之前看了一些介绍语义分割的论文,但是没有记笔记,因为想把时间花在跑模型,增强工程能力上。现在参照别人的文章,把看过的几篇论文做一个简单的总结。
1. FCN
网络结构如下图,即输入图片通过CNN网络提取特征,之后经过上采样,将特征恢复成原图大小,从而达到像素级别的分割:
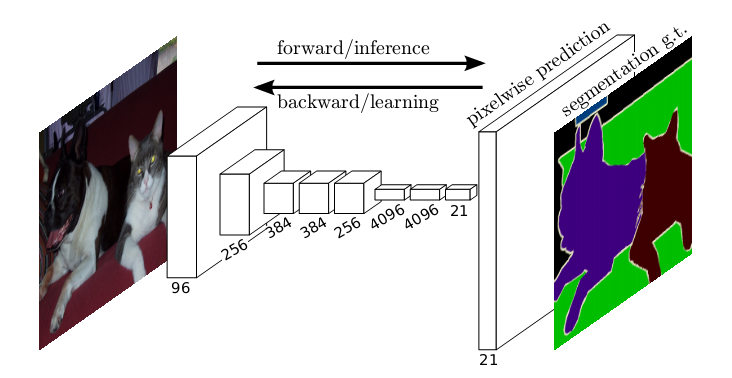
全卷积网络,有三个特点:
1. 将全连接层替换为全卷积层,即最后一层是通过卷积生成,1*1*2046个特征,而非直接变成全连接层。 我理解去掉全连接层好处是,卷积层可以对任意大小的feature map 进行卷积,从而最开始输入的图片大小就可变了。而全连接层由于计算方法的区别,必须对输入的feature map进行统一大小,不然就无法计算。其他方面应该是一样的。可以自己手推一下。如图所示,将全连接层替换为全卷积层
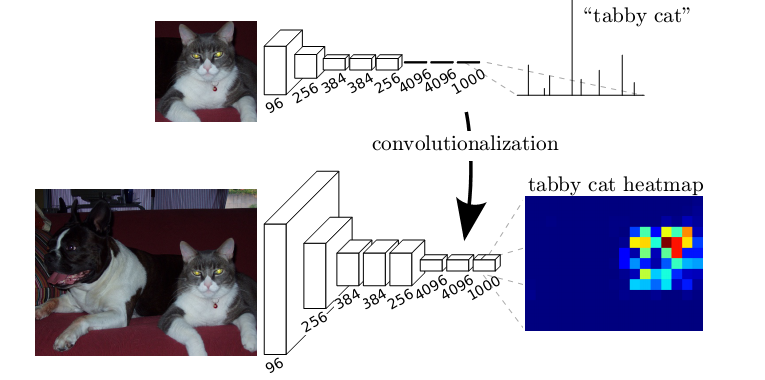
2. 上采样。我觉得这点很重要,将提取的高维抽象特征,经过上采样恢复成原图大小,各个channel再叠加起来,完成了像素级别的特征提取。上采样方法和CNN 反向传播求梯度时的上采样方法一样, 此处可参考其他人手推的BP算法在CNN网络中的实现。这个实现很重要,有必要自己学会如何手推。
3. 跨层连接。这点没什么好说的,目的就是通过获取多层特征,从而对feature的还原度好一点。论文实现了32倍,16倍和8倍上采样(三种框架),上采样方法如下图所示.
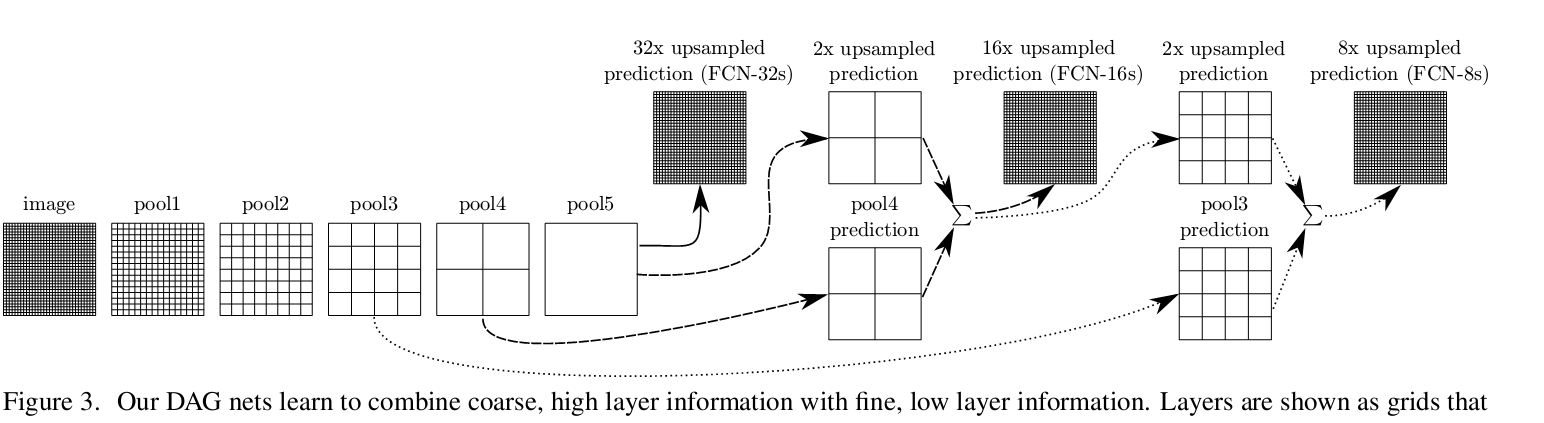
下图是3种倍数的上采样的分割效果,可以看到8倍上采样的分割效果最好。论文里也尝试融合更多层特征,之后再上采样,但是改善效果不大

损失函数,参照我上一篇博客相关介绍:

2. U-net
这个框架经常被用来进行Kaggle比赛,用作baseline,应该是因为模型简单,非常快,用少量图像也训练得比较好。而且最开始也是用作医学图像标记的,对小物体效果也很好。不过现在已将发展到DeepLab V3及Mask-RCNN了,我觉得后面两个模型更好。
下图就是网络结构。由此也可以看出来为毛要叫U-net了。对FCN的一种改进吧,上采样过程中融合了更多层的原feature map的信息,同时注意是通过增加channel的方式来进行的融合,先裁剪成2*2,之后按通道加到上采样后的通道中,而非FCN的直接求和来叠加feature map的信息。这点可以从channel数量看出来。通道数很大,这样可以将上下文信息传到分辨率更高的层中去。
左边是下采样,不断提取特征,同时分辨率下降,右边是上采样,增大分辨率,同时融合原feature map信息,目的是增强位置信息。因为越抽象到高层,特征所表达的位置信息就越若。增加底层的feature map的信息,就可增强上下文信息。这点下一篇博客会专门写一下相关网络架构。

说一下其损失函数的定义。这个定义的损失函数比价复杂,原因是为了将相互接触的目标分开,是按照位置赋予像素一个权重,对比机器学习KNN及线性分类器及SVM这种,很像按高斯核来确定的一个权重。毕竟细胞是相互接触的,实际Kaggle中用的U-net损失函数定义和其他无区别,因为比赛重叠的物体很少。
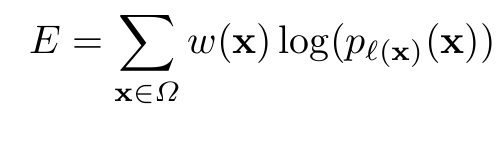
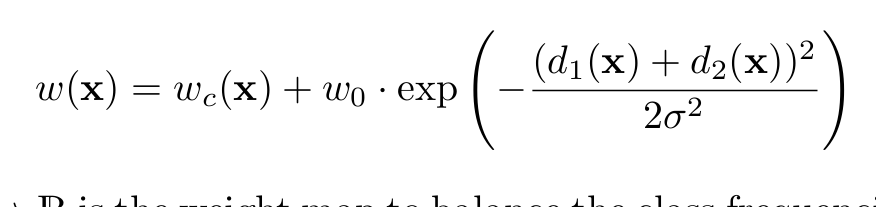
3. Segnet
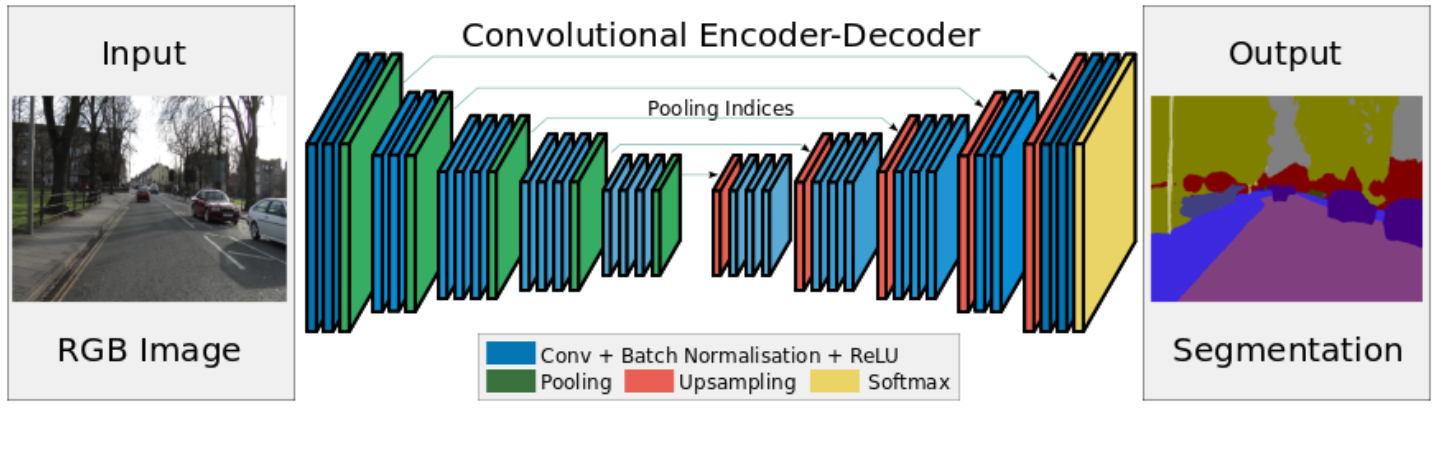
没什么好说的,看网络结构,感觉和U-net很像,都是编码解码过程,而且看后面感觉也没什么人用,就没怎么看。创新点是池化过程中记住了位置信息,上采样时按位置信息恢复可以更好还原图像。 我本来以为之前所有的都是按这种形式做得,这个以后有时间要看下tensorflow的源码上采样实现过程了
4. Deeplab系列
deeplabv1&v2
Deeplab讲一下空洞卷积的概念。其实后面是用条件随机场做过图像处理,增强图像位置信息,但是条件随机场,概率图这部分看着头大,公式推过几遍,但是当时学的时候没有用到什么算法实例,而且DeeplabV3把这部分也去掉了,就先不写。下面就是整体的流程。j简单讲一下v1,v2,其实也没怎么看。感觉不如直接讲V3和V3+。
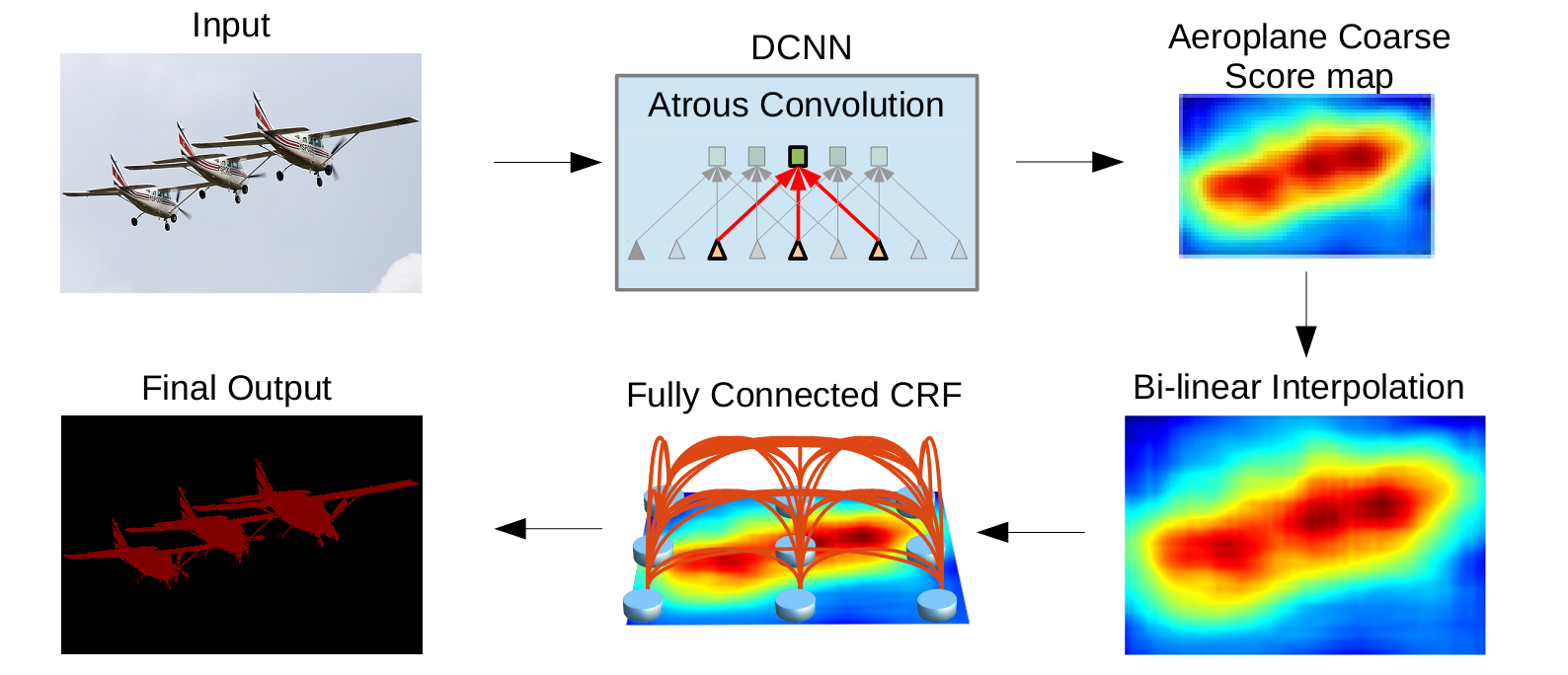
空洞卷积的引入就是在不减小分辨率的情况下增加感受野。上一篇博客讲过。空洞率rate就是空洞的个数+1. 可以看到对相个数同的像素点进行卷积操作,空洞卷积的感受野明显增大。

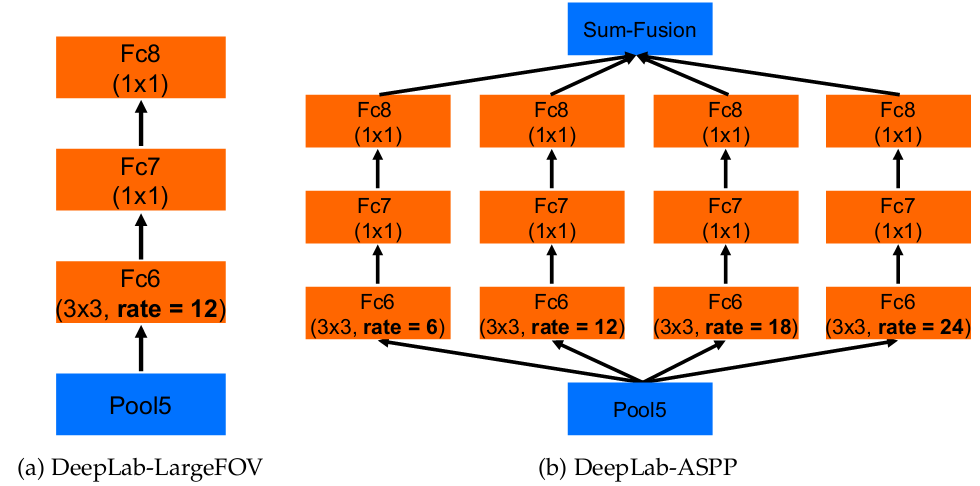
Deeplab V2相比V1其实就是增加了使用不同空洞率的卷积核来进行卷积,就好像增加了不同尺度的feature map,之后对这些进行了融合。没仔细看,不讲了,简单如下图

Deeplab V3
感觉相比前两种,V3改进就是尝试了ASPP模块的改进,基础网络还是resnet。V3和V3+这两篇论文比较重要,也看了源码,但是暂时没时间仔细看,看完源码之后再写篇博客专门写一下。
最开始,如图所示有以下几种级联方式。
1.不同尺寸的图像进行输入,之后将feature map融合进来。常见于人脸检测中。
2. 编码解码方式。比如U-net
3. 串联结构
4.并联结构
后两种结构均在本文做了尝试
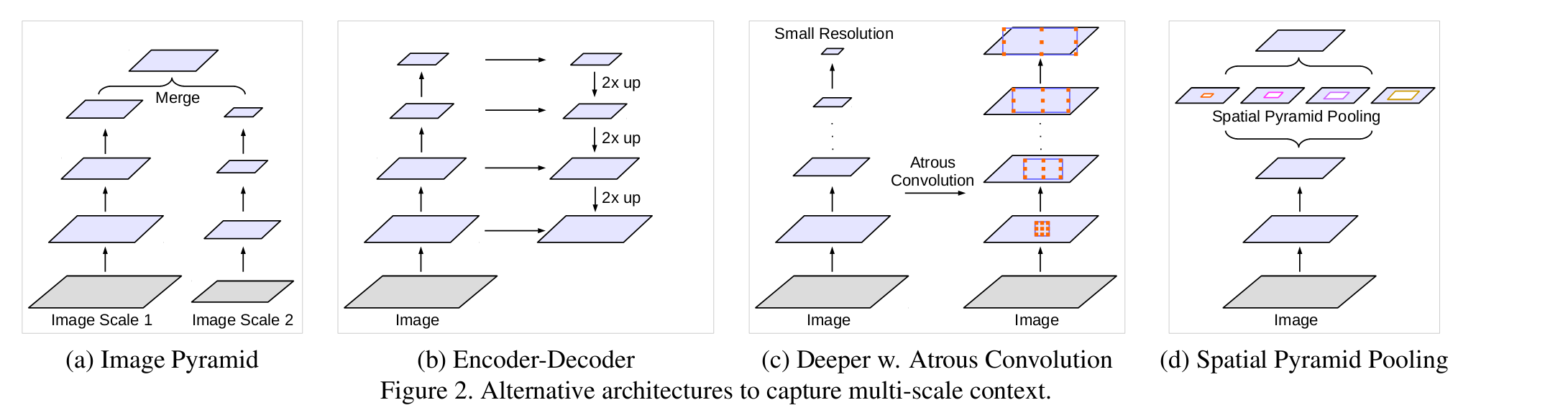
并联方式改进如下,增加了1*1的卷积和全局池化层。1*1卷积可以看成空洞rate特别大的卷积,而image pooling 相当于对全局图片进行平均池化,成为一个点,之后经过一个1*1的卷积后,采用双线性差值进行上采样:

论文也尝试过串联结构,但是貌似效果不好?

DeeplabV3+
18页的论文,真是。。太麻烦了。其实就两点,对DeeplabV3的进一步优化,加入了编码解码结构。ASPP结构是编码,后续上采样加入了底层的featur map信息,目的是增强位置敏感性?第二点就是基础模型的改进。。
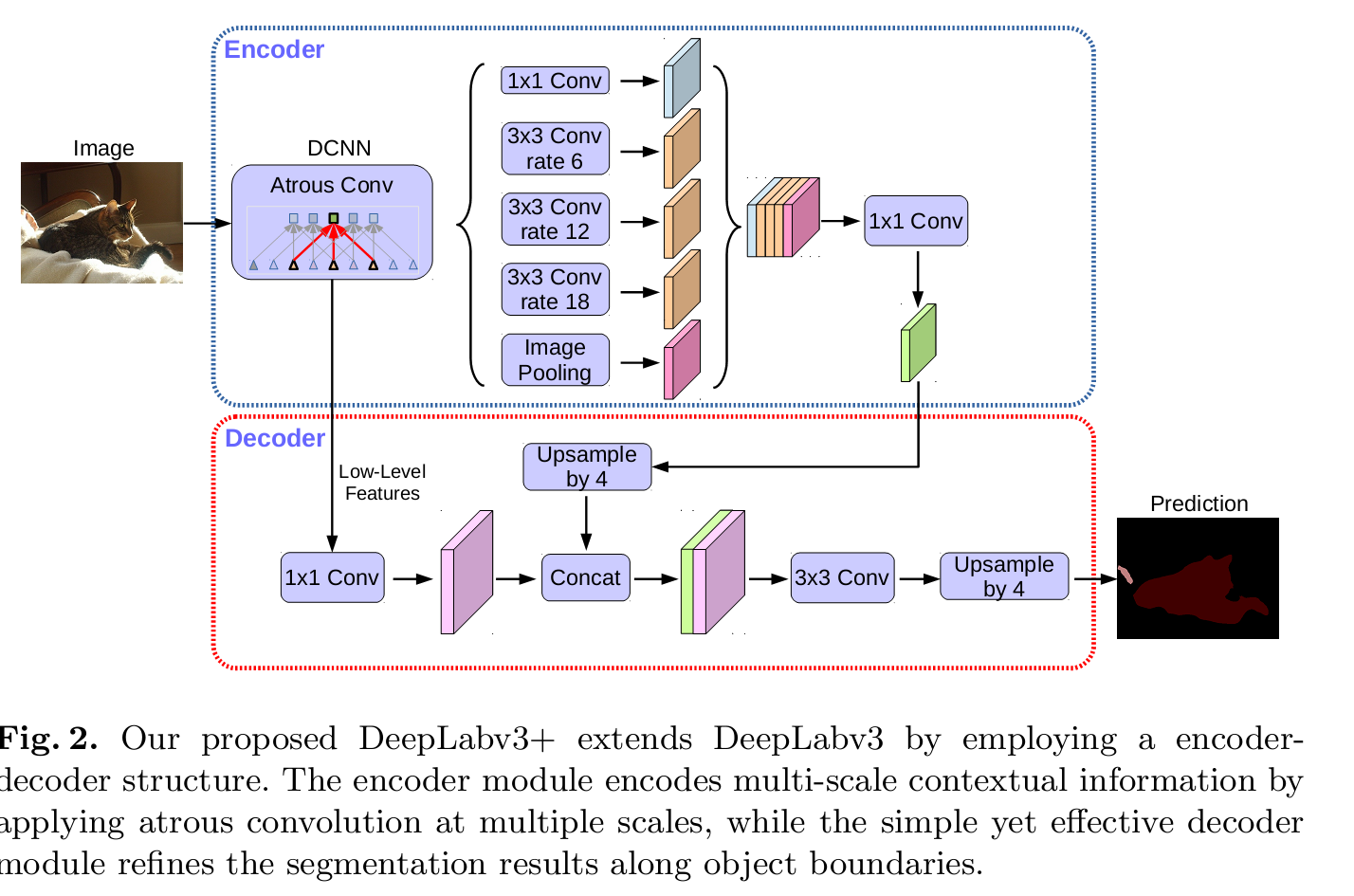
网络结构不再是Resnet,变成了Xception.不会的可以参考下其他人的博客。。我下一篇也会写这个模型。。。
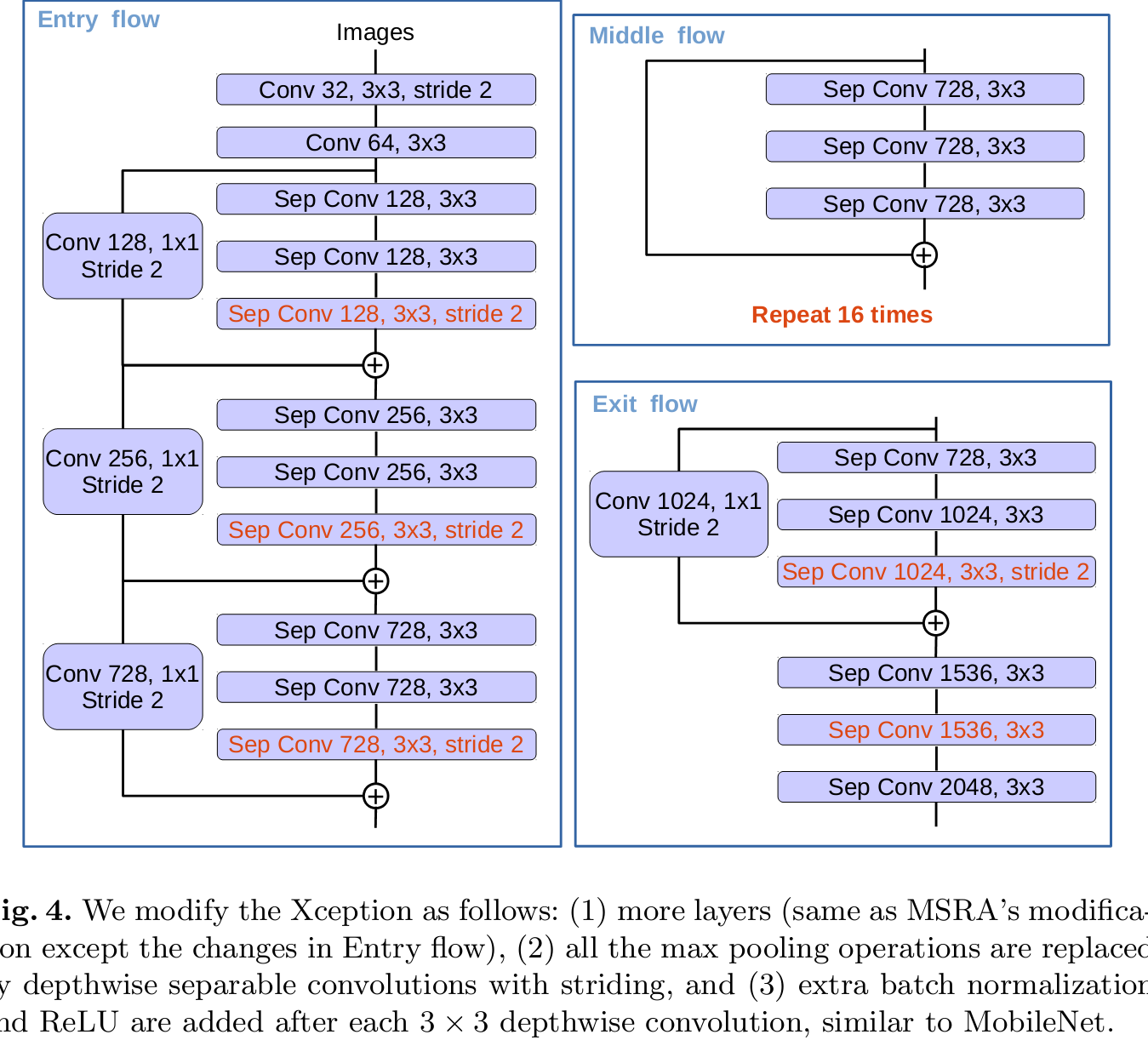
Deeplab系列就这样吧。这一系列看的有点着急,而且是好久之前看的重新写心得,其实很有必要实现下源码增强理解。。下周会写一份源码的阅读记录。。。
PSPnet
PSPnet其实在DeeplapV3之前,DeeplabV3就是吸取了它的global pooling层的特点做得一个改进。global pooling的意义就是吸取不同尺度的特征信息,也包含了位置的信息。经过不同尺度的global pooling,形成1*1,2*2,3*3和6*6后的feature map,之后卷积,减小通道个数。在进行上采样(双线性差值方法)和未经过pooling的层进行融合。进行分割。整体过程如下图:

Large Kernel matters
大卷积有利于掌握全局信息,但是前面global pooling和1*1会损失位置信息,且单纯大卷积会造成计算量大,所以本文采用了GCN形式,且通过残差模块来提高边缘信息。我不是很理解GCN是怎么实现的,难道padding是使用的same padding?没有看源码,只看了下大致的结构。流程如下,看到增加的新模块是GCN和BR结构。

Refinet 没看,以后再补上
Mask-RCNN
Mask-RCNN是很厉害的一个网络了,这个的源码是必须要看的。而且在Kaggle比赛中也有用这个打比赛的,效果很好。整体还从语义分割直接连接到的实例分割的层次,即有目标检测加语义分割两个的融合。
对Fster-RCNN的改进:
1. 增加mask分支,增加像素级别分类。采用了FCN结构,效果反映在loss函数上对预测目标的进一步优化结构如下:


loss函数如下,对每一个像素预测一个二值掩膜,即0,1。即对每一个RPN预测K(类别)个m*m个值,每个类别损失函数单独算。m*m个2值,由此来计算损失:

2. 对池化进行了优化,采用ROIalign,即使用线性插值方法对池化操作进行优化,目的是达到像素级别的对准。感觉这个很早就用在了语义分割里?具体如下:

这套方案将目标检测和语义分割结合起来,不是单独的用像素块标记出物体,同时还可以告诉你这个像素块属于哪一种类别。结果如下:
