聚类是一种涉及数据点分组的机器学习技术。给定一个数据点集,则可利用聚类算法将每个数据点分类到一个特定的组中。理论上,同一组数据点具有相似的性质或(和)特征,不同组数据点具有高度不同的性质或(和)特征。聚类属于无监督学习,也是在很多领域中使用的统计数据分析的一种常用技术。本文将介绍常见的5大聚类算法。
K-Means算法
K-Means算法可能是最知名的聚类算法,该算法在代码中很容易理解和实现。
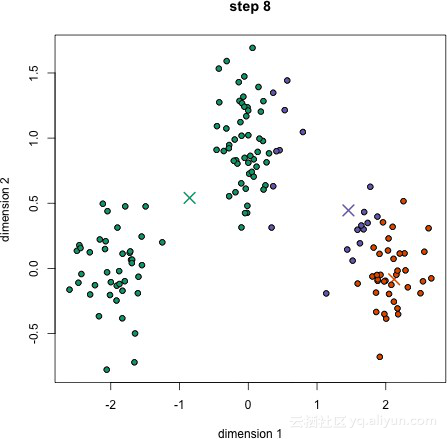
K-Means聚类
1.首先我们选择一些类或组,并随机初始化它们各自的中心点。为了计算所使用类的数量,最好快速查看数据并尝试识别任何一个不同的分组。中心点是和每个数据点矢量长度相同的矢量,上图标记为“X”。
2.每个数据点是通过计算该点与每个组中心的距离进行分类的,然后再将该点分类到和中心最接近的分组中。
3.根据这些分类点,通过计算群组中所有向量的均值重新计算分组中心。
4.重复以上步骤进行数次迭代,或者直到迭代之间的组中心变化不大。选择结果最好的迭代方式。
因为我们只是计算点和组中心之间的距离,计算量很少,所以K-Means算法的速度非常快,具有线性复杂度O(n)。
K-Means算法的缺点是必须选择有多少个组或类,因为该算法的目的是从不同的数据中获得信息。另外,K-means算法从随机的选择聚类中心开始,因此不同的算法运行可能产生不同的聚类结果。其结果缺乏一致性,而其他聚类方法结果更一致。