一.简介(类似于传销,用某个数据q去发展下线p,p再去发展下线)
DBSCAN是聚类算法,优于kmeans,首选DBSCAN。
DBSCAN基于密度的、带有噪音的聚类。
![]()

二.算法需要记住的概念
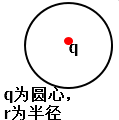
①相关概念:核心点
数据q为圆心,r(超参)为半径画圆,圆内数据多余m个(超参),那么数据q为核心点。如下图:
②相关概念:直接密度可达;密度可达

======================密度可达=================

三.算法参数
参数:半径,半径内点的个数。不需要设置kmeans中的k值,自动聚成簇。到底聚成多少堆,由算法实际聚出来的。
半径r的经验值是:突变点,点q到所有点的距离d1、d2、d3、……dn,从小到大进行排序,突然d4变的很大,d3就作为半径。