ELMo( Embeddings from Language Models )词向量模型,2018年3月在Deep contextualized word representations这篇论文中被提出,下面就几个方面来介绍ELMo模型。
1.产生场景(为什么产生)
word2vec、glove等词向量模型有以下缺点:
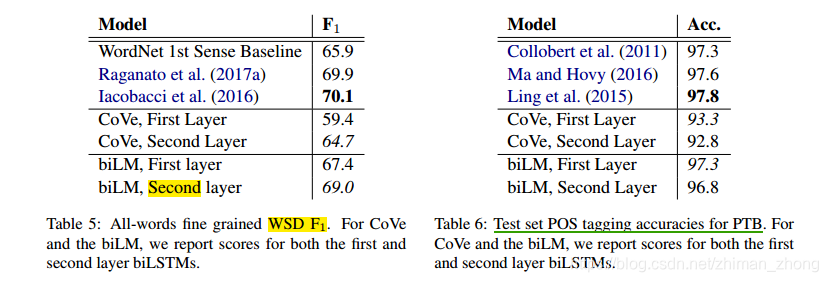
(1)没有捕捉到词性等语法信息,比如glove中
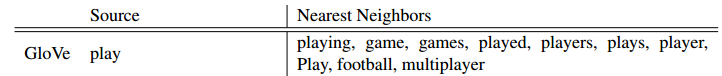
(2)每个词对应一个词向量,没有解决一词多义问题
2.特征
ELMo是一种是基于特征的语言模型,用预训练好的语言模型,生成更好的特征。
较高层的LSTM学习到了不同上下文情况下的词汇多义性(在WSD task上表现很好),而较低层捕捉了到了语法方面信息(可用作词性标注任务中)。
与传统的每个token被分配一个词向量表示不同,ELMo中每一个词语的表征都是整个输入句子的函数。
3.训练
(1)语料库:a corpus with approximately 30 million sentences (Chelba et al., 2014)
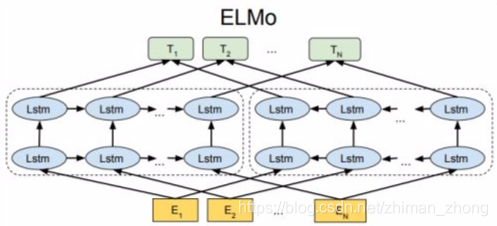
(2)训练方法:双向LSTM在大文本语料库上用耦合语言模型(LM)目标训练。


其中:是softmax-normalized权重,标量参数
允许任务模型来缩放整个ELMo向量。
4.评估
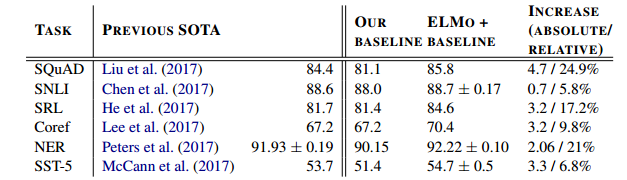
把ELMo预训练的表示作为特征加入到model中,表上baseline为不加,ELMo+baseline为添加ELMo为特征,最右格给出了performance的绝对和相对提高。
文章第五部分还比较了adding position,正则化参数等的不同选择给性能提升带来的差异
评估用到的task主要是以下六种类型的NLP任务
(1)QA
dataset:The Stanford Question Answering Dataset (SQuAD),contains 100K+ crowd sourced questionanswer pairs where the answer is a span in a given Wikipedia paragraph
(2)Textual entailment(考虑到前提,假设是否属实)
dataset:The Stanford Natural Language Inference (SNLI) corpus ,provides approximately 550K hypothesis/premise pairs.
(3)Semantic role labeling(模拟句子的谓词 - 参数结构,通常被描述为回答“谁对谁做了什么”)
dataset:the OntoNotes benchmark (Pradhan et al., 2013)
(4)Coreference resolution(clustering mentions in text that refer to the same underlying real world entities)
dataset:the OntoNotes coreference annotations from the CoNLL 2012 shared task (Pradhan et al., 2012)
(5)Named entity extraction
dataset:The CoNLL 2003 NER task (Sang and Meulder, 2003),consists of newswire from the Reuters RCV1 corpus tagged
with four different entity types (PER, LOC, ORG,MISC)
(6)Sentiment analysis
dataset:Stanford Sentiment Treebank (SST-5) involves selecting one of five labels (from very negative to very positive) to describe a sentence from a movie review.
另外,为了说明此模型很好的捕捉到了词性和词义,文章给出了两个实验,分别是WSD和POS tagging,用到的dataset分别是
SemCor 3.0和Wall Street Journal portion of the Penn Treebank (PTB)