现代社会提到大数据大家都知道这是近几年才形成的对于数据相关的新名词,在1980年,著名未来学家阿尔文·托夫勒便在 《第三次浪潮》一书中,将大数据热情地赞颂为“第三次浪潮的 华彩乐章”。在 20 世纪 80 年代我国已经有一些专家学者谈到了海量数据的加工和管理,但是由于计算机技术和网络技术的限制大数据未能引起足够的重视,它蕴藏的巨大信息资源也暂时隐藏了起来。随着云计算技术的发展,互联网的应用越来越广泛,以微博和博客为代表的新型社交网络的出现和快速发展,以及以智能手机、平板电脑为代表的新型移动设备的出现, 计算机应用产生的数据量呈现了爆炸性增长的趋势。2012年末出版的《大数据时代》的作者英国牛津大学网络学院互联网 研究所治理与监管专业教授维克托·尔耶·舍恩伯格在书的引言中说,大数据正在改变人们的生活以及理解世界的方式,而更多的改变正蓄势待发。
大数据蕴含着巨大的价值,对社会、经济、科学研究等各个方面都具有重要的战略意义。目前,大数据已经在政府公共管理、医疗服务、零售业、制造业,以及涉及个人的位置服务等领域得到了广泛应用,并产生了巨大的社会价值和产业空间。麦肯锡公司在一份研究报告中,根据西方产业数据预测,大数据的应用将能为欧洲发达国家的政府节省1000亿欧元以上的运作成本,使美国医疗保健行业的成本降低8%,约每年3000多亿美元,并使得零售商的营业利润率提高60%以上。市场调研机构IDC的“数字宇宙”研究报告中则预测,大数据技术与服务市场在2015年将达到169亿美元,实现40%的年增长率,为IT与通信产业增长率的7倍。大数据中蕴含的巨大商业价值、科学研究价值、社会管理与公共服务价值以及支撑科学决策的价值正在被认知与开发利用。
数据中蕴含的宝贵价值成为人们存储和处理大数据的驱动力。Mayer-Schonberger 在《大数据时代》一书中指出了大数据时代处理数据理念的三大转变,即要全体不要抽样,要效率不要绝对精确,要相关不要因果。因此,大数据的处理对于当前存在的技术来说是一种极大的挑战。
那么我们如何获取这些数据呢,有没有什么高效的办法可以帮助我们获取这些高价值的数据,毕竟人工的复制黏贴不仅复杂而且非常的低效,因此后羿工程师团队不断的摸索和开发,终于研究出一款基于人工智能技术的爬虫工具,只需要在软件中输入网址就能够自动识别网页数据,无需配置即可完成数据采集,是业内首家支持三种操作系统(包括Windows、Mac和Linux)的采集软件。同时这是一款真正免费的数据采集软件,对采集结果导出没有任何限制,即使是没有编程基础的小白用户也可轻松实现数据采集要求。
现在我们就以腾讯视频为例,为大家演示如何使用此款软件。
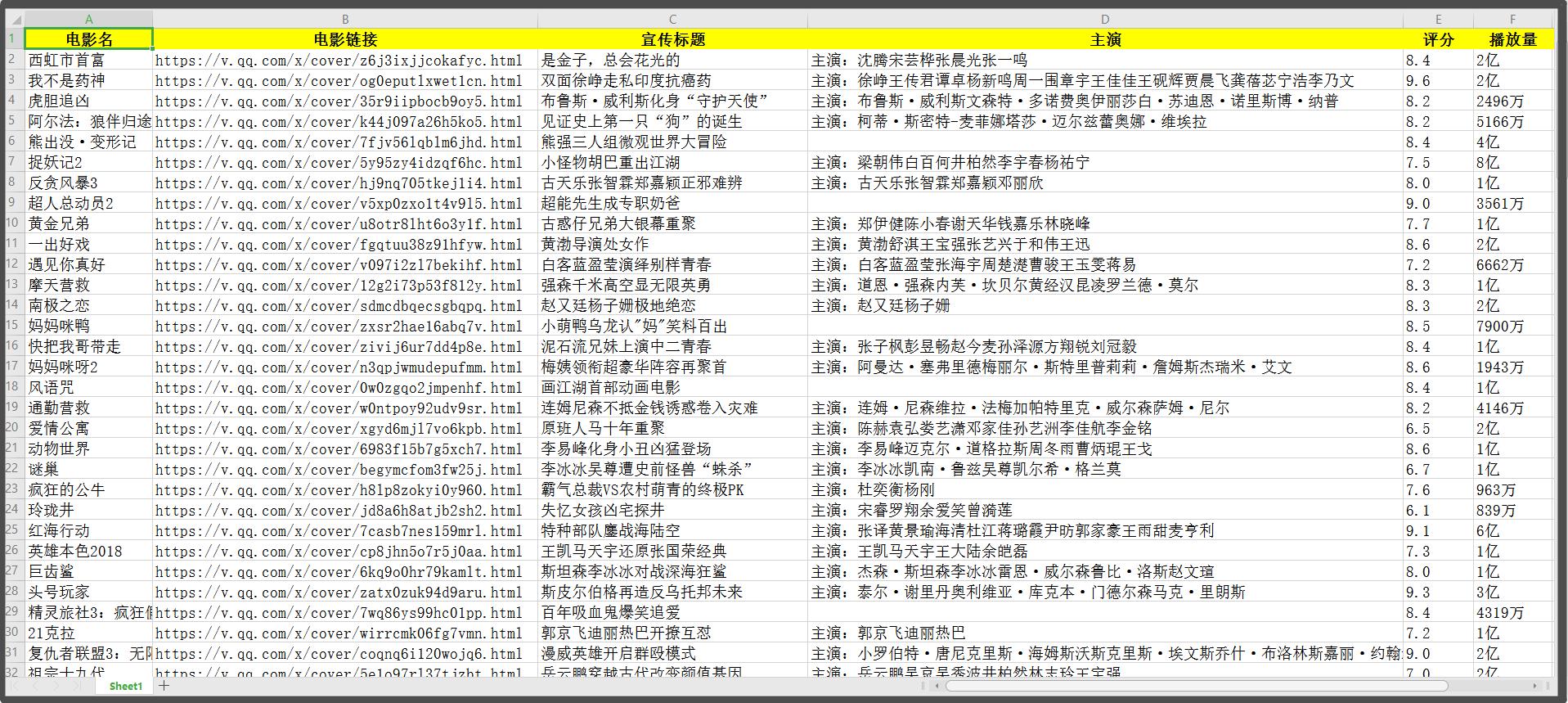
首先,复制需要采集的网址,打开软件输入网址,新建智能采集任务。

在智能模式下,我们输入网址后软件即可自动识别出页面上的数据并生成采集结果,每一类数据对应一个采集字段,我们可以右击字段进行相关设置,包括修改字段名称、增减字段、处理数据等。

接着我们点击“保存并启动”按钮,可在弹出的页面中进行一些高级设置,包括定时启动、自动入库和下载图片,本次示例中未使用到这些功能,直接点击“启动”运行爬虫工具。
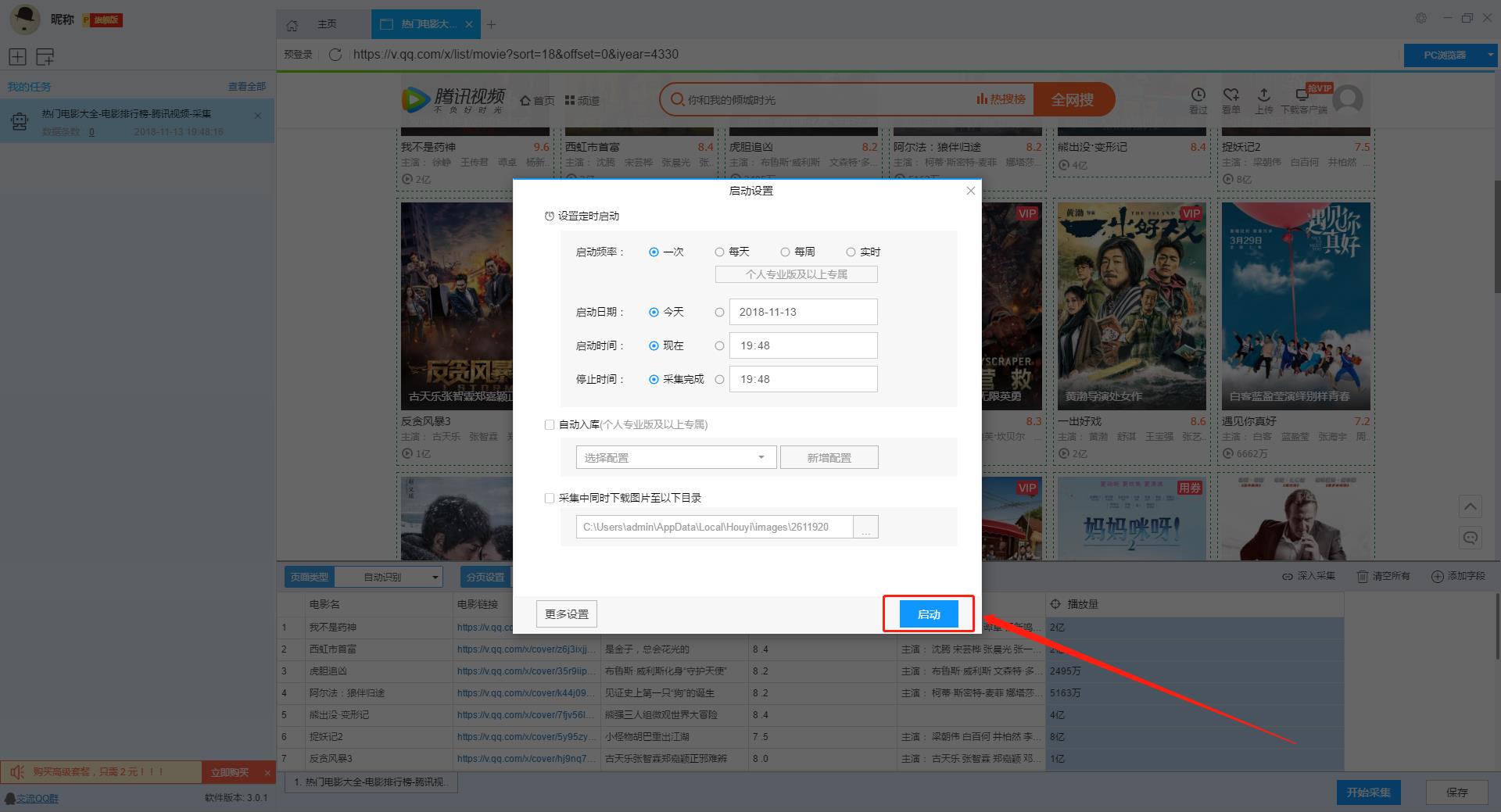

数据采集完毕后,我们可以导出数据,软件提供多种导出方式,大家可以自由选择导出方式。
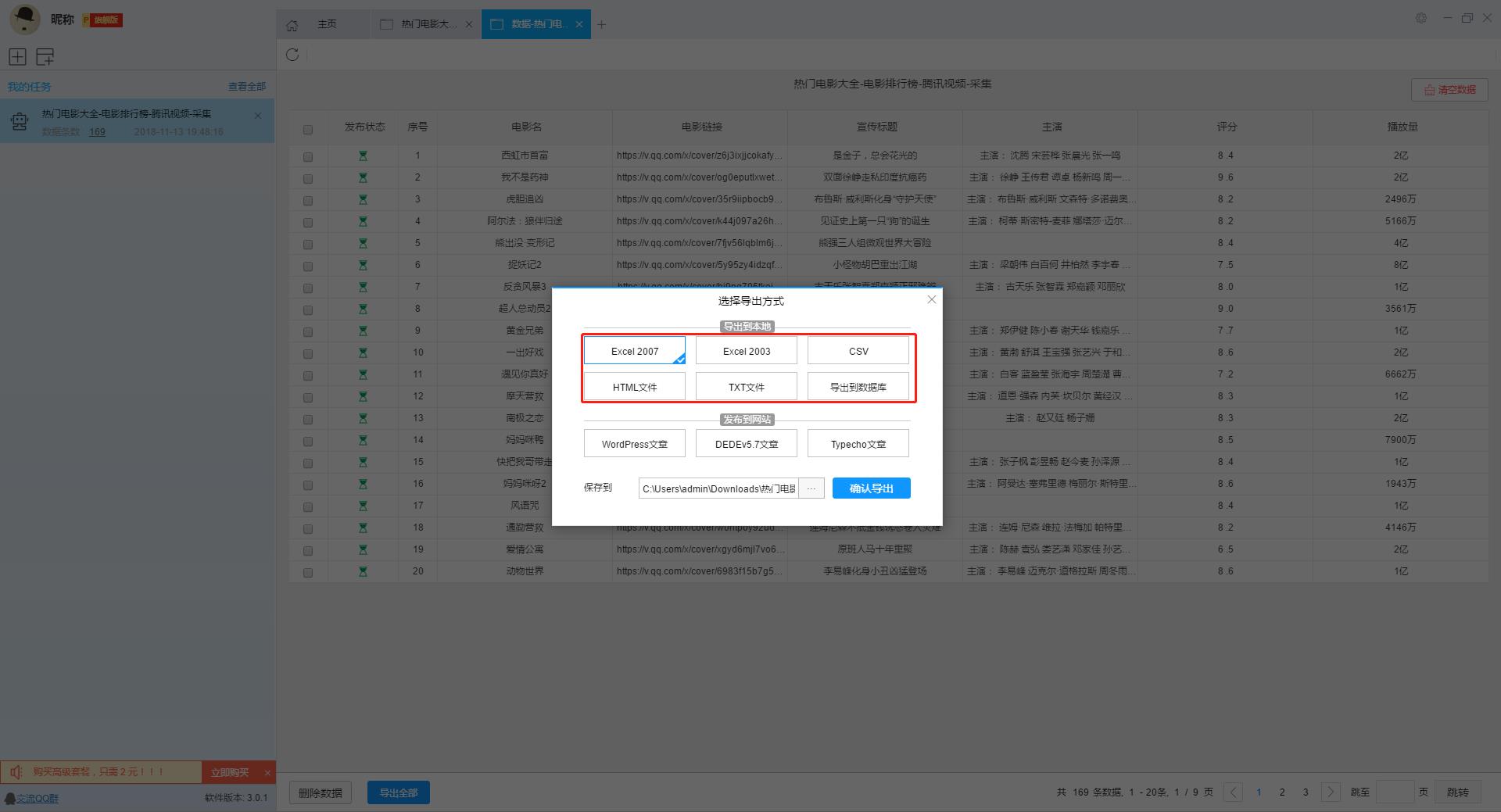
我们导出了一个Excel表格的文件,在这个表格上我们可以看到数据都完整的采集出来了,大家可以直接使用这些数据,也可以在这个基础上对数据进行加工处理。