Jedis基本用法:
连接池建立-〉访问密码设置-〉连接超时等参数设置
详看 cacheDemo的JedisUtils工具类
pom.xml引入以下依赖即可
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
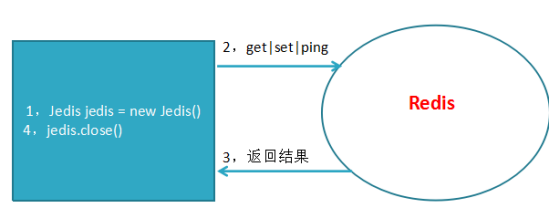
</dependency>1.jedis直接连接redis如下:
2,使用连接池方式
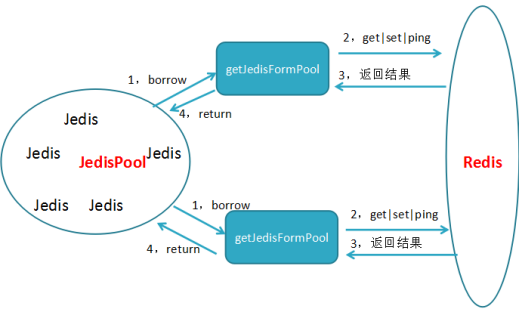
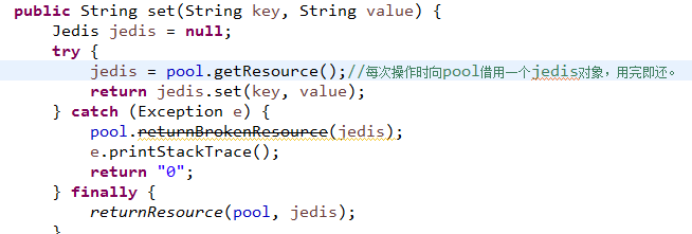
生产环境一般使用连接池进行操作,jedis连接redis对象放在连接池里,每次用的时候去POOL借用,用完后归还
序列化与反序列化
指把结构化的对象变成无结构的字节流,便于存储、传输,保持一个类在传递数据的有序性,使接收到的数据更具有保证,而反序列化是利用类成员变量反射成为一个类
(即把对象序列化后存redis, 从redis取值后反序列化为JAVA对象)
序列化的工具依赖包
<dependency>
<groupId>com.dyuproject.protostuff</groupId>
<artifactId>protostuff-runtime</artifactId>
<version>1.1.3</version>
</dependency>
<dependency>
<groupId>com.dyuproject.protostuff</groupId>
<artifactId>protostuff-core</artifactId>
<version>1.1.3</version>
</dependency>实例:见cache-demo的SerializerTest测试用例
Jedis中的pipeline使用方式
大家知道redis提供了mset、mget方法,但没有提供mdel方法,
如果想实现,可以借助pipeline实现,详见cache-demo, 看JedisAllCommandTest用例testPipelineMdel方法
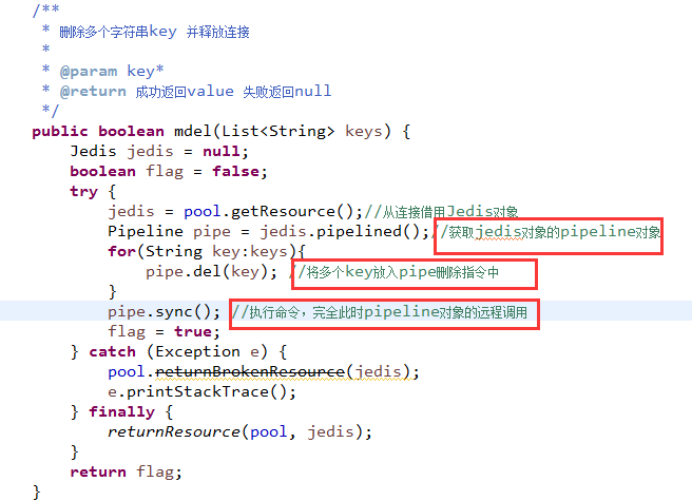
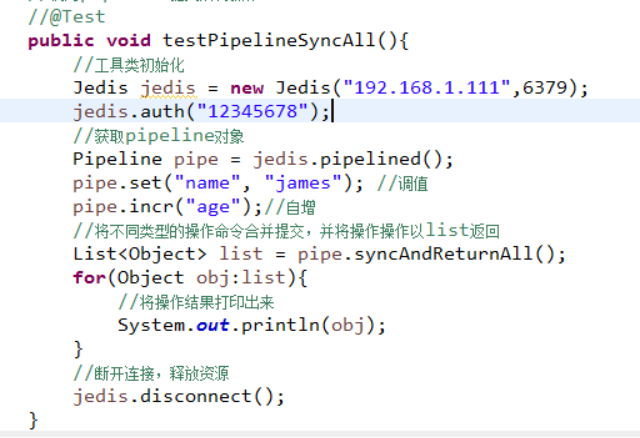
下面代码可将set和incr做一次pipiline操作,看JedisAllCommandTest用例testPipelineSyncAll方法
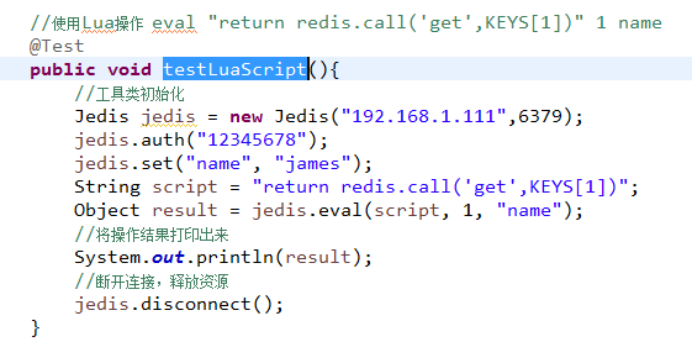
Jedis中的lua脚本
6379>set name james
6379>eval "return redis.call('get',KEYS[1])" 1 name //1个键,键名为name,返回james
可以看JedisAllCommandTest用例testLuaScript方法
如何执行lua文件呢?
例子请看cache-demo的testLuaFile测试用例方法
redis持久化
redis支持RDB和AOF两种持久化机制,持久化可以避免因进程退出而造成数据丢失;
RDB持久化
把当前进程数据生成快照(.rdb)文件保存到硬盘的过程,有手动触发和自动触发
手动触发有save和bgsave两命令
save命令:阻塞当前Redis,直到RDB持久化过程完成为止,若内存实例比较大会造成长时间阻塞,线上环境不建议用它
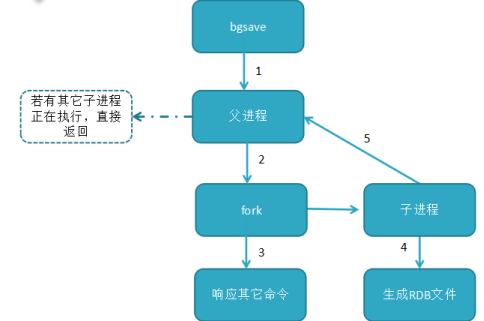
bgsave命令:redis进程执行fork操作创建子线程,由子线程完成持久化,阻塞时间很短(微秒级),是save的优化,在执行redis-cli shutdown关闭redis服务时,如果没有开启AOF持久化,自动执行bgsave;
显然bgsave是对save的优化
bgsave运行流程
RDB文件的操作
命令:config set dir /usr/local //设置rdb文件保存路径
备份:bgsave //将dump.rdb保存到usr/local下
恢复:将dump.rdb放到redis安装目录与redis.conf同级目录,重启redis即可
优点:1,压缩后的二进制文,适用于备份、全量复制,用于灾难恢复
2,加载RDB恢复数据远快于AOF方式
缺点:1,无法做到实时持久化,每次都要创建子进程,频繁操作成本过高
2,保存后的二进制文件,存在老版本不兼容新版本rdb文件的问题
AOF持久化
针对RDB不适合实时持久化,redis提供了AOF持久化方式来解决
开启:redis.conf设置:appendonly yes (默认不开启,为no)
默认文件名:appendfilename "appendonly.aof"
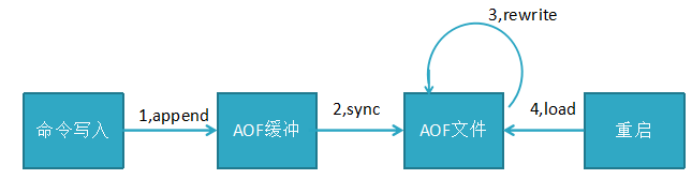
流程说明: 1,所有的写入命令(set hset)会append追加到aof_buf缓冲区中
2,AOF缓冲区向硬盘做sync同步
3,随着AOF文件越来越大,需定期对AOF文件rewrite重写,达到压缩
4,当redis服务重启,可load加载AOF文件进行恢复
AOF持久化流程:命令写入(append),文件同步(sync),文件重写(rewrite),重启加载(load)
redis的AOF配置详解:
appendonly yes //启用aof持久化方式
# appendfsync always //每收到写命令就立即强制写入磁盘,最慢的,但是保证完全的持久化,不推荐使用
appendfsync everysec //每秒强制写入磁盘一次,性能和持久化方面做了折中,推荐
# appendfsync no //完全依赖os,性能最好,持久化没保证(操作系统自身的同步)
no-appendfsync-on-rewrite yes //正在导出rdb快照的过程中,要不要停止同步aof
auto-aof-rewrite-percentage 100 //aof文件大小比起上次重写时的大小,增长率100%时,重写
auto-aof-rewrite-min-size 64mb //aof文件,至少超过64M时,重写
如何从AOF恢复?
1. 设置appendonly yes;
2. 将appendonly.aof放到dir参数指定的目录;
3. 启动Redis,Redis会自动加载appendonly.aof文件。
redis重启时恢复加载AOF与RDB顺序及流程:
1,当AOF和RDB文件同时存在时,优先加载
2,若关闭了AOF,加载RDB文件
3,加载AOF/RDB成功,redis重启成功
4,AOF/RDB存在错误,redis启动失败并打印错误信息