近期在学习爬虫,前面自己在网上找博客看,也自己写了一些简单的代码,感觉知识不够系统。故从网上找了视频来学习,下面是对一些基础知识的总结。
一.urllib库使用(还是requests库方便,所以不列举用法了)
二.requests库使用(比urllib库更方便)
1.请求
(1)get与post请求
这是添加data和headers的post请求,get请求只能传url和headers两个参数

(2)响应
a.打印相关信息,譬如头部、状态码、cookie、url等(打印cookie很方便,不用像urllib里面还用cookiejar)
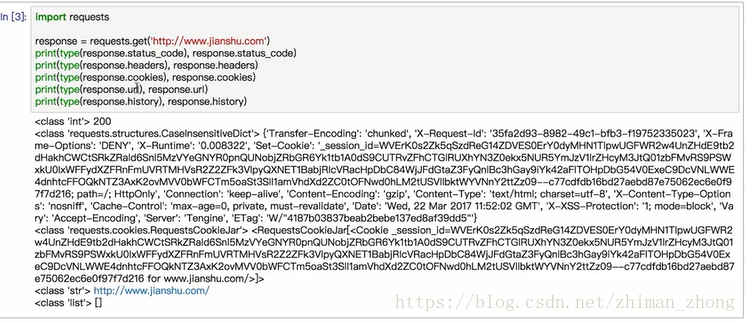
也可以这么打印cookie

b.解析json

如果你的返回结果是一个json字符串,以上两种方法会将其转换为json对象,两种会可以得到相同结果
c.解析二进制数据
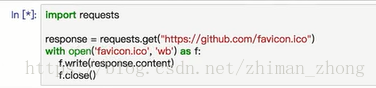
用response.content即可获取二进制数据,保存图片、视频等
(3)高级操作
a.维持会话(一般用于模拟登录)

用session()方法,上面的url相当于set方法来设置cookie,而下面用来get cookie
(在项目中的用法暂时不太清楚)
b.证书验证
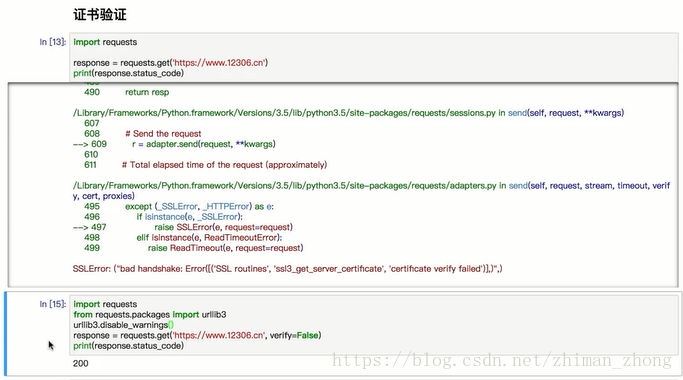
c.代理设置(就不用像urllib中使用handler了)

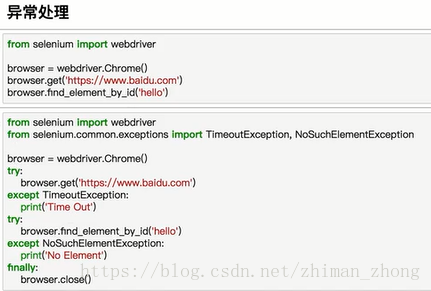
d.异常处理
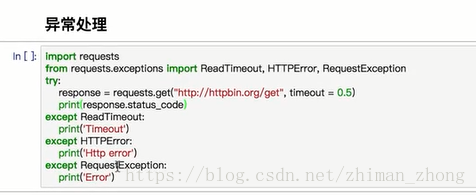
也可以只捕获第一个子类error
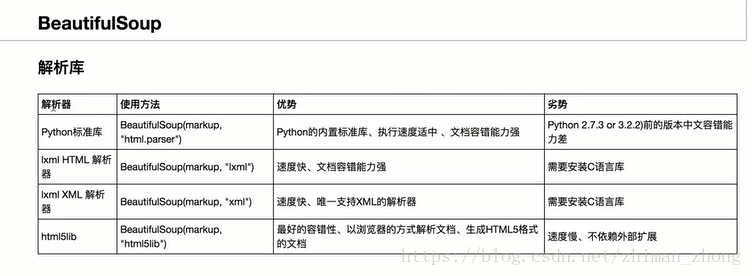
三、bs4
1.直接选择标签
(1)获取整个标签
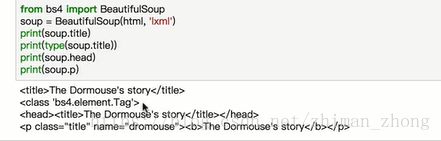
注意:这种选择方式只返回第一个结果
(2)获取属性
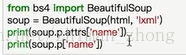
上面两种方式都可以
(3).string获取标签内文字内容

还可以嵌套选择
2.获取树节点
(1)子节点:soup.p(某标签,此处按p举例).contents/children均可,后者输出是个列表,需要用迭代器循环,如下图所示
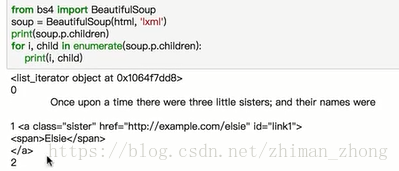
上面的输出了索引和列表内容,也可以用print(list(enumerate(soup.p.children)))输出
(2)子孙节点:soup.p.descendants,也需要用迭代器
(3)父节点:soup.p.parent(最近的父节点,不是列表)
(4)祖先节点:soup.p.parents(列表,会是各层嵌套的父节点)
(5)兄弟节点:soup.p.previous_siblings/next_siblings(也是列表)
3.标准选择器


这两个函数可以层层迭代,不断缩小范围

(1)根据标签选择


(2)根据属性来查找
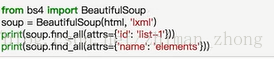

两者均可返回列表,右边是更简化的写法
4.css选择器(select方法,相当于find_all)
(1)获取标签

(2)选择属性
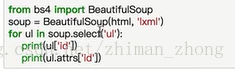

第二个可以获取标签内的文本
四、selenium库
1.获取元素

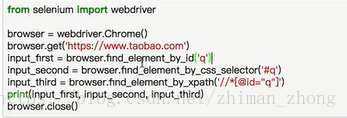
左边是所有的查找方法,后边是示例
获取属性方法 标签.get_attribute('属性'),获取文本值标签.text,获取其他信息标签.id/location/size等
2.元素交互操作(先获取元素再进行一些动作)


find_element_by_id()是找到搜索框,send_keys是模拟键盘内的输入(‘Python’+回车),wait until是等相应元素加载出来
3.交互动作(不同于元素交互,把动作附加到串行链中串行进行)

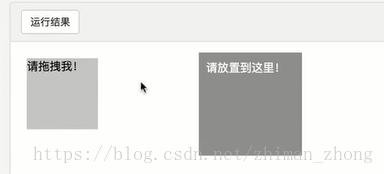
必须导入actionchain包,首先switch函数找到iframe标签(!!在子frame里不能查找到父frame里的标签),通过id分别选择出需要拖拽的两个元素,再调用actionchain里的方法进行拖拽和perform,就可以在网页上显示出效果
其他的一些动作查看api:http://selenium-python.readthedocs.io/api.html
未提供API的一些动作,比如下拉动作,可以传入js代码来实现

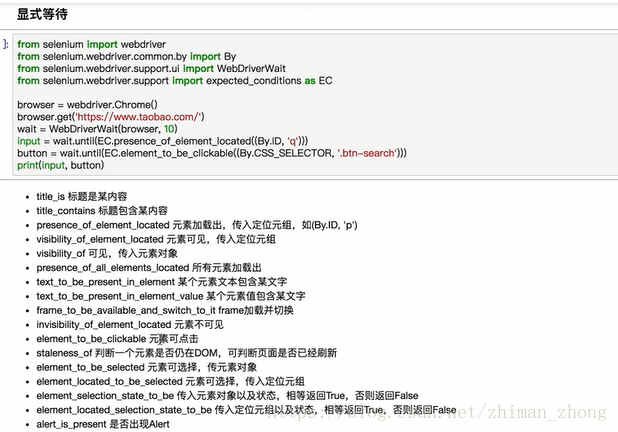
4.等待

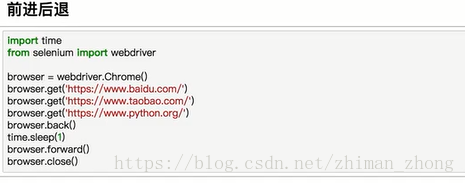
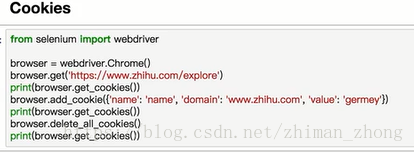
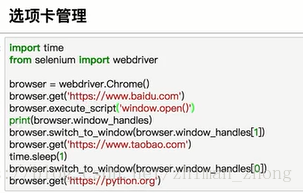
5.其他功能