摘要
神经网络/深度学习模型训练的过程本质是对权重进行更新,在对一个新的模型进行训练之前,需要每个参数有相应的初始值。对于多层神经网络/深度学习而言,如何选择参数初始值便成为一个值得探讨的问题。本文从实现激活值的稳定分布角度来探讨神经网络的效率优化问题
权重在神经网络/深度学习中的作用(个人领受)
神经网络的作用是从大量不同的待训练数据中发现数据本身的内在规律(提取特征数据)。这就要求输入数据不能过于集中,数据相对来说要有一定的分散空间,这样神经网络才能发挥它不断学习和归类的优势。数据过于集中要么说明数据集本身分布就不全面,要么说明数据已经分类得比较好了,作为训练数据会误导神经网络。这样神经网络也就失去了意义,甚至会起反作用
按照上述推导,在多层神经网络中,因为存在各层级联的情况,前一层的输出会成为下一层的输入。所以为了使各层神经网络真正的发挥作用,就要求各层(非输出层)的输出符合数据本身的分布特性,而不能过于集中。不然下一级的神经网络就失去了意义,甚至会起反作用
为了使各层(非输出层)的输出符合某种分布,而不过于集中。f(wx+b)中的每一项都需要研究和优化。包括激活函数f、权重w和偏置b。本文主要讨论权重w初始值对神经网络的影响
神经网络一个理想的初始状态应该是各层输出值比较分散,而且能反映输入数据本身的分布特性。这样在反向传播时,各权重值的变化方向和大小也能呈现出离散性,有利于网络的快速收敛
什么样的初始状态利于学习和调整
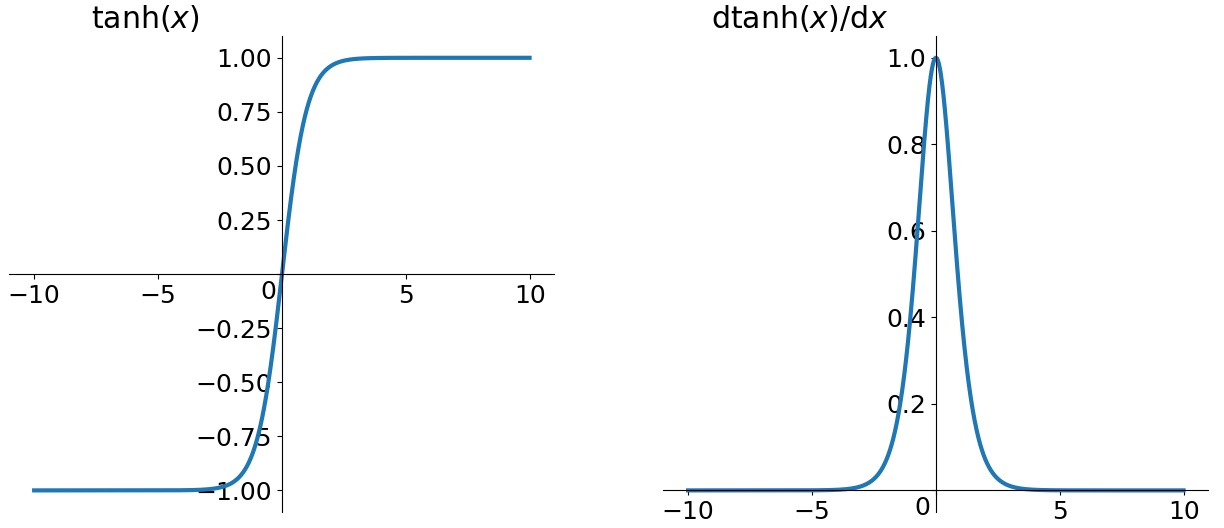
学习和调整实际上是反向传播的过程,通过梯度下降法调整权重和偏置。那么有利于使用梯度下降法改善权重和偏置的状态就是一个比较好的状态。如何有利于使用梯度下降法?梯度大的地方收敛就快。这就需要看具体的激活函数特性
为了使得网络中信息更好的流动,每一层输出分布应当尽量与输入一致,方差应该尽量相等
在初始化的时候使各层神经元的方差保持不变, 即使各层有着相同的分布. 很多初始化策略都是为了保持每层的分布不变。
梯度爆炸与梯度消失
针对多次神经网络,在神经网络的反向传播过程中,根据链式法则,如果每一层神经元对上一层的输出的偏导乘上权重结果都小于1的话,那么即使这个结果是0.99,在经过足够多层传播之后,误差对输入层的偏导会趋于0。都大于1的话,梯度会随着反向传播层数的增加而呈指数增长,导致梯度爆炸。
权重初始化方法
附图为输入0均值,1标准差,10层网络,经过初始态,一次正向传播后各层输出分布。具体代码见GITHUB
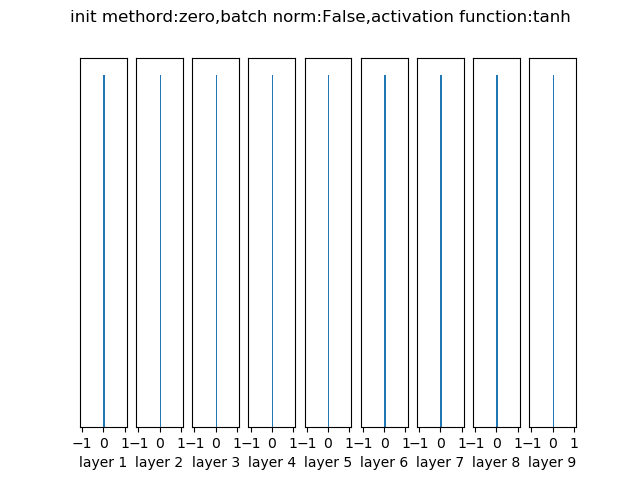
固定值(0值)
极不建议。因为如果网络中的每个神经元都计算出同样的输出,然后它们就会在反向传播中计算出同样的梯度,从而进行同样的参数更新。换句话说,如果权重被初始化为同样的值,神经元之间就失去了不对称性的源头
经过10层网络后各层的输出分布
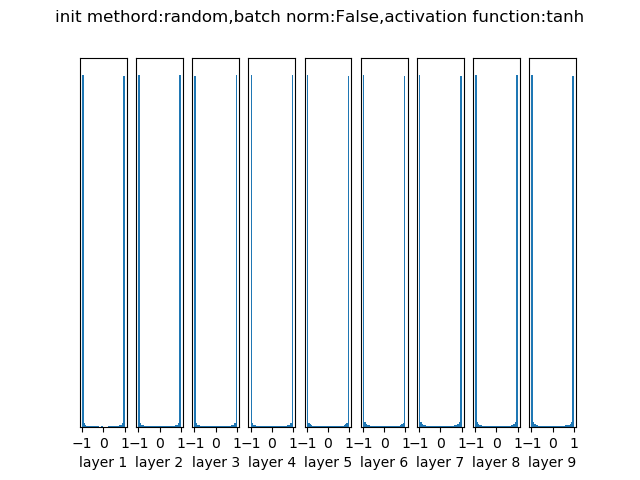
随机化
经过10层网络后各层的输出分布
- 小随机数
根据激活函数的特性,选择小随机数
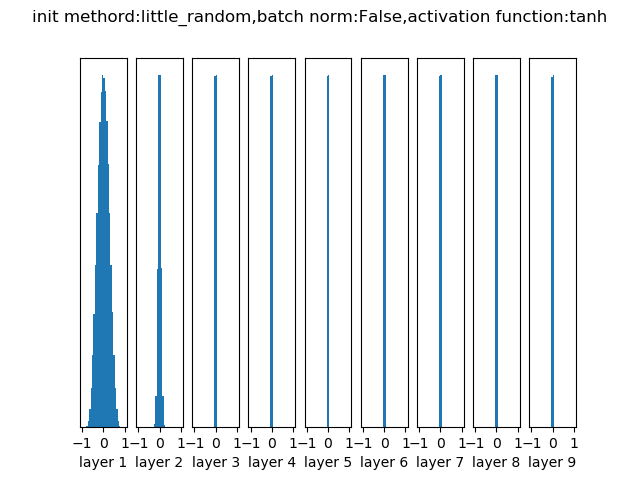
只适用于小型网络。
权重初始值要非常接近0又不能等于0。解决方法就是将权重初始化为很小的数值,以此来打破对称性。其思路是:如果神经元刚开始的时候是随机且不相等的,那么它们将计算出不同的更新,并将自身变成整个网络的不同部分。小随机数权重初始化的实现方法是:W = 0.01 * np.random.randn(D,H)来生成随机数的。根据这个式子,每个神经元的权重向量都被初始化为一个随机向量,而这些随机向量又服从一个多变量高斯分布,这样在输入空间中,所有的神经元的指向是随机的。
如果每层都用N(0, 0.01)随机初始化的话, 各层的数据分布不一致, 随着层度的增加, 神经元将集中在很大的值或很小的值, 不利于传递信息.经过10层网络后各层的输出分布
- Xavier
最为常用的神经网络权重初始化方法
神经网络分布的方差随着输入数量的增大而增大,可以通过正则化方差来提高权重收敛速率.不合适的权重初始化会使得隐藏层的输入的方差过大,从而在经过sigmoid这种非线性层时离中心较远(导数接近0),因此过早地出现梯度消失
前向传播推导
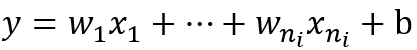
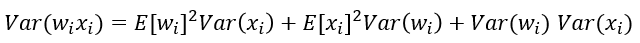
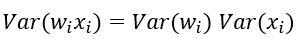
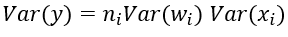
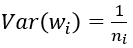
反向传播推导
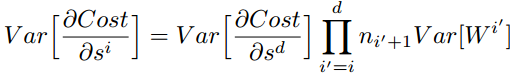
最终分布条件
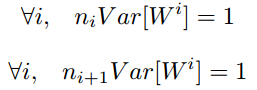
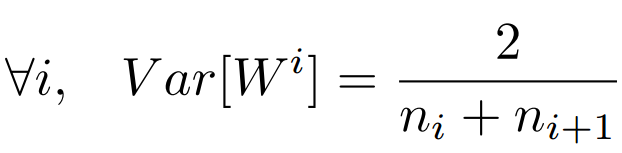
本次仅使用前向传播类进行类比
经过10层网络后各层的输出分布
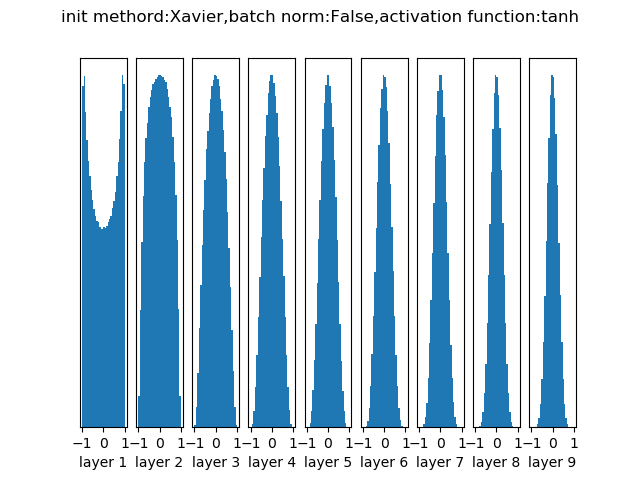
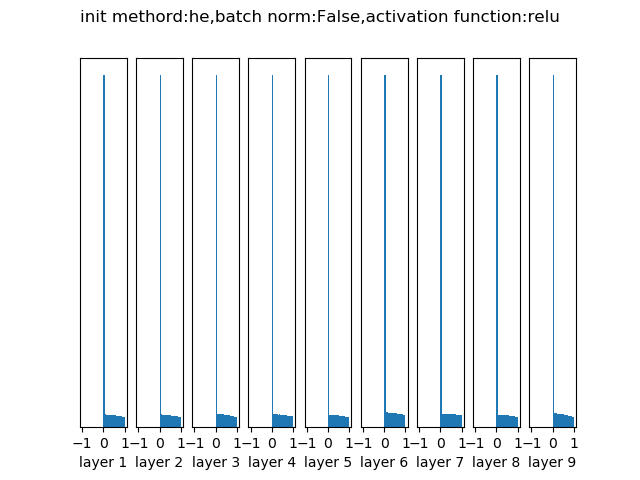
- HE/MSRA
Xavier推导的时候假设激活函数是线性的。HE/MSRA是沿用Xavier的思想,针对relu类型的激活函数做的进一步优化
Xavier初始化经过10层网络RELU激活后各层的输出分布
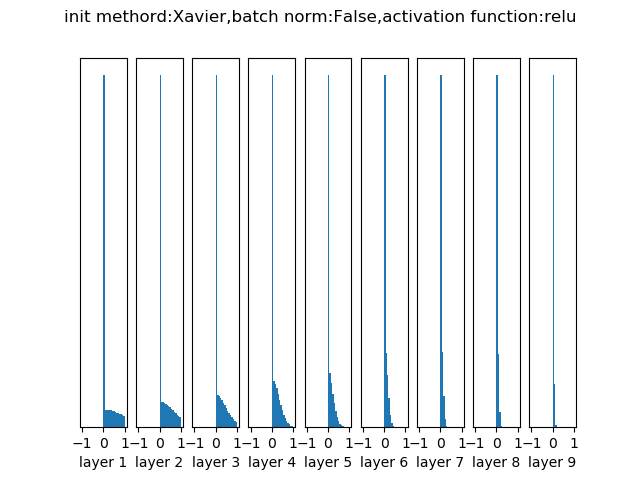
HE/MSRA初始化经过10层网络RELU激活后各层的输出分布
- 稀疏初始化
将所有权重矩阵设为0,但是为了打破对称性,每个神经元都同下一层固定数目的神经元随机连接(其权重数值由一个小的高斯分布生成)。一个比较典型的连接数目是10个。
fine-turning
- pre-training
首先使用一个方法(贪婪算法、无监督学习。。。)针对每一层的权重进行优化,用于提取有效的特征值,然后用优化好的权重进行训练
- Transfer Learning
用当前已训练好的比较稳定的神经网络。这一块研究文章较多,后面作为专题研究
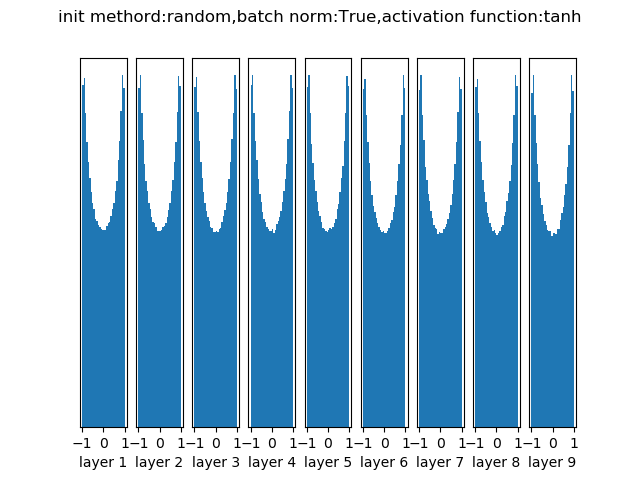
另辟蹊径-跳过权重问题————批量归一化
在每次前向传播过程中,都将输入数据进行归一化整理,使得输入数据满足某种分布规律
公式

随机初始化经过10层网络批量归一化后各层的输出分布
实例
具体代码见GITHUB
- 训练框架:TensorFlow
- 数据集:MNIST手写识别
- 神经网络类型:4隐藏层,sigmoid激活
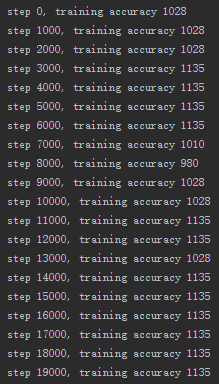
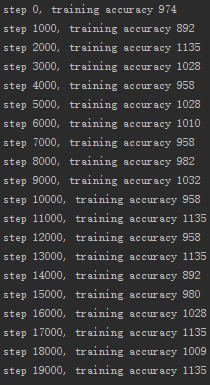
- 针对全零初始化、小随机数初始化、Xavier初始化和批量归一化进行训练次数和准确率对比
| 序号 | 初始化方法 | 达到80%的训练次数 | 最终精确度 |
|---|---|---|---|
| 1 | 全零初始化 | 无法达到 | 11% |
| 2 | 小随机数初始化 | 无法达到 | 11% |
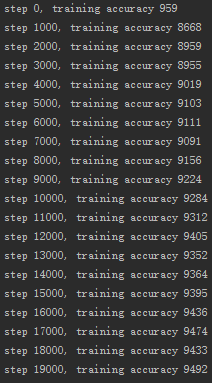
| 3 | Xavier初始化 | 6000 | 95% |
| 4 | 小随机数初始化+批量归一化 | 1000 | 95% |
全零初始化
小随机数初始化
Xavier初始化
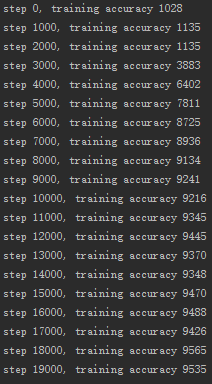
小随机数初始化+批量归一化
结论
- 优先使用批量归一化
- 优先使用Xavier初始化方法
- ReLU激活函数优先使用HE/MSRA初始化方法
参考资料
- 聊一聊深度学习的weight initialization
- Stacked Autoencoders
- CS231n neural-networks-2 对应翻译笔记
- 深度学习——Xavier初始化方法
- 深度学习——MSRA初始化
- TensorFlow从0到1 | 第十五章 重新思考神经网络初始化
- 神经网络中激活函数稀疏激活性的重要性
- 译文 | 批量归一化:通过减少内部协变量转移加速深度网络训练