wordcount有自带的jar,也可以自己写了上传
一、跑自带的example
1.创建输入文件
touch /usr/hadoop/tmp/words
然后vim修改内容,我写了两行
hello world
hello zzm
2.在 HDFS 上创建目录,并上传到hdfs分布式中
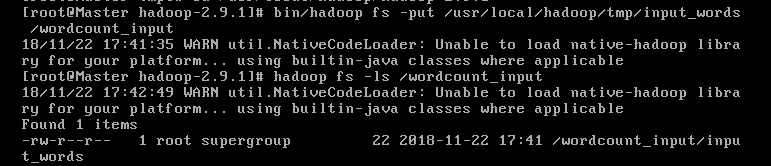
(1)[hadoop@Mmaster hadoop]$ bin/hadoop fs -mkdir /wordcount_input
本来以为很简单一件事,没想到虚拟机网络这边又出了问题
执行在HDFS里生成子目录命令,报 failed on socket exception network is unreachable错误,那肯定是网络问题
因为是之前配置好的192.168.138.128和192.168.138.130不生效了,用service network restart之后,有自动分配了192.168.138.193和192.168.138.192两个IP,只好再去修改/etc/hosts里的映射关系,成功了,但是还是报connection refuse错误

突然发现我还没有启动Hadoop进程,赶紧./start-all.sh 然后查看jps,再执行上面的命令,成功!
(2)put 然后可以ls看一下
(3)跑jar程序
![]()
这条指令指定了jar的目录,类入口,以及输入输出文件目录
用法:hadoop jar <jar> [mainClass] args…
然后输出一下结果,注意output后面必须接/*

二、跑自己上传的jar
1.问题是Hadoop的一些用法在eclipse中无法编译成功,会报错


应该是库的问题,还没有导入Hadoop的包,参考这篇博客建立了user library,再项目右键build path-configure,导入这些library,然后源代码中就有提示import了。比较坑的是一般他会提示可以import好几个,但是只有一个是对的,我根据推理加试错终于试对啦。
但是在重新执行jar命令时又遇到了一个class not found问题
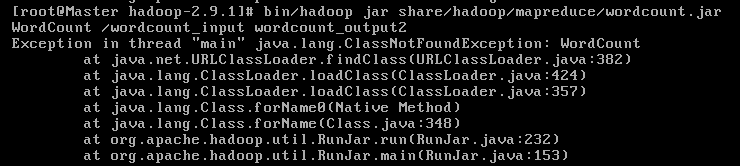
因为我是将一个工程打包成jar,所以指定main函数入口的java程序时,也需指定包的路径,如下就可以成功了
![]()
2.补充:尝试在eclipse中搭建Hadoop环境
参考这篇博客进行配置,不过版本不一样,我自己在githup上找的对应plugin

这个放入指定目录下后,在Windows也需要解压Hadoop文件夹,然后配置环境变量
这是与原文中配置不同的地方,贴出来。其中,Location name自定义一个名字就行,配置Map/Reduce Master和DFS Mastrer,Host和Port配置成与core-site.xml的设置一致即可(Host为hadoop节点的hostname,DFS Mastrer下的port为HDFS端口号,User name为安装Hadoop节点用户名称,如下图)

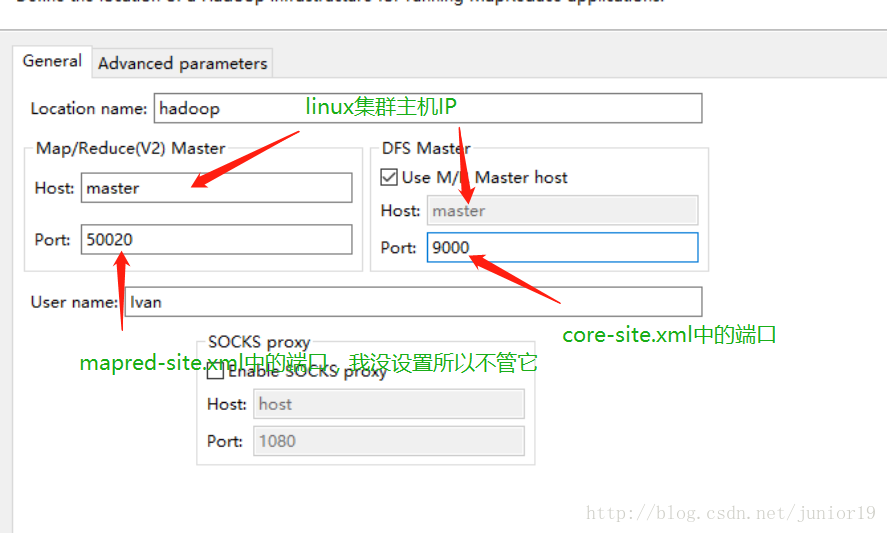
但是报了个错误,我怀疑可能是上面设置的HDFS端口号的问题,最后还是没有解决。
