1.绪论
在此篇文章中,对于谱聚类的解释基于图论,并不涉及Random walks(在参考的文章中(1)中有详细解释)
在叙述理论推导的同时,还需要给出简单的例子进行计算以加深理解。
给定一个带权无向图,
是结点集合,
是边的集合。在谱聚类中,所有的样本构成了结点集合V,结点
之间的相似度
就是对应边的权重
。聚类的目标就是将这些结点分成不同类,类与类之间有着较小的相似度,而类中的结点有着较大的相似度。这个目标在给定的相似度图
中,就是对
进行一个划分。一些相关定义如下:
(0).图论相关定义:无向带权图
对于V中的任意两个点,可以有边连接,也可以没有边连接。定义权重为点vi和点vj之间的权重。
由于是无向图,所以wij=wji,即邻接矩阵是对称的。对于有边连接的两个点vi和vj,wij>0,对于没有边连接的两个点vi和vj,wij=0。对于结点自身,wii=0。
对于图中的任意一个点vi,它的度定义为和它相连的所有边的权重之和,即
。
利用每个点度的定义,可以得到一个nxn的度矩阵D,它是一个对角矩阵,只有主对角线有值,对应第i行的第i个点的度数,定义为:。
对于V中的一个子集A,定义A的补集。
A中结点的个数。
。 指示向量:
,
。
(1) 相似矩阵的构建:在给出上述图论的标准定义后,有一个问题就是:邻接矩阵的构建时权重怎么得到?我们只能通过数据之间的关系得到,而不能手动输入。具体的做法就是:给定一个相似度函数去定量衡量。具体有三种:
a.邻近法:给定一个阈值
,欧式距离大于它,相似度为0;相似度小于它为
,相似度为
。
,很明显,这种方式相似度的衡量很不精确,因此在实际应用中,很少使用ϵ-邻近法。
b.K邻近法:利用KNN算法遍历所有的样本点,取每个样本最近的k个点作为近邻,只有和样本距离最近的k个点之间的wij>0
。但是这种方法会造成重构之后的邻接矩阵W非对称,而后面的算法一定需要对称邻接矩阵。
为了解决这种问题,一般采取下面两种方法:

c.全连接法:相比前两种方法,第三种方法所有的点之间的权重值都大于0,因此称之为全连接法。可以选择不同的核函数来定义边权重,常用的有多项式核函数,高斯核函数和Sigmoid核函数。最常用的是高斯核函数RBF,此时相似矩阵和邻接矩阵相同:
。
附加的两个点的就是:正如b中所讨论的,相似的衡量可能不是对称的但是必须保证每个元素非负,有一种再得到相似矩阵后,构造出对称的邻接矩阵方式是:。此外,还要注意一点的是,正如c中所表示的,在谱聚类中,邻接矩阵的每两个结点都可能有相似度,它虽然很小,但不一定必须是0,这和图论中标准定义下的邻接矩阵有点区别:
有没有边连接导致对应的邻接矩阵元素是否必然为0。
(2)拉普拉斯矩阵:(标准定义:带权无向,权值非负)
拉普拉斯矩阵的定义:(D就是度矩阵,W就是邻接矩阵。
L的相关性质如下:
a.对于任意的向量,
公式太丑,看一个简单的例子:
假设我们有一个图(全连通),它的,
因为W=,右边
b.由a可知,L对称半正定,特征值是大于等于0的实数。
证明如下:记,当
。
c.当L是全连通图时,特征值为0对应的特征向量是。证明如下:
在b的基础上,由a的右边可知:,利用之前指示向量的定义,令
。
d.L中特征值为0的个数等于L中连通分量的个数,特征值为0的特征空间的基是:
。
证明思路:1)当全连通时,特征向量是. 2)当有连通分量时,将L分块成每一块连通分量对应的拉普拉斯矩阵,然后证明即可。
总结就是:当L是图论标准定义下拉普拉斯矩阵时,它的0特征值个数表示有多少个连通分量,0所对应的特征指示向量说明了哪些结点在当前的连通分量中。
到这里,我们就已经可以完成聚类的目的了。对样本的聚类可以把它看成对样本所构成的图分成多个连通分支,用上述的方法,每一个类对应于一个连通分量。但是这种解释还是不鲁棒,因为在实际的谱聚类中,邻接矩阵(全联通)并不是完全对应于图论中的标准定义,所以有更深入的解释。
(3)切图方法:对于谱聚类更深入的分析
定义:对于任意两集合,定义A,B之间的切图权重:
。
对于k个集合,定义切图
。一个例子:

我们的图如上图,则邻接矩阵为,记
,
所以切图,
,就是矩阵
中右上角标有圆圈的元素之和。
同理,对应的求和元素是
中有圈的。
,对应的求和元素是
中有圈的。
如果聚类的目标是最小化切图函数,是有问题的?为什么呢?因为cut没有考虑子图的规模,比较直观的例子就是:
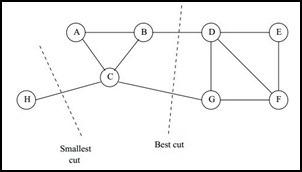 ,smallest不是best.所以在考虑切图方法时,还需要考虑结点集合本身的规模(即本文开头所定义的
,smallest不是best.所以在考虑切图方法时,还需要考虑结点集合本身的规模(即本文开头所定义的)。根据所选用的不同的规模衡量函数,有RatioCut和Ncut两种切图方式。下面逐一介绍:
a.RatioCut:
RatioCut所考虑的最小划分函数是:,
指示向量重新定义为:
,
表示第j类的指示向量的第i个分量。
对于每一个h,
。
而对于所有的指示向量,有.
。
此外注意到。
综上所述,问题就变成了一个优化问题:。
利用拉格朗日乘子法求得:,即H就是L中k个最小特征值所对应的特征向量(按列向量形式组成的矩阵)。
使用RatioCut时,先计算L的k个特征向量,按行进行归一化。
b.Ncut:
NCut所考虑的最小划分函数是:,
指示向量定义为:
则问题可以转换为:。
,所以令
,将
带入目标函数,得到
。其中
称为归一化的拉普拉斯矩阵(记作
)。当使用Ncut时,先计算归一化拉普拉斯矩阵的特征向量F,然后按行标准化F,(注意,此时并不需要算出H),标准化后,再进行一次kmeans聚类即可。
(4)算法流程与代码:
本文参考:
(1)A Tutorial on Spectral Clustering Ulrike von Luxburg