论文链接,至于论文我没仔细看,我只学习了其框架。
但是需要注意的是:
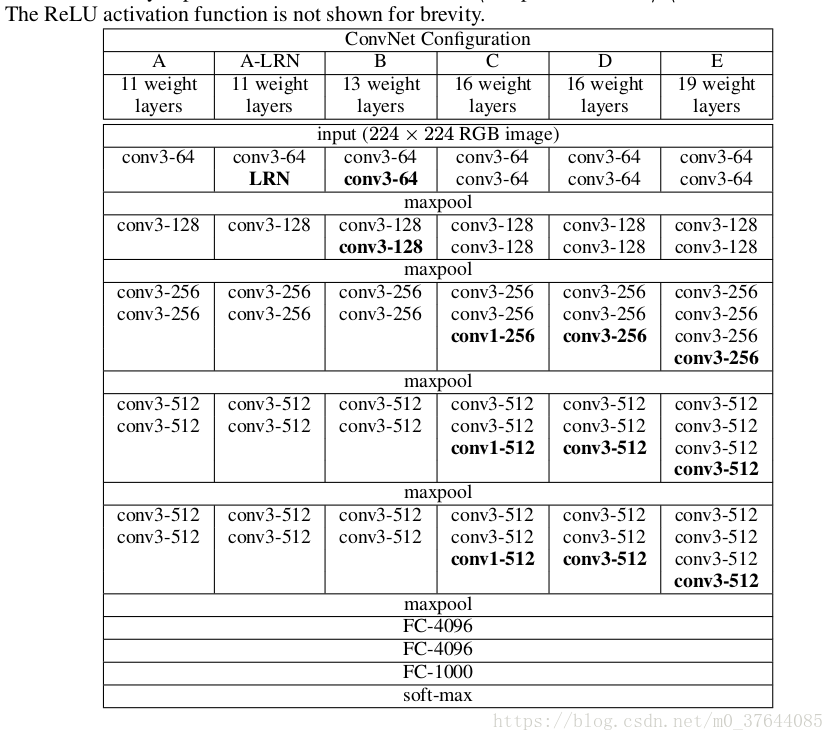
在训练期间,ConvNets的输入是固定大小的224×224 RGB图像。 唯一预处理是从每个像素中减去在训练集上计算的平均RGB值,(eg:VGG16是:VGG_MEAN = tf.constant([123.68, 116.779, 103.939], dtype=tf.float32))处理时候转换成了RGB→BGR格式。图像通过一堆卷积(转换)层,使用具有非常小的感知域的滤波器: 3×3(这是捕捉左/右,上/下,中心概念的最小尺寸)。 在其中一种配置中,我们还使用1×1卷积滤波器,可以看作是输入通道的线性变换(后面是非线性)。 卷积步幅固定为1个像素; 卷积层输入的空间填充使得在卷积之后保持空间分辨率,即对于3×3个卷积层,填充是1个像素。 空间池由五个最大池组执行,这些层跟随一些转换。 图层(并非所有转换图层都跟随最大池)。 最大池化在2×2像素窗口上执行,步幅为2。
卷积层(在不同的体系结构中具有不同的深度)的stack之后是三个完全连接(FC)层:前两个层各有4096个通道,第三个层执行1000路ILSVRC分类,因此包含1000个通道(每个类一个)。最后一层是soft-max层。在所有网络中,完全连接层的配置是相同的。所有隐藏层都具有整流(ReLU)非线性特性。网络(除了一个)都不包含本地响应规范化(LRN)规范化,因为作者尝试了这种规范化不会提高ILSVRC数据集的性能,但会增加内存消耗和计算时间。
The convolutional layer parameters are denoted as “conv receptive field size - number of channels ”
vgg有五种模型:ABCDE,D就是VGG16,E就是VGG19。19层数的计算是conv层+FC。
卷积:conv:f=3*3,s=1*1,p=1*1;Maxpool: f=2*2,s=2*2,p=0
卷积核:是每stack层卷积核的个数由首阶段64,逐层增一倍至512

1.error:tensorflow.python.framework.errors_impl.ResourceExhaustedError: OOM when allocating tensor with shape[64,147,147,64]
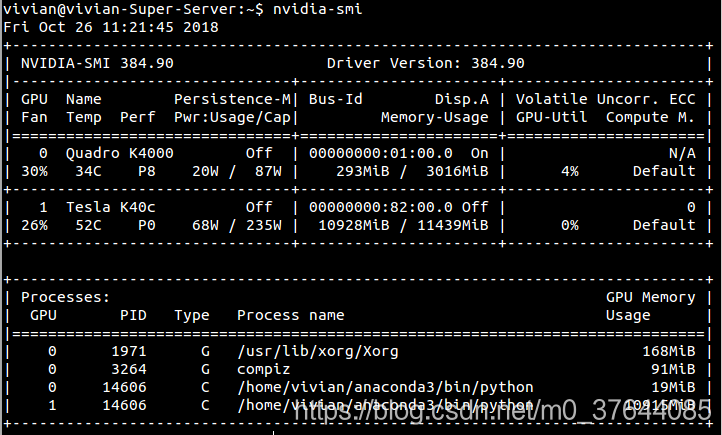
出现以上类似的错误,如有多块GPU,首先考虑是不是GPU指定问题,仔细看程序开始地方用的是哪个GPU,比如Creating TensorFlow device (/gpu:0) -> (device: 0, name: Tesla K40c, pci bus id: 0000:82:00.0)

我这里是Tesla,因为在代码开头添加如下:设置为0或者1也可以,但由于有时候没用,故建议写其ID,
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0000:82:00.0"
#os.environ["CUDA_VISIBLE_DEVICES"] = "0,1"可在终端输入:nivida-smi查看。中间是其Id,可看到是否使用:On,off
还可能因为模型中的batch_size值设置过大,导致内存溢出,batch_size是每次送入模型中的值,由于GPU的关系,一般设为16,32,64,128。