半个世纪以来,随着计算机技术全面融入社会生活,信息爆炸已经积累到了一个开始引发变革的程度。它不仅使世界充斥着比以往更多的信息,而且其增长速度也在加快,创造出了“大数据(Big Data)”这个概念。如今,这个概念几乎应用到了所有人类智力与发展的领域中。
Big Data是近来的一个技术热点,历史上,数据库、数据仓库、数据集市等信息管理领域的技术,很大程度上也是为了解决大规模数据的问题。被誉为数据仓库之父的Bill Inmon早在20世纪90年代就经常提及Big Data。
21世纪是数据信息大发展的时代,移动互联、社交网络、电子商务等极大拓展了互联网的边界和应用范围,各种数据正在迅速膨胀并变大。
互联网、云计算、移动和物联网的迅猛发展。无所不在的移动设备、RFID、无线传感器每分每秒都在产生数据,数以亿计用户的互联网服务时时刻刻在产生巨量的交互。互联网(社交、搜索、电商)、移动互联网(微博)、物联网(传感器,智慧地球)、车联网、GPS、医学影像、安全监控、金融(银行、股市、保险)、电信(通话、短信)都在疯狂产生着数据:1)全球每秒钟发送 2.9 百万封电子邮件; 2)每天会有 2.88 万个小时的视频上传到Youtube; 3)推特上每天发布 5 千万条消息; 4)每天亚马逊上将产生 6.3 百万笔订单; 4)每个月网民在Facebook 上要花费7 千亿分钟; 5)Google 上每天需要处理24PB 的数据。
我们在一个大数据的时代漩涡中,每天都有是以亿计的数据产生,如何获取这些数据,如何使用这些数据,如何用好这些数据,都是一个难题。之前遇到的一位做语言学研究的小姐姐,研究课题需要建立自己的语言数据库,每次都要在新闻网站上去搜索关键字的文章,然后复制黏贴下来,非常的辛苦和费事费时,我听说之后非常吃惊,问她这种机械却又累人的工作,为什么不让软件解决,而要自己一个个手动复制黏贴。她的回答是自己是学文科的,又不会写代码,又搞不懂编程,所以她只能自己辛苦一点了。听完她的回答之后,我很心痛,所以我立马给他推荐了一款软件,帮助她从复杂的复制黏贴工作中解脱出来。
这款软件对小白用户十分友好,智能模式只要输入网址就能帮忙采集了,是谷歌大牛回国写的一款软件,而且还是免费采集和导出的,现在把这个软件分享出来,希望对大家有所帮助。我会以新闻网站中国日报为例,为大家演示如何通过这款爬虫软件自动采集数据。
首先,需要下载安装软件,大家可以到官网上下载最新版本的软件,然后注册新用户登录,游客用户也可以采集数据,但是可能会丢失,建议还是注册新用户。

首先,复制需要采集的网址,打开软件输入网址,新建智能采集任务。

在智能模式下,我们输入网址后软件即可自动识别出页面上的数据并生成采集结果,每一类数据对应一个采集字段,可以右击字段进行相关设置,包括修改字段名称、增减字段、处理数据等。

由于在列表页上只展示了部分的新闻信息,如果需要采集具体的新闻内容,我们需要右击链接使用“深入采集”功能,跳转到详情页进行采集。

接着点击“保存并启动”按钮,可在弹出的页面中进行一些高级设置,包括定时启动、自动入库和下载图片,我们如果没有用到这些功能,可以直接点击“启动”运行任务。

数据采集完毕后我们可以导出数据,这款软件比较好的一点是不仅采集免费,而是可以导出多种格式的文档,对导出也没有什么限制。
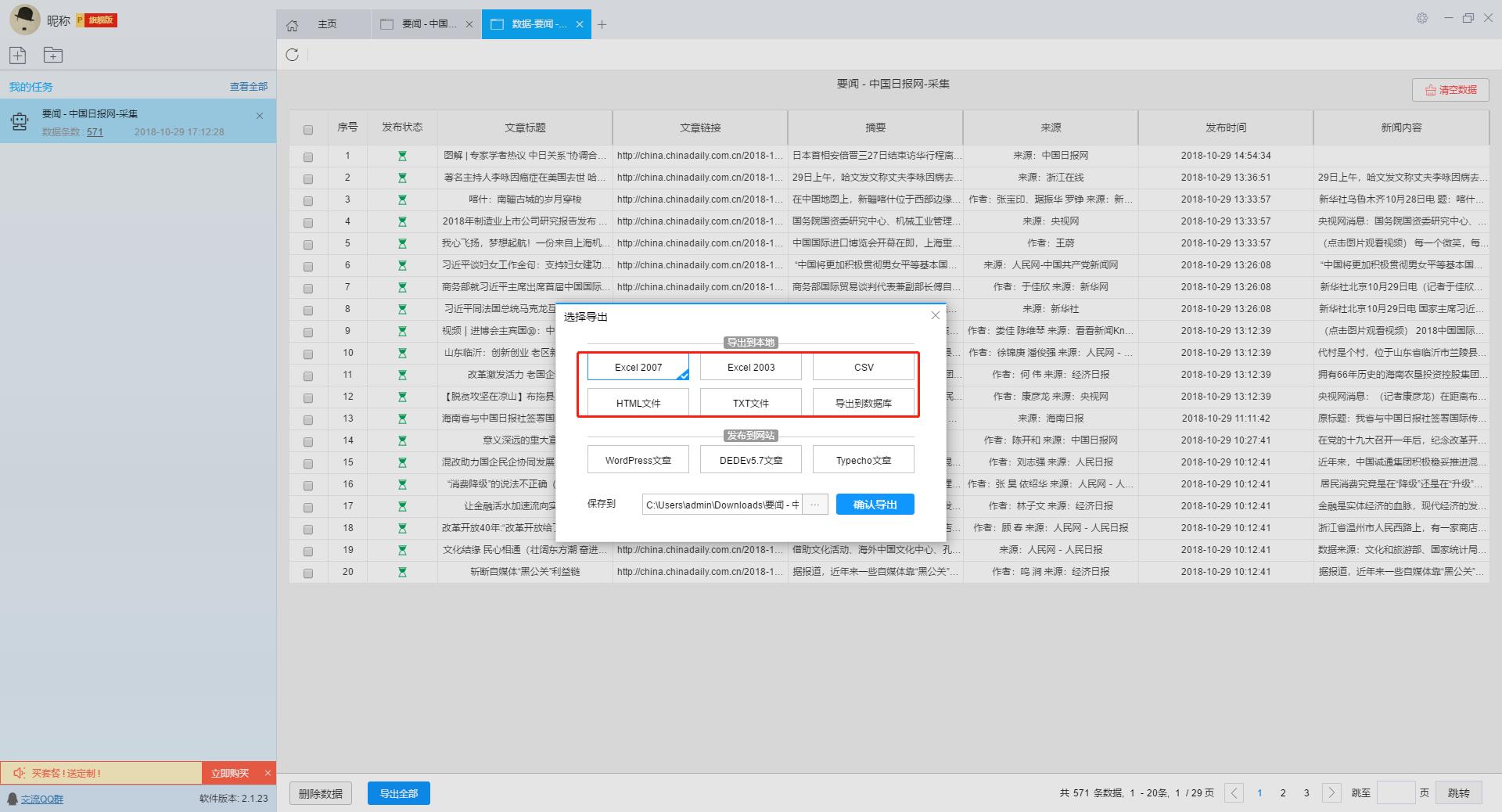
为方便查看我们导出一个Excel2007的表格,我们可以看到数据质量还是挺高的,大家可以直接使用这些数据,也可以在这个基础上对数据进行加工处理。