————————————————————————————————————————————
c++中关于容器的一些用法:
顺序容器,表示数据可以顺序的访问,不依赖于数据存放的位置,而依赖于数据加入容器的顺序。
主要有:
1.vector
2.string
3.list
4.queue
5.priority_queue
6.stack
关联容器:按照关键字的顺序来保存,访问也是按照关键字进行的。
主要有:
1.map
2.set
3.mutlimap
4.mutliset ——注意这里的数据是顺序排放的
5.unordermap
6.unordermutlimap
7.unorderset
8.unordermutliset
————————————————————————————————————————————
STL之四:list用法详解
https://blog.csdn.net/sunxueping/article/details/51170890
1. list功能
list是双向循环链表,每一个元素都知道前面一个元素和后面一个元素.list对象自身提供了两个pointer用来指向第一个和最后一个元素.每个元素都有pointer指向前一个和后一个元素.如果想要插入新元素,只需要操纵对应的pointer即可.因此list在几个方面与array,vector不同:
-
list不支持随机访问,如果你要访问第5个元素,就得顺着串链逐一爬过前4个元素.所以在list中随机访问一个元素是很缓慢的,然而你可以从两端开始航行整个list,所以访问第一个或最后一个元素速度很快.
-
任何位置上(不只两端)执行元素的插入或删除都非常快,因为无需移动任何其他元素.实际上内部只是进行了一些pointer操作而已.
-
==插入和删除动作并不会造成其他元素的各个pointer,reference和iterator失效. ==
-
list对于异常的处理方式是:要么操作成功,要么什么都不发生,绝对不会陷入”只成功一半”这种进退维谷的境地.
list所提供的成员函数反映出它与array,vector不同:
- list提供front(),push_front()和pop_front(),back(),push_back()和pop_back()等操作函数.
- 由于==不支持随机访问,list既不提供下表操作符,也不提供at(). ==
- list并未提供容量,空间重新分配等操作函数,因为完全无必要.每个元素都有自己的内存,在这个元素删除前一直有效.
2.list的创建插入与遍历

3.list的访问

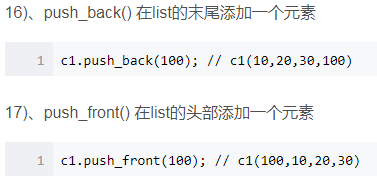
4.list的删除
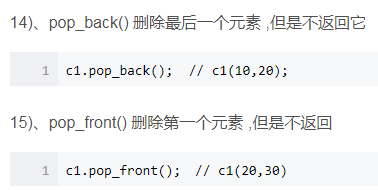

5.list的插入

6.list反转,排序

7.list的去重
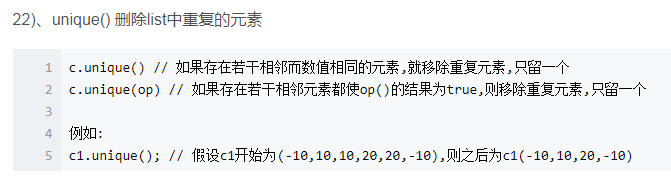
8.list的注意事项
常用的删除容器中元素的方法是如下(方法1):
list< int> List;
list< int>::iterator iter;
for( iter = List.begin(); iter != List.end(); )
{
if(1)
{
iter = List.erase( iter );
}
else
{
iter++;
}
}
注意:函数在返回的时候,是返回当前迭代器的下一个节点。所以当 iter = List.erase( iter ); 执行以后,迭代器自动指向了下一个元素。而对于入参中的iter,所指的地址已经被销毁,所以写的时候,应该注意加上前面的iter =
————————————————————————————————————————————
C++ 学习笔记之 STL 队列
https://www.cnblogs.com/Wade-/p/6498360.html
在算法以及数据结构的实现中,很多地方我们都需要队列(遵循FIFO,先进先出原则)。为了使用队列,我们可以自己用数组来实现队列,但自己写太麻烦不说,并且还很容易出错 好在C++的STL(标准模板库)为我们实现了一个强大的队列,它包含在头文件中
1.队列的构造

我们可以使用deque(双端队列容器)或者list(链表容器)来作为queue的基础容器(underlying container,即队列是在基础容器的基础上实现的),其中deque是默认使用的,如果没有在参数中特殊指定,那么queue就使用deque作为基础容器
双端队列deque是最容易的使用的队列。下面对这个队列进行说明:

————————————————————————————————————————————
C++ STL优先队列常用用法
https://blog.csdn.net/cerberux/article/details/51762357
https://www.cnblogs.com/flyoung2008/articles/2136485.html
优先队列(priority queue)
普通的队列是一种先进先出的数据结构,元素在队列尾追加,而从队列头删除。在优先队列中,元素被赋予优先级。当访问元素时,具有最高优先级的元素最先删除。优先队列具有最高级先出 (largest-in,first-out)的行为特征。
STL中的优先队列-priorit_queue,包含在头文件”queue”中,可以使用具有默认优先级的已有数据结构;也可以再定义优先队列的时候传入自定义的优先级比较对象;或者使用自定义对象(数据结构),但是必须重载好< 操作符。
1.优先队列的常用操作

其中q.top()为查找操作,在最小优先队列中搜索优先权最小的元素,在最大优先队列中搜索优先权最大的元素。q.pop()为删除该元素。优先队列插入和删除元素的复杂度都是O(lgn),所以速度很快;另外,在优先队列中,元素可以具有相同的优先权。
2.优先级的定义
默认的是<优先级,也就是元素大的优先级高,那么每次删除优先级最高的元素,也就是删除最大的元素,所以默认是一个最大堆
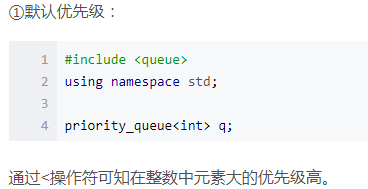
修改优先级,如何修改称为最小堆,即最小的元素的优先级最高,那么就要重载<操作符,我们可以定义<操作符是大于的

第一个参数是优先队列的元素,第二个底层的容器位置,第三个<比较的优先级,最小的元素的优先级最高,即是一个最小堆。
传入结构体,自己定义优先级

最大堆的构造方法及其使用

最小堆的构造方法及其使用

————————————————————————————————————————————
STL set、multiset 学习笔记
https://blog.csdn.net/study_more/article/details/7783690
https://blog.csdn.net/longshengguoji/article/details/8546286
1、set与multiset的介绍
一、set、multiset 的能力:
set、multiset采用平衡二叉树完成,set中的元素不允许重复,multiset允许重复;
set、multiset不提供直接存取元素的任何函数操作;
通过iterator 进行元素简介存取,有一个限制:从迭代器角度来看,元素值是常数;
二、set、multiset 的形式:
set 一个set,以less<>(operator <)为排序准则
set<Elem,OP>一个set,以为排序准则
multiset 一个multiset,以less<>(operator <)为排序准则
multiset<Elem,OP>一个multiset,以为排序准则
OP如:less、greater等
注:排序的不同,也会纳为两个对象是否相等的判断;
2.相关功能
和所有关联式容器类似,通常使用平衡二叉树完成。事实上,set和multiset通常以红黑树实作而成。
自动排序的优点是使得搜寻元素时具有良好的性能,具有对数时间复杂度。
但是造成的一个缺点就是:
不能直接改变元素值。因为这样会打乱原有的顺序。
改变元素值的方法是:先删除旧元素,再插入新元素。
存取元素只能通过迭代器,从迭代器的角度看,元素值是常数
3.相关操作
创建集合

2.大小,判断是否为空

3.插入操作
有两种插入操作,有不同的返回类型:

如果是 set的话,插入重复的元素 会返回失败,不能插入,如果是mutliset则可以成功插入。

有重复的元素则不会进行插入。
3.删除操作


遍历集合

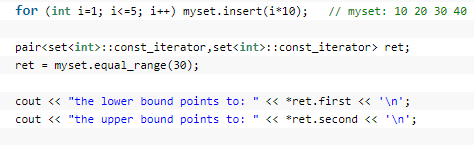
操作函数,寻找第k大的值或者次k大的值


————————————————————————————————————————————
C++中的STL中map用法详解
http://www.cnblogs.com/fnlingnzb-learner/p/5833051.html
关于map的使用
1.基本介绍:
Map是STL的一个关联容器,它提供一对一(其中第一个可以称为关键字,每个关键字只能在map中出现一次,第二个可能称为该关键字的值)的数据 处理能力,由于这个特性,它完成有可能在我们处理一对一数据的时候,在编程上提供快速通道。这里说下map内部数据的组织,map内部自建一颗红黑树(一 种非严格意义上的平衡二叉树),这颗树具有对数据自动排序的功能,所以在map内部所有的数据都是有序的,后边我们会见识到有序的好处。
2.建立map,往map里面插入数据
第一种:用insert函数插入pair数据

第二种:用insert函数插入value_type数据

第三种:用数组方式插入数据
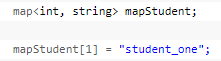
以上三种用法,虽然都可以实现数据的插入,但是它们是有区别的,当然了第一种和第二种在效果上是完成一样的,用insert函数插入数据,在数据的 插入上涉及到集合的唯一性这个概念,即当map中有这个关键字时,insert操作是插入数据不了的,但是用数组方式就不同了,它可以覆盖以前该关键字对 应的值
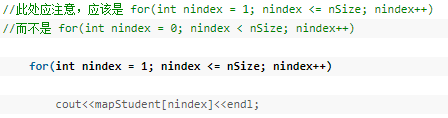
3.数据的遍历

用数组的形式遍历
4.查找元素
第一种:用count函数来判定关键字是否出现,其缺点是无法定位数据出现位置,由于map的特性,一对一的映射关系,就决定了count函数的返回值只有两个,要么是0,要么是1,出现的情况,当然是返回1了
第二种:用find函数来定位数据出现位置,它返回的一个迭代器,当数据出现时,它返回数据所在位置的迭代器,如果map中没有要查找的数据,它返回的迭代器等于end函数返回的迭代器。
查找map中是否包含某个关键字条目用find()方法,传入的参数是要查找的key,在这里需要提到的是begin()和end()两个成员,
分别代表map对象中第一个条目和最后一个条目,这两个数据的类型是iterator.

5.删除元素
移除某个map中某个条目用erase()
该成员方法的定义如下:
iterator erase(iterator it);//通过一个条目对象删除
iterator erase(iterator first,iterator last)//删除一个范围
size_type erase(const Key&key);//通过关键字删除
clear()就相当于enumMap.erase(enumMap.begin(),enumMap.end());

6.排序问题
map中的元素是自动按Key升序排序,所以不能对map用sort函数;
这里要讲的是一点比较高深的用法了,排序问题,STL中默认是采用小于号来排序的,以上代码在排序上是不存在任何问题的,因为上面的关键字是int 型,它本身支持小于号运算,在一些特殊情况,比如关键字是一个结构体,涉及到排序就会出现问题
7.map的空间保存
map在空间上的特性,否则,估计你用起来会有时候表现的比较郁闷,由于map的每个数据对应红黑树上的一个节点,这个节点在不保存你的 数据时,是占用16个字节的,一个父节点指针,左右孩子指针,还有一个枚举值(标示红黑的,相当于平衡二叉树中的平衡因子),我想大家应该知道,这些地方 很费内存了吧,不说了……
8.基本操作函数

————————————————————————————————————————————
STL里的multimap
在“使用
// 注: 伪码
multimap <string, string> phonebook;
phonebook.insert("Harry","8225687"); // 家里电话
phonebook.insert("Harry","555123123"); // 单位电话
phonebook.insert("Harry"," 2532532532"); // 移动电话
在 multimap 中能存储重复键的能力大大地影响它的接口和使用。那么如何创建非唯一键的关联容器呢?答案是使用在
提出问题
与 map 不同,multimap 可以包含重复键。这就带来一个问题:重载下标操作符如何返回相同键的多个关联值?以下面的伪码为例:
string phone=phonebook["Harry];
标准库设计者的解决这个问题方法是从 multimap 中去掉下标操作符。因此,需要用不同的方法来插入和获取元素以及和进行错误处理。
插入
假设你需要开发一个 DNS 后台程序(也就是 Windows 系统中的服务程序),该程序将 IP 地址映射匹配的 URL 串。你知道在某些情况下,相同的 IP 地址要被关联到多个 URLs。这些 URLs 全都指向相同的站点。在这种情况下,你应该使用 multimap,而不是 map。例如:
#include <map>
#include <string>
multimap <string, string> DNS_daemon;
用 insert() 成员函数而不是下标操作符来插入元素。insert()有一个 pair 类型的参数。在“使用
DNS_daemon.insert(make_pair("213.108.96.7","cppzone.com"));
在上面的 insert()调用中,串 “213.108.96.7”是键,“cppzone.com”是其关联的值。以后插入的是相同的键,不同的关联值:
DNS_daemon.insert(make_pair("213.108.96.7","cppluspluszone.com"));
因此,DNS_daemon 包含两个用相同键值的元素。注意 multimap::insert() 和 map::insert() 返回的值是不同的。
typedef pair <const Key, T> value_type;
iterator
insert(const value_type&); // #1 multimap
pair <iterator, bool>
insert(const value_type&); // #2 map
multimap::insert()成员函数返回指向新插入元素的迭代指针,也就是 iterator(multimap::insert()总是能执行成功)。但是 map::insert() 返回 pair<iterator, bool>,此处 bool 值表示插入操作是否成功。
查找单个值
与 map 类似,multimap 具备两个版本重载的 find()成员函数:
iterator find(const key_type& k);
const_iterator find(const key_type& k) const;
find(k) 返回指向第一个与键 k 匹配的 pair 的迭代指针,这就是说,当你想要检查是否存在至少一个与该键关联的值时,或者只需第一个匹配时,这个函数最有用。
例如:
typedef multimap <string, string> mmss;
void func(const mmss & dns)
{
mmss::const_iterator cit=dns.find("213.108.96.7");
if (cit != dns.end())
cout <<"213.108.96.7 found" <<endl;
else
cout <<"not found" <<endl;
}
处理多个关联值
count(k) 成员函数返回与给定键关联的值得数量。下面的例子报告了有多少个与键 “213.108.96.7” 关联的值:
cout<<dns.count("213.108.96.7") //output: 2
<<" elements associated"<<endl;
为了存取 multimap 中的多个值,使用 equal_range()、lower_bound()和 upper_bound()成员函数:
equal_range(k):该函数查找所有与 k 关联的值。返回迭代指针的 pair,它标记开始和结束范围。
下面的例子显示所有与键“213.108.96.7”关联的值:
typedef multimap <string, string>::const_iterator CIT;
typedef pair<CIT, CIT> Range;
Range range=dns.equal_range("213.108.96.7");
for(CIT i=range.first; i!=range.second; ++i)
cout << i->second << endl; //output: cpluspluszone.com
// cppzone.com
lower_bound() 和 upper_bound():lower_bound(k) 查找第一个与键 k 关联的值,而 upper_bound(k) 是查找第一个键值比 k 大的元素。下面的例子示范用 upper_bound()来定位第一个其键值大于“213.108.96.7”的元素。通常,当键是一个字符串时,会有一个词典编纂比较:
dns.insert(make_pair("219.108.96.70", "pythonzone.com"));
CIT cit=dns.upper_bound("213.108.96.7");
if (cit!=dns.end()) //found anything?
cout<<cit->second<<endl; //display: pythonzone.com
如果你想显示其后所有的值,可以用下面这样的循环:
// 插入有相同键的多个值
dns.insert(make_pair("219.108.96.70","pythonzone.com"));
dns.insert(make_pair("219.108.96.70","python-zone.com"));
// 获得第一个值的迭代指针
CIT cit=dns.upper_bound("213.108.96.7");
// 输出: pythonzone.com,python-zone.com
while(cit!=dns.end())
{
cout<<cit->second<<endl;
++cit;
}
结论
虽然 map 和 multimap 具有相同的接口,其重要差别在于重复键,设计和使用要区别对待。此外,还要注意每个容器里 insert()成员函数的细微差别。