个假设与观察一致,则选取最简单的那个。
“没有免费的午餐”定理(No Free Lunch Theorem, NFL):无论学习算法 Σa 多聪明,学习算法Σb多笨拙,它们的期望性能是相同的。
2. 分类、回归
根据预测任务中预测的值类型的不同:

根据是否拥有标记 (Label):
