写在前面
Azkaban官网:https://azkaban.github.io/
1. azkaban简单介绍
Azkaban是由Linkedin公司推出的一个批量工作流任务调度器,主要用于在一个工作流内以一个特定的顺序运行一组工作和流程。Azkaban使用job配置文件建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流。 其Web UI界面如下图所示。
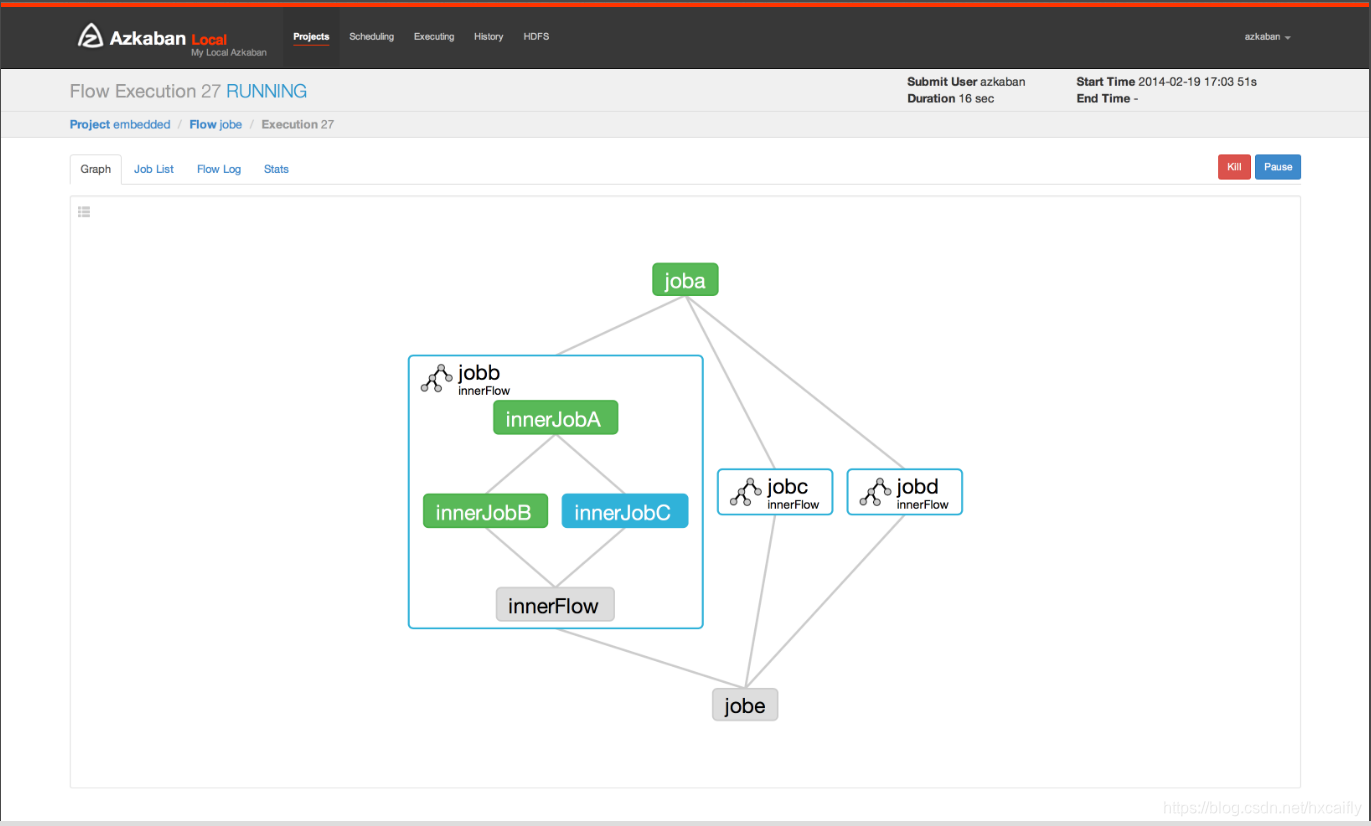
由于我们团队内部使用Java作为主流开发语言,并且Spark算子之间确实存在着依赖关系。我们选择Azkaban的原因基于以下几点:
- 提供功能清晰,简单易用的Web UI界面
- 提供job配置文件快速建立任务和任务之间的依赖关系
- 提供模块化和可插拔的插件机制,原生支持command、Java、Hive、Pig、Hadoop
- 基于Java开发,代码结构清晰,易于二次开发
- 提供了Restful接口,方面我们平台定制化。
2. Azkaban的适用场景
实际项目中经常有这些场景:每天有一个大任务,这个大任务可以分成A,B,C,D四个小任务,A,B任务之间没有依赖关系,C任务依赖A,B任务的结果,D任务依赖C任务的结果。一般的做法是,开两个终端同时执行A,B,两个都执行完了再执行C,最后再执行D。这样的话,整个的执行过程都需要人工参加,并且得盯着各任务的进度。但是我们的很多任务都是在深更半夜执行的,通过写脚本设置crontab执行。这样子很不好维维护。
其实,整个过程类似于一个有向无环图(DAG)。每个子任务相当于大任务中的一个流,任务的起点可以从没有度的节点开始执行,任何没有通路的节点之间可以同时执行,比如上述的A,B。总结起来的话,我们需要的就是一个工作流的调度器,而Azkaban就是能解决上述问题的一个调度器。
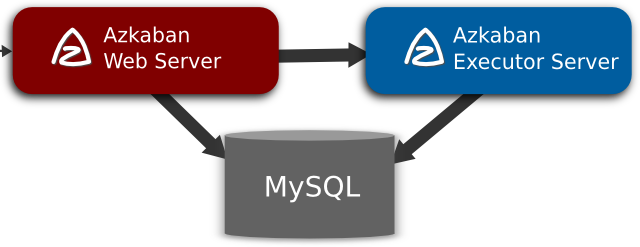
3. Azkaban架构
Azkaban在LinkedIn上实施,以解决Hadoop作业依赖问题。我们有工作需要按顺序运行,Spark各个算子之间有执行依赖关系,比如下一个算子执行的数据源依赖于上一个算子执行产生的结果数据。最初是单一服务器解决方案,随着多年来Hadoop用户数量的增加,Azkaban 已经发展成为一个更强大的解决方案。
Azkaban由三个关键组件构成:
- 关系型数据库(MySQL)
- AzkabanWebServer
- AzkabanExecutorServer
3.1 关系型数据库(MySQL)
Azkaban使用数据库存储大部分状态,AzkabanWebServer和AzkabanExecutorServer都需要访问数据库。
AzkabanWebServer使用数据库的原因如下:
- 项目管理:项目、项目权限以及上传的文件。
- 执行流状态:跟踪执行流程以及执行程序正在运行的流程。
- 以前的流程/作业:通过以前的作业和流程执行以及访问其日志文件进行搜索。
- 计划程序:保留计划作业的状态。
- SLA:保持所有的SLA规则
AzkabanExecutorServer使用数据库的原因如下:
- 访问项目:从数据库检索项目文件。
- 执行流程/作业:检索和更新正在执行的作业流的数据
- 日志:将作业和工作流的输出日志存储到数据库中。
- 交互依赖关系:如果一个工作流在不同的执行器上运行,它将从数据库中获取状态。
3.2 AzkabanWebServer
AzkabanWebServer是整个Azkaban工作流系统的主要管理者,它负责project管理、用户登录认证、定时执行工作流、跟踪工作流执行进度等一系列任务。同时,它还提供Web服务操作的接口,利用该接口,用户可以使用curl或其他ajax的方式,来执行azkaban的相关操作。操作包括:用户登录、创建project、上传workflow、执行workflow、查询workflow的执行进度、杀掉workflow等一系列操作,且这些操作的返回结果均是json的格式。并且Azkaban使用方便,Azkaban使用以.job为后缀名的键值属性文件来定义工作流中的各个任务,以及使用dependencies属性来定义作业间的依赖关系链。这些作业文件和关联的代码最终以*.zip的方式通过Azkaban UI上传到Web服务器上。
3.3 AzkabanExecutorServer
以前版本的Azkaban在单个服务中具有AzkabanWebServer和AzkabanExecutorServer功能,目前Azkaban已将AzkabanExecutorServer分离成独立的服务器,拆分AzkabanExecutorServer的原因有如下几点:
- 某个任务流失败后,可以更方便的将其重新执行
- 便于Azkaban升级
AzkabanExecutorServer主要负责具体的工作流的提交、执行,可以启动多个执行服务器,它们通过mysql数据库来协调任务的执行以及实现高可用性。
4. Azkaban作业流执行过程
Webserver根据内存中缓存的各Executor的资源状态(Webserver有一个线程会遍历各个active executor,去发送http请求获取其资源状态信息缓存到内存中),按照选择策略(包括executor资源状态、最近执行流个数等)选择一个executor下发作业流;executor判断是否设置作业粒度分配,如果未设置作业粒度分配,则在当前executor执行所有作业;如果设置了作业粒度分配,则当前节点会成为作业分配的决策者,即分配节点;分配节点从zookeeper获取各个executor的资源状态信息,然后根据策略选择一个executor分配作业;被分配到作业的executor即成为执行节点,执行作业,然后更新数据库。
5. Azkaban架构的三种运行模式
在版本3.0中,Azkaban提供了以下三种模式:
- solo server mode:最简单的模式,数据库内置的H2数据库,AzkabanWebServer和AzkabanExecutorServer都在一个进程中运行,任务量不大项目可以采用此模式。
- two server mode:数据库为MySQL,管理服务器和执行服务器在不同进程,这种模式下,AzkabanWebServer和AzkabanExecutorServer互不影响。
- multiple executor mode:该模式下,AzkabanWebServer和AzkabanExecutorServer运行在不同主机上,且AzkabanExecutorServer可以有多个。
大数据平台要求其具有高可用性,所以目前我们采用的是multiple executor mode方式,分别在不同的主机上部署多个AzkabanExecutorServer以应对高并发定时任务执行的情况,从而减轻单个服务器的压力。 下面是集群架构图:
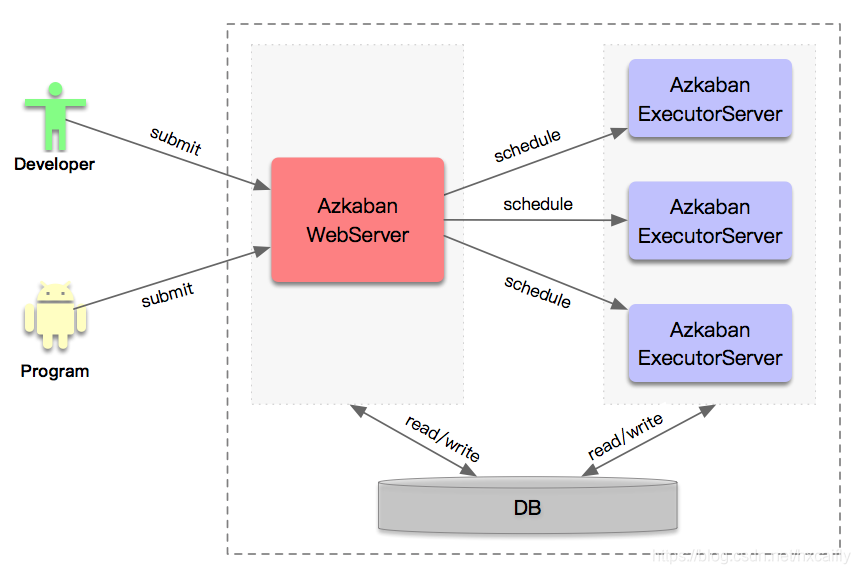
6.核心调度概述
Azkaban WebServer需要根据Executor Server的运行状态信息,选择一个合适的Executor Server来运行WorkFlow,然后会将提交到队列中的WorkFlow调度到选定的Executor Server上运行。我们整理了与核心调度相关的各个组件,主要包括Azkaban WebServer端和Azkaban ExecutorServer端,他们之间的关系如下图所示:
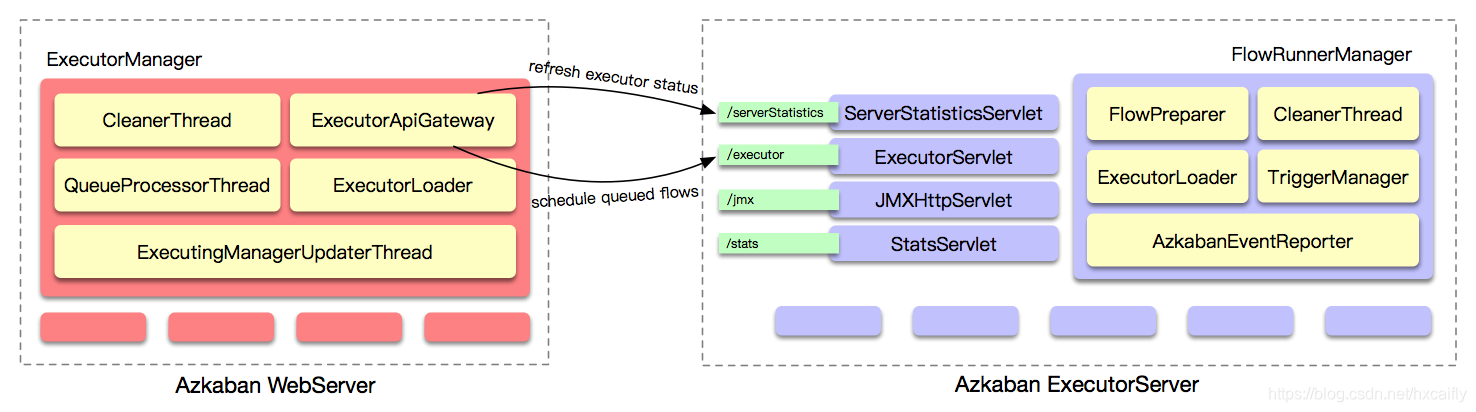
其实,从调度层面来看,Azkaban WebServer与Executor Server之间的交互方式非常简单,是通过REST API的方式来进行交互,基本的模式是,Azkaban WebServer根据调度的需要,主动调用Executor Server暴露的REST API来获取相应的资源信息,比如Executor Server的状态信息、分配WorkFlow到指定Executor Server上运行,等等。
我们可以在QueueProcessorThread.selectExecutorAndDispatchFlow()方法中看到,选择Executor Server并进行调度的实现,代码片段如下所示:
final Executor selectedExecutor = selectExecutor(exflow, availableExecutors);
if (selectedExecutor != null) {
try {
dispatch(reference, exflow, selectedExecutor);
ExecutorManager.this.commonMetrics.markDispatchSuccess();
} catch (final ExecutorManagerException e) {
ExecutorManager.this.commonMetrics.markDispatchFail();
logger.warn(String.format(
"Executor %s responded with exception for exec: %d",
selectedExecutor, exflow.getExecutionId()), e);
handleDispatchExceptionCase(reference, exflow, selectedExecutor,
availableExecutors);
}
}
QueueProcessorThread是运行在Azkaban WebServer端的一个线程,它在ExecutorManager中定义,是内部调度中最核心的线程。
selectExecutor()方法处理如何选择一个合适的Executor Server,然后通过dispatch()方法将需要运行的WorkFlow调度到该Executor Server上运行。
选择Executor Server
Azkaban WebServer选择Executor,调用selectExecutor()方法,实现如下所示:
private Executor selectExecutor(final ExecutableFlow exflow,
final Set<Executor> availableExecutors) {
Executor choosenExecutor =
getUserSpecifiedExecutor(exflow.getExecutionOptions(),
exflow.getExecutionId());
// If no executor was specified by admin
if (choosenExecutor == null) {
logger.info("Using dispatcher for execution id :"
+ exflow.getExecutionId());
final ExecutorSelector selector = new ExecutorSelector(ExecutorManager.this.filterList,
ExecutorManager.this.comparatorWeightsMap);
choosenExecutor = selector.getBest(availableExecutors, exflow);
}
return choosenExecutor;
}
首先,查看当前exflow的配置中,是否要求将该exflow调度到指定的Executor Server上运行,如果是的话,则会返回该指定的Executor Server的信息,后续直接调度到该Executor Server上;否则会按照一定的计算规则去选出一个Executor Server。
在创建ExecutorSelector时,传入参数值ExecutorManager.this.filterList,该filterList是从azkanban.properties文件中读取azkaban.executorselector.filters的配置值,并创建了一个ExecutorFilter对象,而该对象中包含了一组FactorFilter,后面我们会说明。
使用ExecutorSelector来选出一个Executor Server,具体选择的逻辑,我们可以查看ExecutorSelector.getBest()方法。
首先通过定义的CandidateFilter(它是一个抽象类,具体实现类为ExecutorFilter)进行预筛选:
for (final K candidateInfo : candidateList) {
if (this.filter.filterTarget(candidateInfo, dispatchingObject)) {
filteredList.add(candidateInfo);
}
}
上面的filter就是FactorFilter类的实例,Azkaban内部定义了如下3种:
private static final String STATICREMAININGFLOWSIZE_FILTER_NAME = "StaticRemainingFlowSize";
private static final String MINIMUMFREEMEMORY_FILTER_NAME = "MinimumFreeMemory";
private static final String CPUSTATUS_FILTER_NAME = "CpuStatus";
目前3.40.0版本不支持自定义,只能使用内建实现的,如果需要增加新的FactorFilter,可以在此基础上做一个简单改造,配置使用自己定义的FactorFilter实现。FactorFilter是一个泛型类:FactorFilter<Executor, ExecutableFlow>,根据上面定义的3种指标对Executor Server进行一个预过滤,满足要求的会进行后面的比较,加入到调度WorkFlow执行的Executor Server的候选集中。
然后,通过如下方式进行比较排序,选择合适的Executor Server:
// final work - find the best candidate from the filtered list.
final K executor = Collections.max(filteredList, this.comparator);
logger.debug(String.format("candidate selected %s",
null == executor ? "(null)" : executor.toString()));
return executor;
这里关键的就是this.comparator,它有一个实现类ExecutorComparator,该类中给出了需要对两个Executor Server的哪些指标进行综合比较,亦即一组比较器的定义,可以看到目前考虑了4种比较器:
private static final String NUMOFASSIGNEDFLOW_COMPARATOR_NAME = "NumberOfAssignedFlowComparator";
private static final String MEMORY_COMPARATOR_NAME = "Memory";
private static final String LSTDISPATCHED_COMPARATOR_NAME = "LastDispatched";
private static final String CPUUSAGE_COMPARATOR_NAME = "CpuUsage";
通过上面代码可以看出,在选择调度一个WorkFlow到Azkaban集群中的某个Executor Server时,需要比较Executor Server的如下4个指标:
- 能够运行WorkFlow的剩余容量,数值越大越优先
- 剩余内存用量,数值越大越优先
- 最近分配Flow的时间,数值越大越优先
- CPU使用用量,数值越小越优先
基于上面4个指标,创建了4个比较器,使用FactorComparator来表示,对需要比较的一组Executor Server,使用这4个比较器进行比较,通过加权后得到一个得分值,根据该得分值选定Executor Server,核心逻辑如下所示:
final Collection<FactorComparator<T>> comparatorList = this.factorComparatorList.values();
for (final FactorComparator<T> comparator : comparatorList) {
final int result = comparator.compare(object1, object2);
result1 = result1 + (result > 0 ? comparator.getWeight() : 0);
result2 = result2 + (result < 0 ? comparator.getWeight() : 0);
logger.debug(String.format("[Factor: %s] compare result : %s (current score %s vs %s)",
comparator.getFactorName(), result, result1, result2));
}
上面选取了待比较的两个Executor Server都不为空的情况,分别遍历每个FactorComparator进行比较,在分别对每个Executor Server的比较结果值进行累加求和,加权得到一个分数值。从一组Executor Server中,根据最终比较的分数值,分数值最大的Executor Server为最终选定的Executor Server。
获取Executor Server的运行统计信息
在Azkaban WebServer内部,会维护集群中每个Executor Server的运行状态信息,该信息的获取是在QueueProcessorThread线程中实现的,定期去更新所维护的Executor Server的运行状态信息,如下所示:
if (currentTime - lastExecutorRefreshTime > activeExecutorsRefreshWindow
|| currentContinuousFlowProcessed >= maxContinuousFlowProcessed) {
// Refresh executorInfo for all activeExecutors
refreshExecutors();
lastExecutorRefreshTime = currentTime;
currentContinuousFlowProcessed = 0;
}
上面refreshExecutors()方法遍历内存中维护的所有的Executor Server,调用每个Executor Server的/serverStatistics接口,拉取Executor Server的运行状态信息。
另外,Azkaban WebServer还需要能够获取到各个Executor Server上运行的WorkFlow的状态信息,可以在ExecutorManager.ExecutingManagerUpdaterThread中看到实现,代码片段如下所示:
results =
ExecutorManager.this.apiGateway.callWithExecutionId(executor.getHost(),
executor.getPort(), ConnectorParams.UPDATE_ACTION,
null, null, executionIds, updateTimes);
上面调用Executor Server的/executor?action=update接口来拉取WorkFlow的状态信息,然后更新内存中维护的状态信息数据结构。其中,有些WorkFlow可能已经运行完成,需要释放资源;有些WorkFlow状态发生变更,也需要更新Azkaban WebServer端内存中维护的数据结构。
调度WorkFlow到Executor Server上执行
上面已经选定Executor Server,结合前面代码,是通过调用ExecutorManager.dispatch()方法来实现,调度WorkFlow到该选定的Executor Server上运行,代码片段如下所示:
try {
this.apiGateway.callWithExecutable(exflow, choosenExecutor,
ConnectorParams.EXECUTE_ACTION);
} catch (final ExecutorManagerException ex) {
logger.error("Rolling back executor assignment for execution id:"
+ exflow.getExecutionId(), ex);
this.executorLoader.unassignExecutor(exflow.getExecutionId());
throw new ExecutorManagerException(ex);
}
通过跟踪查看apiGateway.callWithExecutable()实现,可以看到,最终是调用了Executor Server端的一个REST API接口:/executor,然后带上相关的请求参数,如action=execute、execId等。
Executor Server执行WorkFlow
很显然,Azkaban WebServer调度WorkFlow后,Executor Server在ExecutorServlet中接收到对应的请求,核心方法如下所示:
private void handleAjaxExecute(final HttpServletRequest req,
final Map<String, Object> respMap, final int execId) throws ServletException {
try {
this.flowRunnerManager.submitFlow(execId);
} catch (final ExecutorManagerException e) {
e.printStackTrace();
logger.error(e.getMessage(), e);
respMap.put(RESPONSE_ERROR, e.getMessage());
}
}
在收到Azkaban WebServer的调度请求后,Executor Server使用内部的FlowRunnerManager来提交WorkFlow执行。在这个过程中,首先使用ExecutorLoader从数据库中读取WorkFlow对应的信息;然后使用FlowPreparer进行初始化,创建对应的数据目录等;最后创建FlowRunner来执行WorkFlow,并跟踪其执行状态。
参考