文件是操作系统中的一个虚拟概念。文件是以计算机硬盘为载体存储在计算机上的信息集合,文件可以是文本文档、图片、程序,等等。在系统运行时,计算机以进程为基本单位进行资源的调度和分配;而在用户进行的输入、输出中,则以文件为基本单位。大多数应用程序的输入都是通过文件来实现的。
在初期编写程序时,接触最多的是文本文件,比如,在注册和登录功能中,用户名和密码要存储在文件里,python程序也是写成文本文件的形式。
执行一个python文件的过程:
• Cpython解释器加载到内存
• py文件从硬盘加载到内存
• Cpython解释器向CPU发出指令,处理py文件,逐行识别文本的语法
打开一个文本文档的过程:
• 1 •启动文本编辑器(程序加载到内存),开始编辑,编辑时我们看到即时输入的内容是存在了内存
• 2 •在输入→显示的过程中,涉及到中文字符→二进制→中文字符的过程
• 3 •写完保存,编辑器把内存中的数据保存到硬盘
首先来讨论一下• 2 •,字符→二进制→字符的过程,就是编码(encode)(输入),解码(decode)(输出),的过程。
最开始计算机出现,只在英文环境里使用,所以编码解码只考虑英文字符和二进制,具体用哪些二进制数字表示哪个符号,经最早的这批人达成一致,这就是ASCII码。
后来计算机普及,每个国家都产生了自己的语言与二进制的对应标准,比如中国的GBK,因为各个国家不统一,导致了这样的问题:汉语国家编写的软件,在其他语系国家里不能使用,因为他们的计算机中没有汉语字符与二进制的对照关系!为了解决这样的问题,各国统一,unicode码诞生了,它将很多国家的字符与二进制的关系都包含在内,统一使用16位二进制数字表示各国字符。
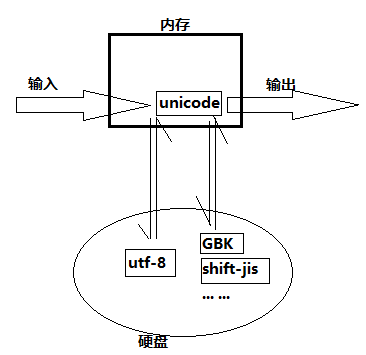
结果就是,我们在自己的电脑文本编辑器里输入一个日文字符,编码到内存,显示(输出)的时候,这16位二进制数字会解码成日文,显示出来,而不会出现乱码的问题。
可是再后来,使用计算机的过程中,又发现了新问题:在英语系国家的编程者发现,原来采用ASCII码,用8位二进制表示字符,而现在需要16位,输入的数据存入硬盘的时间几乎长了一倍!为了解决这样的问题,又出现了UTF-8(8-bit Unicode Transformation Format),这是一种针对Unicode的可变长度字符编码,它会识别unicode编码的二进制表示的字符是什么语言的字符,并分配不同的字节,比如,如果是英文,就用1个字节存储到硬盘,如果是中文,就用3个字节存到硬盘...这是• 3 •的过程
有了UTF-8之后,只要我们写一个文件,保存成utf-8编码格式,在任何国家的电脑上也能通用,而且占的空间更小,存取更快!是不是觉得,utf-8可以完全取代unicode了!理论上的确是这样,但这里又存在一个历史遗留问题了,在这之前,很多国家都用自己国家的编码标准编写了软件,而utf-8里只有与unicode 一 一对应的关系,并没有直接和GBK,shift-jis等标准建立联系,所以直至现在,我们的计算机内存采用的,仍然是unicode.就像python3刚推出,而很多python2的软件都不能用python3运行,导致很多公司和个人拒绝使用python3,于是龟叔迫不得已推出python2.7一样,我们需要unicode来作为阶段性的过渡。
但是如果以后每个人写文件,都采用utf-8格式保存,等足够长的时间后,就可以废弃unicode标准了,也就不会存在因为编码解码而导致的程序报错和乱码问题!!
这张图可以帮助你理解编码、解码的过程和乱码、报错的原因: