pytorch中数据加载和处理实例
**A lot of effort in solving any machine learning problem goes in to preparing the data. PyTorch provides many tools to make data loading easy and hopefully, to make your code more readable. we will see how to load and preprocess/augment data from a non trivial dataset.**在处理任何机器学习问题需付出很大努力的是准备数据,pytorch提供了许多能够轻松愉快制作数据的工具。我们将看到如何从一个重要的数据集加载和预处理/增强数据。
- scikit-image: For image io and transforms
- pandas: For easier csv parsing
首先安装sklearn库和pandas
加载一些库
from __future__ import print_function, division
import os
import torch
import pandas as pd
from skimage import io, transform
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
# Ignore warnings
import warnings
warnings.filterwarnings("ignore")
plt.ion() # interactive mode
The dataset we are going to deal with is that of facial pose. This means that a face is annotated like this:我们要处理的数据集是面部姿势的数据集。这意味着一张脸是这样标注的:
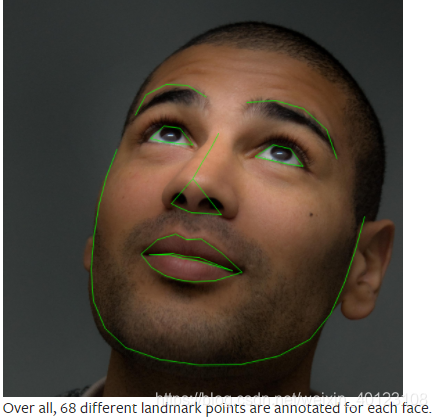
Download the dataset from here so that the images are in a directory named ‘faces/’. This dataset was actually generated by applying excellent dlib’s pose estimation on a few images from imagenet tagged as ‘face’.
从这里下载数据集,以便图像位于名为“faces/”的目录中。该数据集实际上是通过对一些标记为“face”的imagenet图像应用优秀的dlib位姿估计生成的。
数据集的标记如下所示:首先是图像名称,后是34个点(包含x,y所以有68个)
image_name,part_0_x,part_0_y,part_1_x,part_1_y,part_2_x, … ,part_67_x,part_67_y
0805personali01.jpg,27,83,27,98, … 84,134
1084239450_e76e00b7e7.jpg,70,236,71,257, … ,128,312
**
- 读取csv数据集的标签以及名称(把从上边下载的数据集放入运行路径下)
**
landmarks_frame = pd.read_csv('faces/face_landmarks.csv')
n = 0#第一个数据
img_name = landmarks_frame.iloc[n, 0]
landmarks = landmarks_frame.iloc[n, 1:].as_matrix()
landmarks = landmarks.astype('float').reshape(-1, 2)
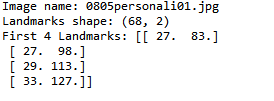
print('Image name: {}'.format(img_name))
print('Landmarks shape: {}'.format(landmarks.shape))
print('First 4 Landmarks: {}'.format(landmarks[:4]))
名称和前四个标记点
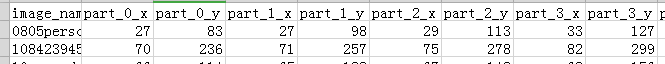
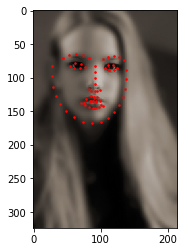
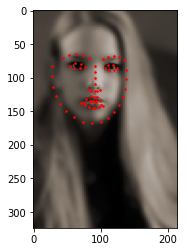
2. 让我们编写一个简单的函数来显示图像及其标记,并使用它来显示示例。
def show_landmarks(image, landmarks):
"""Show image with landmarks"""
plt.imshow(image)
plt.scatter(landmarks[:, 0], landmarks[:, 1], s=10, marker='.', c='r')
plt.pause(0.001) # pause a bit so that plots are updated
plt.figure()
show_landmarks(io.imread(os.path.join('faces/', img_name)),
landmarks)
plt.show()
**
3. 定义一个数据集类
**
*torch.utils.data.Dataset is an abstract class representing a dataset. Your custom dataset should inherit Dataset and override the following methods:*torch.utils.data数据集是表示数据集的抽象类。自定义数据集应该继承数据集并覆盖以下方法:
len so that len(dataset) returns the size of the dataset.测量数据集的size
getitem to support the indexing such that dataset[i] can be used to get iith sample用·数据集的索引的得到数据集例子
定义一个类
class FaceLandmarksDataset(Dataset):
"""Face Landmarks dataset."""
def __init__(self, csv_file, root_dir, transform=None):
"""
Args:
csv_file (string): Path to the csv file with annotations.
root_dir (string): Directory with all the images.
transform (callable, optional): Optional transform to be applied
on a sample.
"""
self.landmarks_frame = pd.read_csv(csv_file)
self.root_dir = root_dir
self.transform = transform
def __len__(self):
return len(self.landmarks_frame)
def __getitem__(self, idx):
img_name = os.path.join(self.root_dir,
self.landmarks_frame.iloc[idx, 0])
image = io.imread(img_name)
landmarks = self.landmarks_frame.iloc[idx, 1:].as_matrix()
landmarks = landmarks.astype('float').reshape(-1, 2)
sample = {'image': image, 'landmarks': landmarks}
if self.transform:
sample = self.transform(sample)
return sample
4. 实例化这个类并遍历数据示例。我们将打印前4个样品的尺寸并显示它们的标记。
face_dataset = FaceLandmarksDataset(csv_file='faces/face_landmarks.csv',
root_dir='faces/')
fig = plt.figure()
for i in range(len(face_dataset)):
sample = face_dataset[i]
print(i, sample['image'].shape, sample['landmarks'].shape)
ax = plt.subplot(1, 4, i + 1)
plt.tight_layout()
ax.set_title('Sample #{}'.format(i))
ax.axis('off')
show_landmarks(**sample)
if i == 3:
plt.show()
break

0 (324, 215, 3) (68, 2)
1 (500, 333, 3) (68, 2)
2 (250, 258, 3) (68, 2)
3 (434, 290, 3) (68, 2)
5. transform
从上面我们可以看到一个问题,样品的尺寸不一样。大多数神经网络期望得到固定大小的图像。因此,我们需要编写一些预处理代码。让我们创建三个转换:
Rescale: to scale the image
RandomCrop: to crop from image randomly. This is data augmentation.
ToTensor: to convert the numpy images to torch images (we need to swap axes).
tsfm = Transform(params)
transformed_sample = tsfm(sample)
观察这些变换是如何应用于图像和标记的。
class Rescale(object):
"""Rescale the image in a sample to a given size.
Args:
output_size (tuple or int): Desired output size. If tuple, output is
matched to output_size. If int, smaller of image edges is matched
to output_size keeping aspect ratio the same.
"""
def __init__(self, output_size):
assert isinstance(output_size, (int, tuple))
self.output_size = output_size
def __call__(self, sample):
image, landmarks = sample['image'], sample['landmarks']
h, w = image.shape[:2]
if isinstance(self.output_size, int):
if h > w:
new_h, new_w = self.output_size * h / w, self.output_size
else:
new_h, new_w = self.output_size, self.output_size * w / h
else:
new_h, new_w = self.output_size
new_h, new_w = int(new_h), int(new_w)
img = transform.resize(image, (new_h, new_w))
# h and w are swapped for landmarks because for images,
# x and y axes are axis 1 and 0 respectively
landmarks = landmarks * [new_w / w, new_h / h]
return {'image': img, 'landmarks': landmarks}
class RandomCrop(object):
"""Crop randomly the image in a sample.
Args:
output_size (tuple or int): Desired output size. If int, square crop
is made.
"""
def __init__(self, output_size):
assert isinstance(output_size, (int, tuple))
if isinstance(output_size, int):
self.output_size = (output_size, output_size)
else:
assert len(output_size) == 2
self.output_size = output_size
def __call__(self, sample):
image, landmarks = sample['image'], sample['landmarks']
h, w = image.shape[:2]
new_h, new_w = self.output_size
top = np.random.randint(0, h - new_h)
left = np.random.randint(0, w - new_w)
image = image[top: top + new_h,
left: left + new_w]
landmarks = landmarks - [left, top]
return {'image': image, 'landmarks': landmarks}
class ToTensor(object):
"""Convert ndarrays in sample to Tensors."""
def __call__(self, sample):
image, landmarks = sample['image'], sample['landmarks']
# swap color axis because
# numpy image: H x W x C
# torch image: C X H X W
image = image.transpose((2, 0, 1))
return {'image': torch.from_numpy(image),
'landmarks': torch.from_numpy(landmarks)}
6. Compose transforms
Now, we apply the transforms on an sample.
Let’s say we want to rescale the shorter side of the image to 256 and then randomly crop a square of size 224 from it. i.e, we want to compose Rescale and RandomCrop transforms. torchvision.transforms.Compose is a simple callable class which allows us to do this.
现在,我们对一个样本进行变换。
假设我们想将图像的短边缩放到256,然后从其中随机裁剪一个224大小的正方形。我们想组合缩放和随机裁剪变换。torchvision.transforms。Compose是一个简单的可调用类。
scale = Rescale(256)
crop = RandomCrop(128)
composed = transforms.Compose([Rescale(256),
RandomCrop(224)])
# Apply each of the above transforms on sample.
fig = plt.figure()
sample = face_dataset[65]
for i, tsfrm in enumerate([scale, crop, composed]):
transformed_sample = tsfrm(sample)
ax = plt.subplot(1, 3, i + 1)
plt.tight_layout()
ax.set_title(type(tsfrm).__name__)
show_landmarks(**transformed_sample)
plt.show()

**
7. ITERATING THROUGH THE DATASET遍历数据集
**
transformed_dataset = FaceLandmarksDataset(csv_file='faces/face_landmarks.csv',
root_dir='faces/',
transform=transforms.Compose([
Rescale(256),
RandomCrop(224),
ToTensor()
]))
for i in range(len(transformed_dataset)):
sample = transformed_dataset[i]
print(i, sample['image'].size(), sample['landmarks'].size())
if i == 3:
break
为了方便加批处理、打乱数据、使用多处理器并行加载数据。
使用函数torch.utils.data.DataLoader
dataloader = DataLoader(transformed_dataset, batch_size=4,
shuffle=True, num_workers=4)
# Helper function to show a batch
def show_landmarks_batch(sample_batched):
"""Show image with landmarks for a batch of samples."""
images_batch, landmarks_batch = \
sample_batched['image'], sample_batched['landmarks']
batch_size = len(images_batch)
im_size = images_batch.size(2)
grid = utils.make_grid(images_batch)
plt.imshow(grid.numpy().transpose((1, 2, 0)))
for i in range(batch_size):
plt.scatter(landmarks_batch[i, :, 0].numpy() + i * im_size,
landmarks_batch[i, :, 1].numpy(),
s=10, marker='.', c='r')
plt.title('Batch from dataloader')
for i_batch, sample_batched in enumerate(dataloader):
print(i_batch, sample_batched['image'].size(),
sample_batched['landmarks'].size())
# observe 4th batch and stop.
if i_batch == 3:
plt.figure()
show_landmarks_batch(sample_batched)
plt.axis('off')
plt.ioff()
plt.show()
break

0 torch.Size([4, 3, 224, 224]) torch.Size([4, 68, 2])
1 torch.Size([4, 3, 224, 224]) torch.Size([4, 68, 2])
2 torch.Size([4, 3, 224, 224]) torch.Size([4, 68, 2])
3 torch.Size([4, 3, 224, 224]) torch.Size([4, 68, 2])
来自官方网址