---恢复内容开始---
一 python Threading模块与线程
multiprocess模块完全模仿了threading模块的接口,二者在使用层面有较大的相似处。
1. 线程的创建


from threading import Thread def func(m): print(m) if __name__ == '__main__': f = Thread(target=func,args=(1,)) #创建一个线程对象 f.start() print('主进程结束')
from threading import Thread class Mythread(Thread): def __init__(self,m): super().__init__()#继承Thread模块的init self.m = m def run(self): print('拉拉爱了') def norun(self): #还可以写其他的方法 print('啦啊的') if __name__ == '__main__': m = Mythread('e') #传递自己的变量 m.start() m.norun()
2.多线程和多进程运行的效率对比
ort time from threading import Thread from multiprocessing import Process def func(): pass if __name__ == '__main__': t_list = [] t_s_t = time.time() for i in range(100): t = Thread(target=func,) t_list.append(t) t.start() [tt.join() for tt in t_list]#等待子程序 t_e_t = time.time() t_dif_t = t_e_t - t_s_t p_list = [] p_s_t = time.time() for i in range(100): p = Process(target=func,) p_list.append(p) p.start() [pp.join() for pp in p_list]#等待子程序 p_e_t = time.time() p_dif_t = p_e_t - p_s_t print('多线程的时间>>>',t_dif_t)#0.025949478149414062 print('多进程的时间>>>',p_dif_t)#7.810645341873169 print('主线程结束')
3 多线程数据共享
import time from threading import Thread num = 100 def func(): # time.sleep(3) global num tep = num time.sleep(0.001) tep = tep - 1 num = tep # num -= 1 if __name__ == '__main__': t_list = [] for i in range(100): t = Thread(target=func,) t_list.append(t) t.start() [tt.join() for tt in t_list] print('主线程的num',num) #87 由于共享时会争抢数据并没有变为0
import time from threading import Thread,Lock num = 100 def func(tl): time.sleep(1) global num tl.acquire() tep = num time.sleep(0.001) tep = tep - 1 num = tep tl.release() if __name__ == '__main__': tl = Lock() t_list = [] for i in range(10): t = Thread(target=func,args=(tl,)) t_list.append(t) t.start() [tt.join() for tt in t_list] # t.join() print('主线程的num',num)
4 守护线程守护进程
import time from threading import Thread from multiprocessing import Process def func1(): time.sleep(3) print('任务1结束') def func2(): time.sleep(2) print('任务2结束') if __name__ == '__main__': p1 = Process(target=func1,) p2 = Process(target=func2,) #守护进程:主进程代码结束,守护进程结束,由于程序具有回收机制,所以要等待非守护子进程执行完,才结束。 p1.daemon = True # p2.daemon = True p1.start() p2.start() t1 = Thread(target=func1,) t2 = Thread(target=func2,) t1.daemon = True t2.setDaemon(True) #将t2设置为守护线程 #守护线程:主程序等所有非守护线程结束才结束 t1.setDaemon(True) #将t1设置为守护线程 t1.start() t2.start() print('主进程结束')
5 信号量
import time import random from threading import Thread,Semaphore def func1(i,s): s.acquire() # time.sleep(1) print('客官%s里边请~~'%i) time.sleep(random.randint(1, 3)) s.release() if __name__ == '__main__': s = Semaphore(4) for i in range(10): t = Thread(target=func1,args=(i,s)) t.start()
6 事件
事件的
from threading import Thread,Event e = Event() #默认是False, # print(e.isSet()) print('开始等啦') e.set() #将事件对象的状态改为True print(e.isSet()) # e.clear() #将e的状态改为False e.wait() #如果e的状态为False,就在这里阻塞 print('大哥,还没完事儿,你行')
7 线程队列
import queue #先进先出队列 q = queue.Queue(3) q.put('first') q.put('second') q.put(3) # q.put(6) #队列长度为3 当放过超过这个长度时程序就会一直等待前面的元素被拿 # 此时就可以用put_nowait()配合try来使用 try: q.put_nowait(3) except: print('队列满了') # print(q.qsize())#队列长度 print(q.get()) print(q.get()) print(q.get()) try: print(q.get_nowait()) except: print('队列没有了') import queue #先进后出队列 q = queue.LifoQueue() q.put(1) q.put(2) q.put(3) print(q.get()) #3 print(q.get())#2 print(q.get())#1 import queue q = queue.PriorityQueue()#自定义排序 q.put((0,10)) q.put((-1,4)) q.put((6,9)) print(q.get())#(-1, 4) print(q.get())#(0, 10) print(q.get())#(6, 9)
8 线程池
import time from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor #上面导入的是线程池和进程池(另外一种导入法) from multiprocessing import Pool def func(n): time.sleep(1) # print(n*n) return n*n if __name__ == '__main__': t = ThreadPoolExecutor(4) # p = ProcessPoolExecutor(4) #创建进程池,其他的方法完全一样 res_lis = [] for i in range(10): res = t.submit(func,i) #异步提交线程,拿到结果对象 # print(res.result()) #等待结果阻塞,拿到就再执行下一个循环,串行 res_lis.append(res) t.shutdown() # 放在此处此时所有结果对象都有结果直接全部拿到 for res in res_lis: print(res.result()) # t.shutdown() # 等待子线程结束,和进程里面close()+join()差不多,此时上面for结果会四个四个打印结果 print('主进程结束') # 进程池 # if __name__ == '__main__': # p = Pool(4) # for i in range(10): # res = p.apply_async(func,(i,)) # print(res.get())
9 线程池的map方法
import time from concurrent.futures import ThreadPoolExecutor def func(n): # print(n) time.sleep(1) return n*n if __name__ == '__main__': t = ThreadPoolExecutor(4) res = t.map(func,range(10))#只是提交任务主程序不会等待 for m in res: #生成器对象 print(m) print('主进程结束')
10 线程池,进程池的返回函数
import time from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor from multiprocessing import Pool def func(n): return n*n def call_back(i): print('>>>>',i) print(i) if __name__ == '__main__': # p = Pool(4) t = ThreadPoolExecutor(4) p = ProcessPoolExecutor(4) lis = [] for i in range(10): #线程池的方法 res = t.submit(func,i).add_done_callback(call_back) lis.append(res) #返回的都是结果对象 for i in lis: print(i.result()) for i in range(10): # 进程池的方法 res = t.submit(func,i).add_done_callback(call_back) for i in range(10): res = p.apply_async(func,(i,),callback=call_back) print(res.get()) # p.close() # p.join() print('sssss')
二 GIL锁
Gil锁(Global Interpreter Lock)
python全局解释器锁,有了这个锁的存在,python解释器在同一时间内只能让一个进程中的一个线程去执行,这样python的多线程就无法利用多核优势,但是这并不是python语言本身的缺点,是解释器的缺点,这个问题只存在于Cpython解释其中,像Jpython就没有。但是Cpthon是python官方解释器(算目前运行效率最高的吧),所以多数人都以为Gil锁是python语言的弊端。
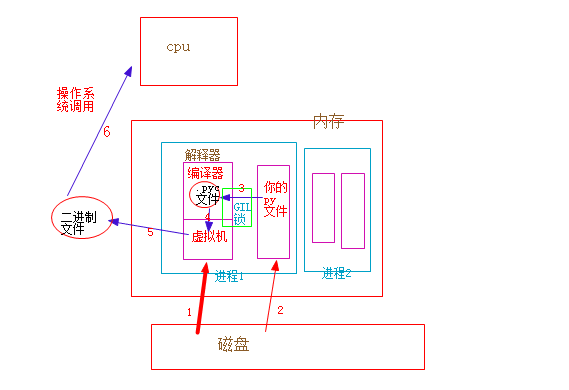
过程解释:
1、加载python解释器代码
2、加载自己的py文件
3、py文件作为参数传给解释器(因为有GIL锁,一次只能一个线程进入)
4、解释器将py文件编译成.pyc字节码文件
5、解释器通过虚拟机将字节码文件转为二进制文件
6、二进制文件等待cpu调用
---恢复内容结束---