公司要求用ansj分词替换掉原始的IK分词,不过ansg的分词确实好用
ansj的github地址:https://github.com/NLPchina/ansj_seg
今天搞了一下午终于是基本搞定,刚开始学习solr有许多不会的地方,刚开始尝试用的高版本的solr7,关于整合ansj_seg的参考资料当中没有高版本的solr(^.^自己太菜),只有将solr版本的降为4.8的版本(公司用的也是4.x的版本),正好符合的公司的要求:我们要的是稳定版本( )!
)!
一.tomcat整合solr
1.tomcat的下载就不说了
solr历史版本的地址:http://archive.apache.org/dist/lucene/solr/

2.在tomcat的webapps下新建两个文件夹solr和solr_home
solr用于solr的客户端运行的程序
solr_home当做solr的数据存放地
解压solr
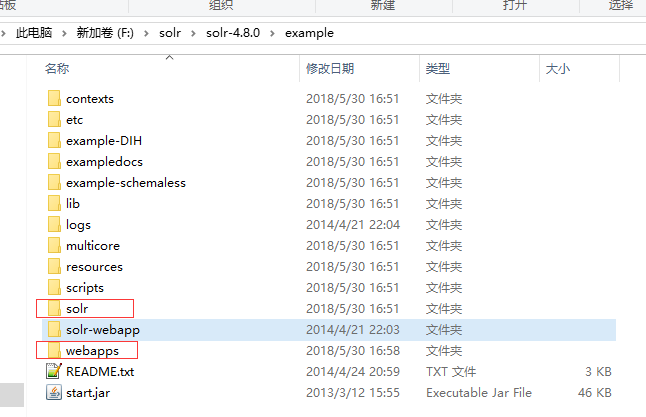
将example文件夹中的webapps下solr.war文件解压,将解压出来的文件直接剪切到tomcat的webapps中的solr文件夹里

(千万不要讲solr.war也放过去,不然程序运行会解压覆盖掉的)
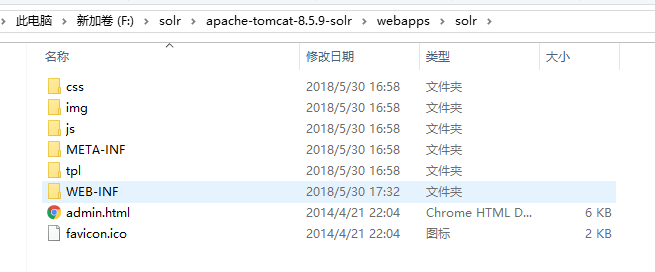
将example/lib/ext中的五个jar包移动到刚才的webapps/solr/WEB-INF/lib文件夹下面
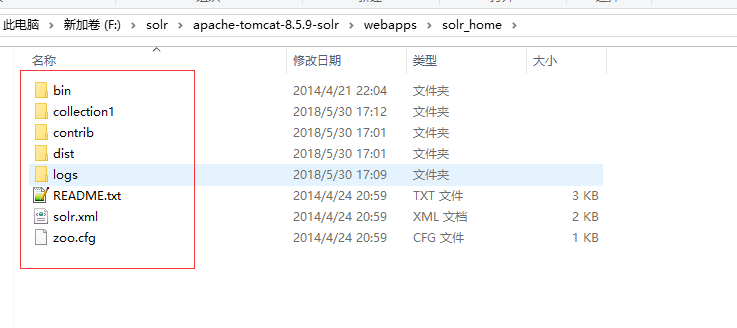
将example文件夹中的solr文件夹下的文件复制到tomcat的webapps下的solr_home当中
3.修改tomcat中刚移过来的配置文件
solr文件夹下的修改
修改WEB-INF下的web.xml
建议原先的信息保留,直接粘贴出来配置自己的solr_home路径
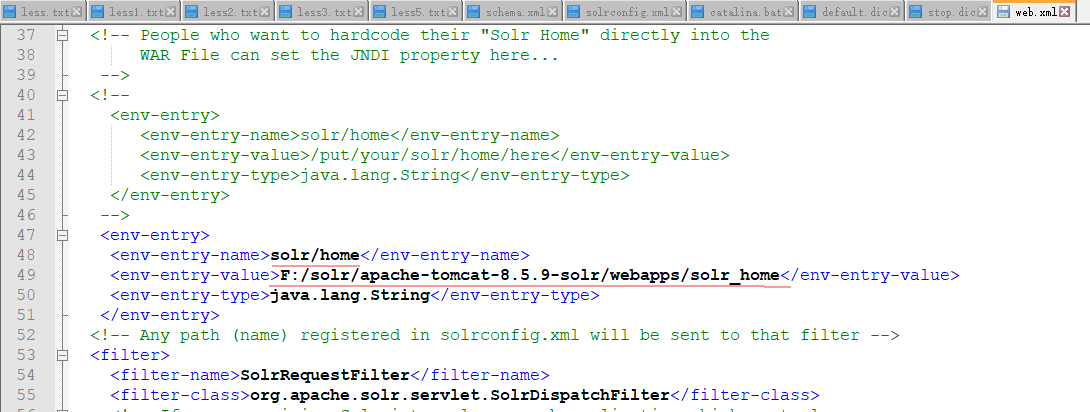
此时solr和tomcat的整合基本已经完成,大家启动tomcat可以访问solr的主页
访问地址:localhost/solr(我本地是将tomcat的端口改问了80),大家根据自己的端口去访问

看到这个图说明你已经完成了一个小目标
二.ansj_seg的整合(敲黑板,这里是重点要考的)
1. 准备需要4个jar包
ansj_seg-5.1.6.jar
nlp-lang-1.7.7.jar
ansg_lucene4_plug-5.0.2.jar
AnsjTokenizerFactory.jar(这个包是重点)
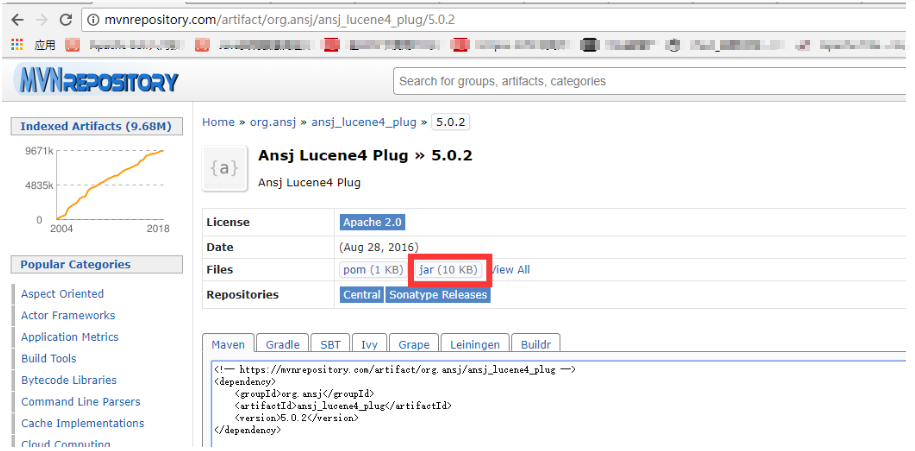
前三个jar包我们可以去maven库中去下载地址:http://mvnrepository.com(版本最好不要错,不然会出幺蛾子)
第四个jar包得由我们自己的程序生成,在eclipse中新建一个普通工程,添加依赖的jar包,如下
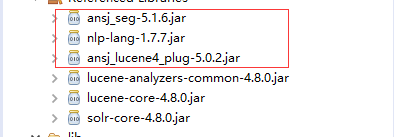
圈起来的三个我们已经下载了,其他的几个可以在我们的tomcat的solr中的lib文件夹下找到,不信你找找看
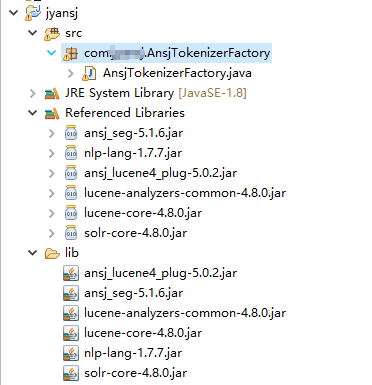
工程目录结构,普通工程就可以,这个AnsjTokenizerFactory就是我们要用的jar包
代码:
package com.***.AnsjTokenizerFactory;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.Reader;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
import org.ansj.lucene.util.AnsjTokenizer;
import org.ansj.splitWord.analysis.IndexAnalysis;
import org.ansj.splitWord.analysis.ToAnalysis;
import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.util.TokenizerFactory;
import org.apache.lucene.util.AttributeSource.AttributeFactory;
//import org.apache.lucene.util.AttributeFactory;
public class AnsjTokenizerFactory extends TokenizerFactory{
private boolean pstemming;
private boolean isQuery;
private String stopwordsDir;
public Set<String> filter;
public AnsjTokenizerFactory(Map<String, String> args) {
super(args);
assureMatchVersion();
isQuery = getBoolean(args, "isQuery", true);
pstemming = getBoolean(args, "pstemming", false);
stopwordsDir = get(args,"words");
addStopwords(stopwordsDir);
}
//add stopwords list to filter
private void addStopwords(String dir) {
if (dir == null){
System.out.println("no stopwords dir");
return;
}
//read stoplist
System.out.println("stopwords: " + dir);
filter = new HashSet<String>();
File file = new File(dir);
InputStreamReader reader;
try {
reader = new InputStreamReader(new FileInputStream(file),"UTF-8");
BufferedReader br = new BufferedReader(reader);
String word = br.readLine();
while (word != null) {
filter.add(word);
word = br.readLine();
}
} catch (FileNotFoundException e) {
System.out.println("No stopword file found");
} catch (IOException e) {
System.out.println("stopword file io exception");
}
}
@Override
public Tokenizer create(AttributeFactory arg0, Reader input) {
// TODO Auto-generated method stub
if(isQuery == true){
//query
return new AnsjTokenizer(new ToAnalysis(new BufferedReader(input)), input, filter, pstemming);
} else {
//index
return new AnsjTokenizer(new IndexAnalysis(new BufferedReader(input)), input, filter, pstemming);
}
}
} export导出jar包,记得导出的时候不要连带的将lib下依赖的jar包也导进去,标红的地方不要打勾选
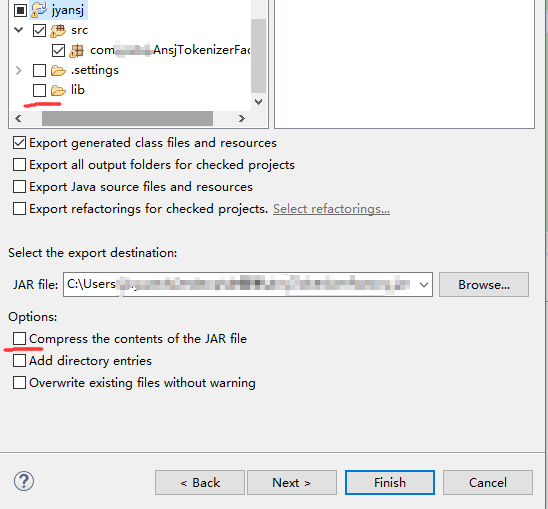
这样第四个需要的jar包也有了
2.将这四个jar包放到tomcat里solr的lib文件夹下面
3.solr_home文件夹下的修改
修改collection1/conf/schema.xml文件
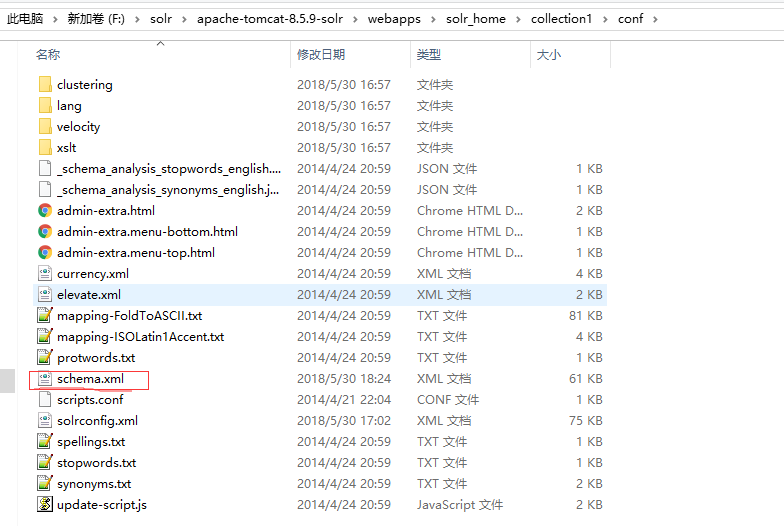
挑个自己喜欢的地方将分词方式引入
<!-- ansj -->
<fieldType name="text_ansj" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="com.jyansj.AnsjTokenizerFactory.AnsjTokenizerFactory" isQuery="false" pstemming="true"/>
</analyzer>
<analyzer type="query">
<tokenizer class="com.jyansj.AnsjTokenizerFactory.AnsjTokenizerFactory" isQuery="false" pstemming="true"/>
</analyzer>
</fieldType> 
4.引入ansj_seg的词典
在tomcat中solr项目文件夹下的WEB-INF中看有没有classes文件夹,没有的话新建,将ansj_seg的词典文件夹和properties文件移到classes文件夹中(这个ansj_seg-master是我从github上下载下来的,上面开始就给出了地址)
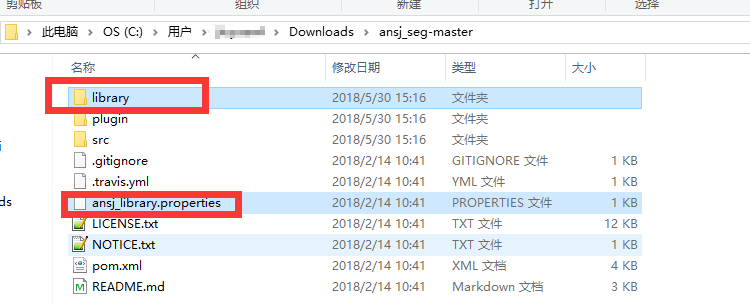

三.验收结果
重新启动tomcat
标红的地方是因为我没有配自己的停用词字典
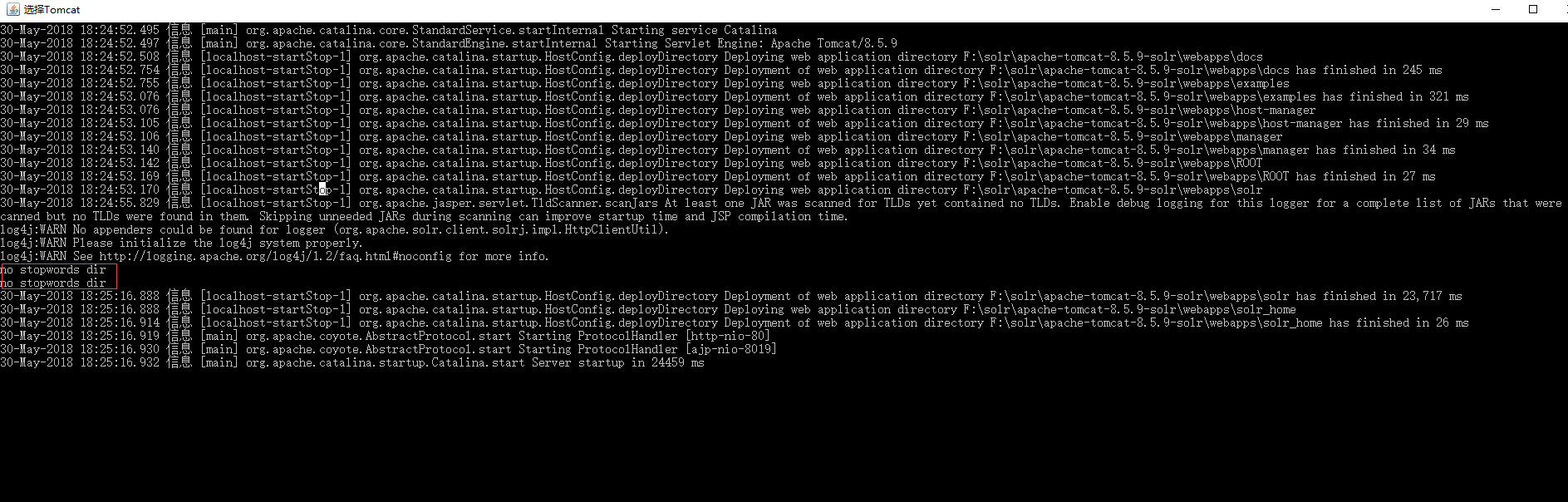
页面查看结果
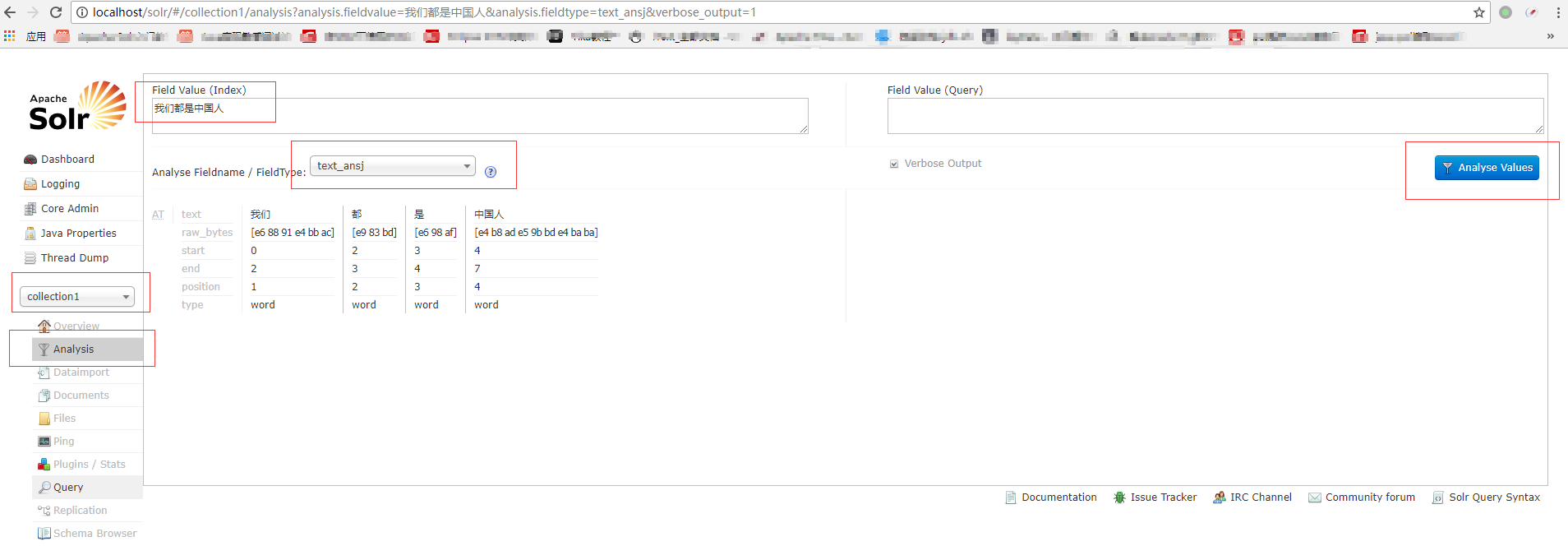
OK,我们都是中国人。
有问题的地方希望大家及时指出,我及时更正,不要让他人再踏坑!
参考博客:https://blog.csdn.net/allthesametome/article/details/46907197