Real-time Personalization using Embeddings for Search Ranking at Airbnb
Airbnb, Inc
KDD2018 ADS Track 的最佳论文
METHODOLOGY
Listing Embeddings
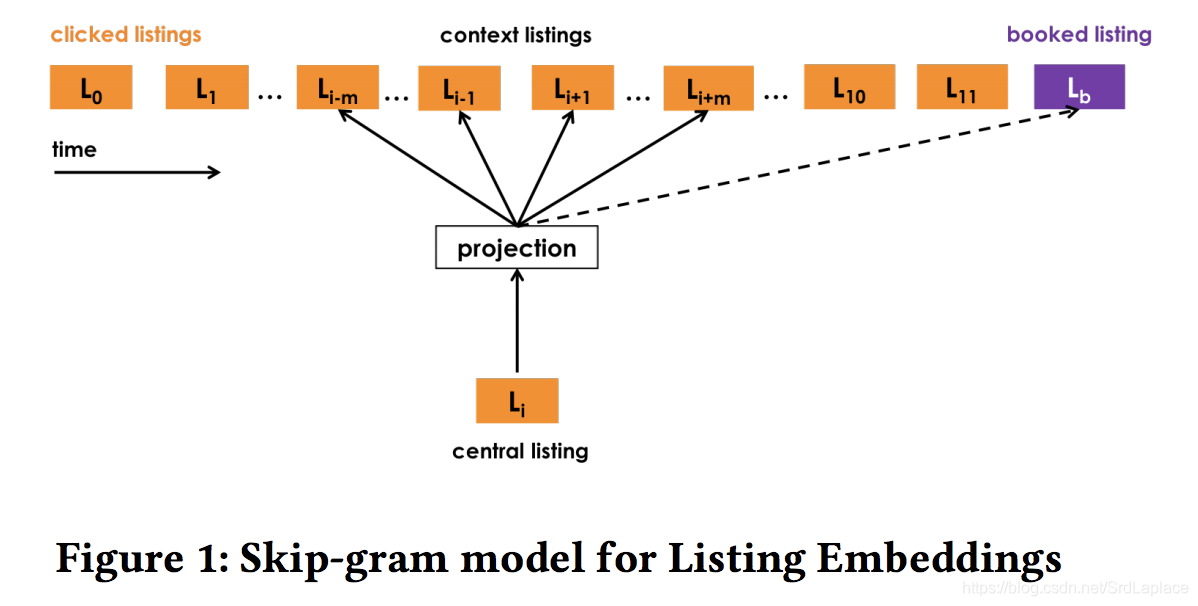
我们有用户浏览的 session 数据,使用类似 skip-gram model 的方法来 embed 每条 listing,认为浏览过程中前后的 listing 是相似的,最大化:
但是 listing 太多,计算过于复杂。我们改变思路,生成正集合
(里面的元素对在一个 session 窗口
内连续点击)和负集合
(里面的元素为随机取的),优化问题变为:
Booked Listing as Global Contex
对于最终预定的 session,我们任务浏览过程的 listing 与最后预定的 listing 也是相似的,多增加一项
Adapting Training for Congregated Search
因为随机抽取的 ,所以大概率选取 来源于同一个 market, 来源于不同的 market,为了使得学习的 embedding 学到的不是 market 的信息而是产品的信息,所以我们随机抽取同一市场的作为辅助负集合
Cold start listing embeddings
创建 listing 后,host 需要提供有关信息,例如位置,价格,列表类型等。使用提供的元数据来查找3个地理位置最接近(半径10英里内)、其他类型也相似的、价格区间相同的 listing ,把这3个 listing 的 embedding 向量以形成新的 listing 的 embedding。 这样我们能够覆盖超过98%的新 listing。
Examining Listing Embeddings
发现 embedding 确实有效,相似的 listing 有相近的 embedding。
User-type & Listing-type Embeddings
我们希望学习到不同市场(纽约和伦敦的房间)之间的 listing 之间的相似性。我们给定一个 user 的预定列表 ,认为同一个 user 定的 listing 之间有一定的相似性。下面这种思路的一些困难:
- 有预定的 session 数目远远小于点击 seesion 的数目
- 众多 user 只预订过1次
- 如果希望学习出有意义的 embedding 每个 entities 至少需要发生事件出现5到10次,大量的 listing 没出有这么多次预定
- 长时间的间隔的预定可能喜好发生变化,例如长大了,职业发生变化等
为了解决这些问题(我的理解是太稀疏了数据),我们制定规则把 listing 映射为不同的 type。通过 user 最近的预定和点击的 listing_type 学习 user_type 的 embedding,和训练 Listing Embeddings 类似(点击预定与自己 type 类似的,随机取的不类似,没点击的不类似),训练 user_type的 embedding。
总结
巧妙的借鉴了 word2vec 的思路对搜索对象进行 embedding。除了直接平移 skip-gram 以外,巧思之处有这么几个:
- 构造正样本集合和负样本集合来简化运算
- 为了防止学习错信息构造特定的负样本集合
- 利用问题的特殊性,最终预定的房间应该和前面浏览的都有一定的相似性对优化目标加了一项
- 解决数据稀疏相当于先给定 listing_type 的 embedding,来学习 user_type 的 embedding