1、如何理解"队列"?
类比栈,栈只支持两个基本操作:入栈push()和出栈pop()。对于队列的基本操作也只有两个:入队enqueue(),放一个数据到队列尾部;出队dequeue(),从队列头部去一个元素。(如下图)

2、顺序队列和循环队列
用数组实现的队列叫做顺序队列,用链表实现的队列叫做链式队列。队列具有先进先出的特性,支持在队尾插入元素,在队头删除元素。
(1)、 顺序队列
那究竟如何实现一个队列?我们先来看下基于数组的实现方法(Java语言)

那么队列是如何实现的?请继续往下看
对于栈来说,我孟只需要一个栈顶指针就可以。但是队列需要两个指针:一个是head指针,指向队头;一个是tail指针,指向队尾。
当a,b,c,d依次入队列之后,队列中head指针指向下标为0的位置,tail指针指向下标为4的位置。(如下图)

当我们调用两次出对操作之后,队列中的head指针指向下标为2的位置,tail指针仍然指向下标为4的位置。
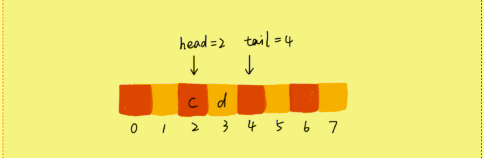
随着不停地进行入队、出队操作,head和tail都会持续往后移动。当tail移动到最右边,即使数组中还有空闲空间,也无法继续往队列中添加数据了。那么怎么解决呢?
类比数组的删除操作会导致数组中的数据不连续,我们将数据搬移。但是,每次进行出队操作都相当于删除数组下标为0的数据,要搬移整个队列中的数据,这样出队操作的时间复杂度就会从原来的O(1)变为O(n).
优化一下,实际上我们在出队时可以不用搬移数据。如果没有空闲空间了,我们只需要在入队时,再集中触发一次数据的搬移操作。借助这个思想,出对函数dequeue()保持不变,我们稍加改造一下入队函数enqueue()的实现,就可以解决。(如下图)

从代码中我们看到,当队列的tail指针移动到数组的最右边后,如果有新的数据入队,我们可以将head到tail之间的数据,整体搬移到数组中0到tail-head的位置。

这种实现思路中,出队操作的时间复杂度仍然是O(1)。
基于链表的队列实现方法。
基于链表的实现我们同样需要两个指针:head指针和tail指针。他们分别指向链表的第一个结点和最后一个结点。(如图所示),入队时,tail->next=new_node,tail->next;出队时,head=head->next。

(2)、循环队列
循环队列,顾名思义,它长得像环。原本数组是有头有尾,是一条直线。现在我们把首尾相连,掰成了一个环。(如下图)

我们可以看到,图中这个队列得大小为8,当前head=4,tail=7。但有一个新的元素入队时,我们放入下标为7的位置。但这个时候,我们并不把tail更新为8,而是将其在环中后移一位,到了下标为0的位置。再当有一个元素b入队时,我们将b放入下标为0的位置,然后tail加1更新为1。所以,在a,b 依次入队后,循环队列中的元素就变成了下面的样子:
通过这种方法,我们成功避免了数据搬移操作。看起来不难理解,但是循环队列的代码实现难度要比前面讲的非循环队列难得多。要想写出没有bug的循环队列的实现代码,我个人觉得,最关键的是,确定好队空和队满的判定条件。
对于队列的队空判断条件仍然是head==tail。但队列满的判断条件就稍微有点复杂。下图为一张队列满的图:
如图中画的队列满的情况,tail=3,head=4,n=8,所以总结一下规律就是:(3+1)%8=4。多画几张队满的图,你就会发现,但队满时,(tail+1)%n=head。
如图所示,但队列满时,图中的tail指向的位置实际上是没有存储数据的。所以循环队列会浪费一个数组的存储空间。
下面是实现的代码(如下图)

3、组塞队列和并发队列
阻塞队列其实就是在队列基础上增加了阻塞操作。简单来说,就是在队列为空的时候,从头取数据会被阻塞。因为此时还没有数据可取,直到队列中有了数据才能返回;如果队列满了,那么插入数据的数据操作就会被阻塞,直到队列中有空闲位置后再插入数据,然后再返回。

上述的定义就是一个“生产者-消费者模型”!是的,我们可以使用阻塞队列,轻松实现一个“生产者-消费者模型”!
这种基于阻塞队列实现的“生产者-消费者模型”,可以有效地协调生产和消费的速度。当“生产者”生产数据的速度多快,“消费者”来不及消费时,存储数据的队列就会很满了。这个时候生产者就阻塞等待,直到“消费者”消费了数据,“生产者”才会被唤醒继续“生产“。
而且不仅如此,基于阻塞队列,我们还可以通过协调“生产者”和“消费者”的个数来提高数据的处理效率。比如前面的例子,我们可以配置几个”消费者“,来对应一个”生产者“。

在多线程情况下,会有多个线程同时操作队列,这个时候就会存在线程安全问题,那如何实现一个线程安全的队列?
线程安全的队列我们叫做并发队列。最简单直接的方式是直接在enqueue ()、dequeue()方法上加锁,但是锁粒度大并发度会比较低,同一时刻仅允许一个存或者取操作。实际上,基于数组的循环队列,利用CAS原子操作,可以实现非常高的并发队列。这也是循环队列比链式队列应用更加广泛的原因。
4、问题:
当我们向固定大小的线程池中请求一个线程时,如果线程中没有空闲的资源了,这个时候线程池如何处理这个请求?是拒绝请求还是排队,各种处理策略又是怎么实现的呢?
我们一般有两种处理策略。第一种是非阻赛的处理方式,直接拒绝任务请求;另一种是阻塞的处理方式,将请求排队列,等到有空闲线程时,取出排队的请求继续处理。
那如何存储排队的请求?
我们希望公平地处理每个排队的请求,先进者先服务,所以队列这种数据结构很适合来存储排队请求。我们前面说过,队列有基于链表和数组这两种实现方式,那么这两种实现方式对于排队请求又有什么区别呢?
基于链表的实现方式,可以实现一个支持无限排队的无界队列,但是可能会导致过多的请求排队等候,请求响应的时间过长。所以针对响应时间比较敏感的系统,基于链表实现的无限循环排队的线程池是不合适的。
而基于数组实现的有界队列,队列的大小有限,所以线程池中排队的请求超过队列大小时,接下来的请求就会被拒绝,这种方式对响应时间敏感的系统来说,就相对更加合理。不过,设置一个合理的队列大小,也是非常有讲究的队列太大导致等待的请求太多,队列太小会导致无法充分利用资源、发挥最大性能。
除了前面讲到队列应用在线程池请求排场的场景之外,队列可以应用在任何有限资源池中,用于排队请求,比如数据库连接池等。实际上,对于大部分资源有限的场景,但没有空闲资源时,基本上都可以通过“队列”这种数据结构来实现请求排队。
欢迎大家扫码关注微信公众号,其中含有有大量免费的人工智能、图像处理、IT资料:

Change,There is no better way !