前言
最近在琢磨文本分类相关的深度学习模型,也研读了以下三篇使用卷积神经网络CNN实现的文本分类论文:
(1)《Convolutional Neural Networks for Sentence Classification》
(2)《Character-level Convolutional Networks for Text Classification》
(3)《Effective Use of Word Order for Text Categorization with Convolutional Neural Networks》
此博客也有对一些文本分类论文思路进行讲解:https://blog.csdn.net/guoyuhaoaaa/article/details/53188918
模型实现
这几天主要实现了第一篇论文的CNN模型,使用了20newsgroup的数据集,实现三个模型如下:
- CNN-rand
句子中的的word vector都是随机初始化的,同时当做CNN训练过程中需要优化的参数; - CNN-static
句子中的word vector是使用word2vec预先对Google News dataset (about 100 billion words)进行训练好的词向量表中的词向量。且在CNN训练过程中作为固定的输入,不作为优化的参数; - CNN-nonstatic
句子中的word vector是使用word2vec预先对Google News dataset (about 100 billion words)进行训练好的词向量表中的词向量。在CNN训练过程中作为固定的输入,做为CNN训练过程中需要优化的参数;
整体思路如图所示(摘自论文1):
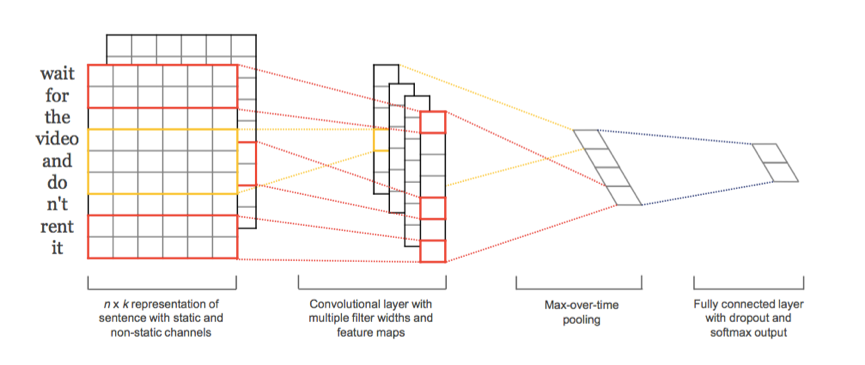
包括以下几个部分:
* 输入层
* 卷积层
抽取Feature Map, 也就是我们所需的文本特征
* 全连接层
通过Max-pooling操作,即将每个Feature Map向量中最大的一个值抽取出来,组成一个一维向量
* 输出层
该层的输入为池化操作后形成的一维向量,经过激活函数ReLU输出,再加上Dropout层防止过拟合。并在全连接层上添加l2正则化参数
更详细的讲解可以看这篇文章:https://www.jianshu.com/p/fe428f0b32c1
部分代码
具体的代码以及我踩过的坑可以看我的github:
https://github.com/DilicelSten/CNN_learning/blob/master/simple%20cnn/
import tensorflow as tf
# Embedding layer
with tf.device('/cpu:0'), tf.name_scope("embedding"):
self.W = tf.Variable(
tf.random_uniform([vocab_size, embedding_size], -0.25, 0.25),
name="W")
self.embedded_chars = tf.nn.embedding_lookup(self.W, self.input_x)
self.embedded_chars_expanded = tf.expand_dims(self.embedded_chars, -1)
# create a convolution + maxpool layer for each fliter size
pooled_outputs = []
for i, filter_size in enumerate(filter_sizes):
with tf.name_scope("conv-maxpool-%s" % filter_size):
# convolution layer
filter_shape = [filter_size, embedding_size, 1, num_filters]
W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1), name="W")
b = tf.Variable(tf.constant(0.1, shape=[num_filters]), name="b")
conv = tf.nn.conv2d(
self.embedded_chars_expanded,
W,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")
# apply nonlinearity
h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu")
# maxpooling over the outputs
pooled = tf.nn.max_pool(
h,
ksize=[1, sequence_length - filter_size + 1, 1, 1],
strides=[1, 1, 1, 1],
padding="VALID",
name="pool")
pooled_outputs.append(pooled)
# combine all the pooled features
num_filters_total = num_filters * len(filter_sizes)
self.h_pool = tf.concat(pooled_outputs, 3)
self.h_pool_flat = tf.reshape(self.h_pool, [-1, num_filters_total])
# add dropout
with tf.name_scope("dropout"):
self.h_drop = tf.nn.dropout(self.h_pool_flat, self.dropout_keep_prob)
# final (unnormalized) scores and predictions
with tf.name_scope("output"):
W = tf.get_variable(
"W",
shape=[num_filters_total, num_classes],
initializer=tf.contrib.layers.xavier_initializer())
b = tf.Variable(tf.constant(0.1, shape=[num_classes]), name="b")
l2_loss += tf.nn.l2_loss(W)
l2_loss += tf.nn.l2_loss(b)
self.scores = tf.nn.xw_plus_b(self.h_drop, W, b, name="scores")
self.predictions = tf.argmax(self.scores, 1, name="predictions")