开发环境配置
开发环境:Ubuntu18.04+python3.6
请求库的安装
爬虫可以简单分为几步:抓取页面、分析页面和存储数据 。在抓取页面的过程中 ,我们需要模 拟浏览器向服务器发出请求,所以需要用到一些 Python 库来实现 HTTP 请求操作。
requests: pip install requests;selenium: Selenium 是一个自动化测试工具,利用它我们可以驱动浏览器执行特定的动作,如点击、下拉等操作 。 对于一些 JavaScript 谊染的页面来说,这种抓取方式非常有效 : pip install seleniumchromedriver: 只有安装chromedriver后,才能驱动Chrome浏览器进行操作。下载地址:http://npm.taobao.org/mirrors/chromedriver/ 。下载后将其移动到属于环境变量的目录:sudo mv chromedriver /usr/bin, 之后运行:
from selenium import webdriver
if __name__ == "__main__":
browser = webdriver.Chrome()
安装正确的话,会打开Chrome浏览器,显示空白页面。
geckodriver:同样的geckodriver是驱动FireFox浏览器不可缺少的,下载地址:https://github.com/mozilla/geckodriver/releases/ 。下载后将其移动到属于环境变量的目录:sudo mv geckodriver /usr/bin, 之后运行:browser = webdriver.Firefox()安装正确的话,会打开Firefox浏览器,显示空白页面。aiohttp:提供异步Web 服务的库,从 Python 3 . 5 版本开始 , Python 中加入了 async/await关键字,使得回调的写法更加直观和人性化。 aiohttp的异步操作借于 async/await 关键字的写法变得更加简洁,架构更加清晰 。 使用异步请求库进行数据抓取时,会大大提高效率。安装:pip install aiohttp官方还推荐安装如下两个库 : 一个是字符编码检测库 cchardet ,另 一个是加速 DNS 的解析库 aiodns ``
无界面的浏览器
在进行爬虫的过程中,浏览器界面可能会一直在移动,可以选择使用无界面的方式。目前Selenium已经不支持PhantomJS了,所以直接使用Chrome或FireFox的无界面版本。:
from selenium.webdriver import Firefox
from selenium.webdriver import Chrome
from selenium.webdriver import ChromeOptions
from selenium.webdriver import FirefoxOptions
if __name__ == "__main__":
options = ChromeOptions()
options.add_argument('--headless')
browser = Chrome(options=options)
# options = FirefoxOptions()
# options.add_argument('--headless')
# browser = Firefox(options=options)
browser.get('https://www.baidu.com')
print(browser.current_url)
# print(browser.page_source)
browser.quit()
运行后就不会在弹出一个浏览器了。
https://www.baidu.com/
[Finished in 6.3s]
解析库的安装
抓取网页代码之后,下一步就是从网页中提取信息 。 提取信息的方式有多种多样,可以使用正则表达式来提取 ,但是写起来相对比较烦琐 。 这里还有许多强大的解析库 ,如 lxml、Beautiful Soup 、 pyquery等 。
lxml:lxml 是 Python 的一个解析库 , 支持 HTML 和 XML 的解析,支持 XPath 解析方式,而且解析效率非常高:pip install lxml;beautiful soup:Beautiful Soup 是 Python 的一个 HTML 或 XML 的解析库,我们可以用它来方便地从网页中提取数据 。 它拥有强大的 API 和 多样的解析方式:pip install beautifulsoup4
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup('<h1>Title1</h1>', 'lxml')
>>> print(soup.string)
Title1
>>>
pyquery:pyquery 同样是一个强大的网页解析工具,它提供了和 jQuery 类似的语法来解析 HTML 文梢, 支持 css 选择器,使用非常方便:pip install pyquery;pytesseract:在爬虫过程中,难免会遇到各种各样的验证码,而大多数验证码还是图形验证码,这时候我们可以直接用 OCR 来识别:sudo apt-get install tesseract-ocr同时会安装相关的依赖。查看其支持的语言:
ulysses@ulysses:~/Downloads$ tesseract --list-langs
List of available languages (2):
eng
osd
可以从git上下载语言支持包,git clone https://github.com/tesseract-ocr/tessdata.git(下载所有语言支持)。
下载中文包后将语言包安装到 TESSDATA_PREFIX 目录
ulysses@ulysses:~/Downloads$ sudo mv chi_sim.traineddata /usr/share/tesseract-ocr/4.00/tessdata
使用tesseract来识别图片:
tesseract phototest.tif phototest.txt -l eng
Tesseract Open Source OCR Engine v4.0.0-beta.1 with Leptonica
Page 1
原图:

识别结果:
接着安装pytesseract和pillow:pip install pytesseract pillow
使用pytesseract进行测试
# -*- coding: utf-8 -*-
# @Date : 2018-11-12 21:07:09
# @Author : Ulysses ([email protected])
# @Link : ${link}
from PIL import Image
import pytesseract
image = Image.open('/home/ulysses/Downloads/phototest.tif')
text = pytesseract.image_to_string(image)
print(text)
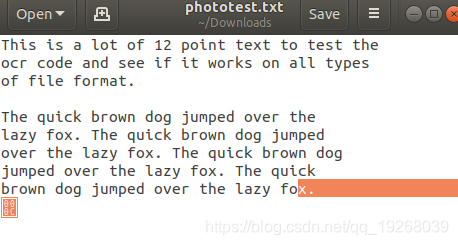
输出结果:
This is a lot of 12 point text to test the
ocr code and see if it works on all types
of file format.
The quick brown dog jumped over the
lazy fox. The quick brown dog jumped
over the lazy fox. The quick brown dog
jumped over the lazy fox. The quick
brown dog jumped over the lazy fox.
[Finished in 1.0s]
数据库的安装
MySQL
MySQL数据库和Python相关库的安装见:https://blog.csdn.net/qq_19268039/article/details/83757637
MongoDB
MongoDB 是由 C++语言编写的非关系型数据库, 是一个基于分布式文件存储的开源数据库系统 ,其内容存储形式类似 JSON 对象,它的字段值可以包含其他文档、数组及文档数组,非常灵活。MongoDB 是非关系数据库当中功能最丰富,最像关系数据库的,它与关系型数据库的对应:
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | 表连接,MongoDB不支持 | |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
安装与设置
- 导入MongoDB的GPK :
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 9DA31620334BD75D9DCB49F368818C72E52529D4; - 添加mongodb源:
echo "deb [ arch=amd64 ] https://repo.mongodb.org/apt/ubuntu bionic/mongodb-org/4.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb.list; - 更新源,下载:
sudo apt update,sudo apt install mongodb-org查看:
ulysses@ulysses:~/Downloads$ mongo --version
MongoDB shell version v4.0.4
git version: f288a3bdf201007f3693c58e140056adf8b04839
OpenSSL version: OpenSSL 1.1.0g 2 Nov 2017
allocator: tcmalloc
modules: none
build environment:
distmod: ubuntu1804
distarch: x86_64
target_arch: x86_64
- 对mongoDB Server的管理:
sudo systemctl enable mongod,sudo systemctl start mongod - 运行:
mongod --port 27017 --dbpath /data/db,运行命令之后, MongoDB 就在 27017 端口上运行了,数据文件会保存在/data/db 路径下 - 进入MongoDB:
mongo --port 27017,运行
> use admin
switched to db admin
> db.createUser({user:'dbuser', pwd:'******', roles:[{role:'root',db:'admin'}]})
Successfully added user: {
"user" : "dbuser",
"roles" : [
{
"role" : "root",
"db" : "admin"
}
]
}
创建了一个admin用户,赋予最高权限。
- 修改配置文件,允许远程连接
sudo vim /etc/mongodb.conf,把bind_ip=127.0.0.1这一行注释掉或者是修改成bind_ip=0.0.0.0,重启mongodb服务:sudo service mongodb restart - 可视化工具:Studio 3T和Robo 3T的下载地址:https://robomongo.org/
PyMono
在 Python 中, 如果想要和 MongoDB 进行交互 ,就需要借助于 PyMongo 库:pip install pymongo
使用python 进行简单的插入和查询。
# -*- coding: utf-8 -*-
# @Date : 2018-11-13 16:37:59
# @Author : Your Name ([email protected])
# @Link : http://example.org
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
# client = MongoClient('mongodb://localhost:27017/')
db = client.test
# db = client['test']
collection = db.students
# collection = db['students']
student1 = {
'id': '20170101',
'name': 'Jordan',
'age': 22,
'gender': 'male'
}
student2 = {
'id': '20170202',
'name': 'Mike',
'age': 21,
'gender': 'male'
}
# result = collection.insert(student1)
result = collection.insert_many([student1, student2])
print(result)
results = collection.find({'age': 20})
print(results)
for result in results:
print(result)
简单的插入和查询。结果:
5bea8f3f8c70ac282070ff43
<pymongo.cursor.Cursor object at 0x7f5062f5c358>
{'_id': ObjectId('5bea8e728c70ac26b5a547dd'), 'id': '20170101', 'name': 'Jordan', 'age': 20, 'gender': 'male'}
[Finished in 0.6s]
Redis
Redis是一个开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
它通常被称为数据结构服务器,因为值(value)可以是 字符串(String), 哈希(Map), 列表(list), 集合(sets) 和 有序集合(sorted sets)等类型。
安装和设置
使用安装命令:
sudo apt-get update
sudo apt-get install redis-server
使用redis-cli 进入命令行模式:
ulysses@ulysses:~$ redis-cli
127.0.0.1:6379>
Redis 成功安装了,但是现在 Red is 还是无法远程连接 的,依然需要修改配置文件,
配置文件的路径为/etc/redis/redis.conf.或者使用redis 127.0.0.1:6379> CONFIG GET CONFIG_SETTING_NAME的形式获取或者设置配置项。
首先注释bind 127.0.0.1 ::1 ,再取消requirepass foobared的注释,自行设置密码,最后重启redis服务。使用密码登录redis:
ulysses@ulysses:~$ redis-cli -a 'password'
127.0.0.1:6379> PING
PONG
Redis Desktop Manager是一个开源的redis数据库可视化工具,下载地址: https://github.com/uglide/RedisDesktopManager 。可以使用snap安装:sudo snap install redis-desktop-manager
redis-py
使用 redis-py 库来与redis进行交互:pip install redis
pythob操作redis:
# -*- coding: utf-8 -*-
# @Date : 2018-11-13 17:28:59
# @Author : Your Name ([email protected])
# @Link : http://example.org
from redis import StrictRedis
redis = StrictRedis(host='localhost', port=6379, db=0, password='password')
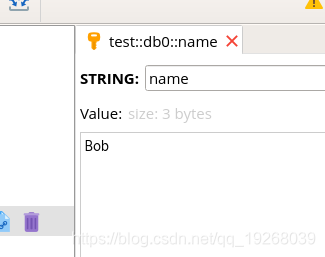
redis.set('name', 'Bob')
print(redis.get('name'))
运行结果:
b'Bob'
[Finished in 0.1s]
在Redis Desktop Manager中查看结果:
Web库安装
主要使用 Web 服务程序来搭建一些 API 接口,供爬虫使用,主要使用Flask和Tornado。
Flask
Flask 是一个轻量级的 Web 服务程序,它简单、易用、灵活,这里主要用来做一些 API 服务。安装:pip install flask
创建一个最基本的Flask应用程序:
from flask import Flask
app = Flask(__name__)
@app.route("/")
def index():
return '<h1>Hello World</h1>'
if __name__ == '__main__':
app.run()
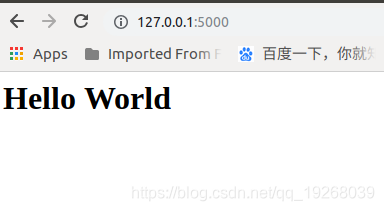
运行,在浏览器中输入127.0.0.1:5000
* Serving Flask app "flask_test" (lazy loading)
* Environment: production
WARNING: Do not use the development server in a production environment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
127.0.0.1 - - [13/Nov/2018 19:00:33] "GET / HTTP/1.1" 200 -
127.0.0.1 - - [13/Nov/2018 19:00:33] "GET /favicon.ico HTTP/1.1" 404 -
主要利用Flask+Redis维护动态代理池和Cookies池。
Tornado
Tornado 是一个支持异步的 Web 框架,通过使用非阻塞 I/O 流,它可以 支撑成千上万 的开放连接,效率非常高。
安装:pip install tornado
创建一个Tornado应用:
import tornado.ioloop
import tornado.web
class MainHandler(tornado.web.RequestHandler):
def get(self):
self.write("Hello, world")
def make_app():
return tornado.web.Application([
(r"/", MainHandler),
])
if __name__ == '__main__':
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
运行后,控制台没有输出,浏览器访问127.0.0.1:8888
爬虫库安装
直接用 req uests 、 Selenium 等库写爬虫,如果爬取量不是太大,速度要求不高,是完全可以满足需求的 。 但是写多了会发现其内部许多代码和组件是可以复用的,如果我 们把这些组件抽离出来,将各个功能模块化,就慢慢会形成一个框架雏形,久而久之,爬虫框架就诞生了。
pyspider
pyspider 是国人 binux 编写的强大的网络爬虫框架,它带有强大的 WebUI 、脚本编辑器、任务监控器、项目管理器以及结果处理器,同时支持多种数据库后端、多种消息队列,另外还支持 JavaScript渲染页面的爬取。安装pip install pyspider,若出现pycurl相关错误,则需要安装相关的依赖,包括python-dev、python-distribute、libcurl4-openssl-dev、libxml2-dev、libxslt1-dev、pythonlxml 还有处理傅里叶变换的libssl-dev、libffi-dev、 build-essential。
安装完成后执行pyspider all, pyspider的web服务就会在本地的5000端口运行
Scrapy
Scrapy 是一个十分强大的爬虫框架 ,依赖的库比较多 ,至少需要依赖的库有 Twisted 14.0 、lxml 3.4和 pyOpenSSL0.14 。 在不同的平台环境下,它所依赖的库也各不相 同,所以在安装之前,最好确保把一些基本库安装好:sudo apt-get install build-essential python3-dev libssl-dev libffi-dev libxml2 libxml2-dev libxslt1-dev zliblg-dev。之后安装Scrapy:pip install Scrapy
(venv) ulysses@ulysses:~/crawler$ scrapy
Scrapy 1.5.1 - no active project
Usage:
scrapy <command> [options] [args]
Available commands:
bench Run quick benchmark test
fetch Fetch a URL using the Sc
Scrapy-Splash
Scrapy-Splash是一个 Scrapy 中支持 JavaScript 渲染的工具。
Splash的安装需要Docker,通过Docker安装Scrapinghub/splash镜像,然后启动容器,创建splash服务
docker pull scrapinghub/splash
docker run -d -p 8050:8050 scrapinghub/splash
安装服务完成后,打开本地8050,可以看到splash的主页:

安装splash的python库:pip install scrapy-splash
Scrapy-Redis
Scrapy-Redis 是 Scrapy 的分布式扩展模块,有了它,我们就可以方便地实现 Scrapy 分布式爬虫的搭建。安装pip install scrapy-redis