top命令

1.平均负载(load average):
正在耗费CPU进程与正在等待io的进程之和,三个值分别是一分钟,五分钟,十五分钟的平均负载,负载值只要小于CPU颗粒数属于正常情况
任务进程(Tasks):
1.total总数,runing正在运行进程数,sleeping睡眠的进程数,stopped停止的进程数,zombie僵尸进程数
Cpu(s):cpu使用率,就是CPU花费时间(该时间是将CPU时间切片)处理进程所消耗的时间,该时间极短,肉眼感觉不出来,
1.us用户进程消耗的时间占比,如root用户;sy系统进程消耗的CPU时间占比,如读写磁盘,上下文切换(内核中);ni优先级高的进程消耗CPU时间占比,如果该项比较高,则进程设置了优先级,抢占CPU较强;id空闲进程消耗CPU的时间占比;wa等待进程消耗CPU的时间占比;hi硬中断进程消耗CPU时间占比;si软中断进程消耗CPU时间占比;st强制交换
2.Mem内存:total总的内存大小,used已经使用的内存,free空闲的内存,buffers高速缓存(磁盘到内存)
Swap:虚拟内存,total,used,free,cached高速缓冲(内存到磁盘)
对于Java项目来说没有内存使用率一说,因为Java项目内存是通过GC垃圾回收机制来获得内存,在配置JVM时候就已经把最大内存和醉小内存写死了,他是一个固定值
如果top命令中%MEM的使用率超过80%,说明机器内存不够,需要加内存
VIRT:物理内存和虚拟内存之和,
RES:纯物理内存
SHR:共享内存
vmstat命令

cpu列:cs为进程总数,us,sy,id,wa,st对应上一条所述
procs列:①进程是程序运行最小单位,②进程有多个线程组成,进程是线程的最小单位,③多线程优势是支持大并发,有点是节约资源,④进程比线程安全,⑤r表示正在消耗cup的进程,和负载中第一个同理
vmstat 间隔时间s 打印次数[(vmstat 2 5) 表示每个两秒打印一次,共打印三次]
例:如果发现CPU使用过高,分析步骤①判断是用户CPU高还是系统CPU高,
②如果是用户us使用进程消耗CPU较高,找到对应进程,在找到该进程下那个线程消耗CPU较高,再跟踪该线程消耗的线程栈调用的方法,则是该方法导致CPU过高
top下①shift+p表示将所有进程按照消耗CPU占比从大到小排序.②shift+m将所有进程按照消耗内存从大到小排序
查找使用CPU最高线程方法一,命令:top -H -p 进程id;会显示出该进程下全部的线程,(进程id就是top命令下的PID)
查找使用CPU最高线程方法二.命令:top -p 进程id;会显示出该进程,然后在交互命令去输入H,该进程小的线程会逐一显示出来,然后任然可以使用shift+p,和shift+m,对进程按照CPU的使用占比大小,内存使用占比大小从大到小排序
例:如果是系统(sy)使用CPU消耗占比较高,分析方法如下
①说明内核消耗CPU消耗较高,查看ni(优先级),st(),hi(硬中断),si(软中断),如果中断消耗CPU较高说明进程切换较高,则可减少进程,如果st强制交换消耗CPU较高,说明内存可能不足,则需要加内存
②如果①中几点CPU占用都不高,则优先查看磁盘是否繁忙,(在内存和磁盘之间来回切换)
iostat命令:

①一般使用命令:iostat -x查看io和CPU(如上图中avg-cpu,和top命令下CPU使用情况的缩写一致)
②Device:设备
sda # 磁盘总量,dm-0设备一和dm-1设备二
rrqm/s:每秒读磁盘扇区的速度
wrqm/s:每秒写磁盘扇区的速度
r/s:
avgrq_sz:单次操作磁盘的平均时间(磁盘io,单次读写)
avgqu_sz:磁盘等待队列的大小
await:总的等待磁盘时间,如果该值较大,说明磁盘等待时间较大
r_await:读等待磁盘的时间
w_await:写等待磁盘的时间
svctm:serivce+time的缩写,服务时间,磁盘真正处理的时间,单次磁盘服务时间应该在5以下(机械硬盘)
util:空闲的
③和命令sar -d效果类似

例:如果是系统进程(sy)占用CPU过高,
①可通过iostat -x,sar -d,nmon来查看磁盘是否繁忙,其中nmon直接查看besy,如果高于20%则磁盘繁忙
②如果通过排查,①中都正常则通过strace命令(strace -c -f -p 进程id)
strace命令:是跟踪系统内核调用的命令
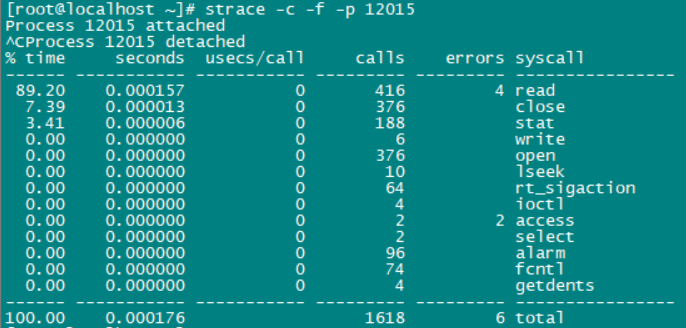
usecs/cass:主动调用内核次数
calls:被动调用内核次数
syscall:被动用的内核
vmstat命令:

1.常用命令格式vmstat
procs列:
r 表示运行和等待的CPU时间片的进程数,这个值如果长期大于系统CPU个数9(核数),说明CPU不足,需要增加CPU
b 表示在等待资源的进程数,比如正在等待IO或者内存交换的等待
memory列
swpd 表示切换到内存交换区的内存大小,大小kb,通俗讲就是虚拟内存的大小,如果swap值不为0或者比较大,只要si,so的之长期为0,这种情况一般属于正常情况
free 表示当前空闲的物理内存(kb)
buff 表示缓冲大小(baffers cached),一般对块设备的读写叫做缓冲
cache 表示缓存的大小(page cached),一般是文件系统进行缓存,频繁访问的文件都会别缓存,如果cache的值非常大,说明文件比较多,如果此时Io和bi的值比较小,说明文件系统效率较好
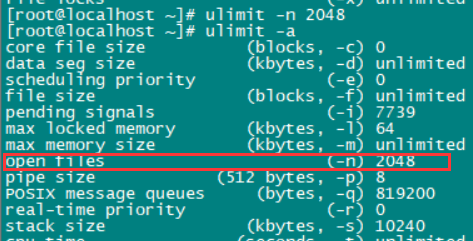
命令lsof-d pid 查看进程打开的文件句柄数,

命令ulimit -i 查看系统默认打开文件数

命令ulimit -n 整数 修改默认打开文件数(ulimit -n 2048)
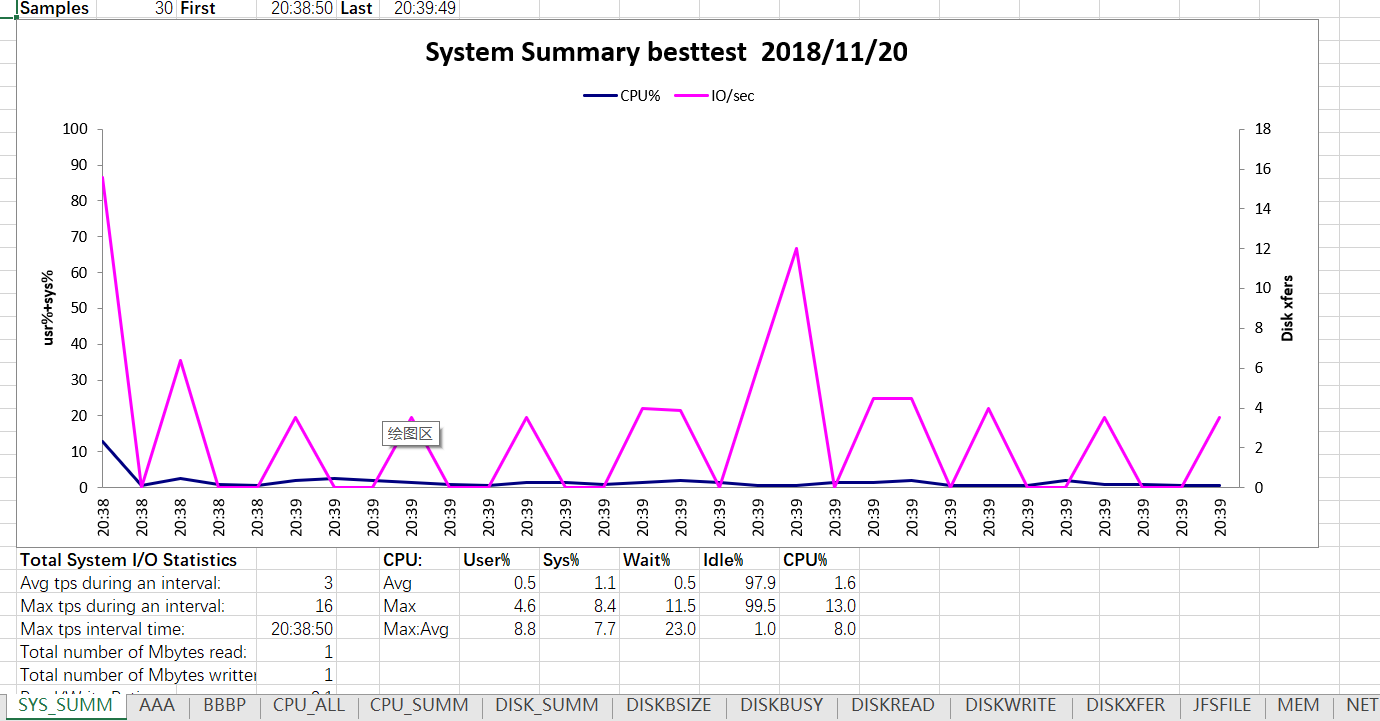
NMON命令
执行命令(./nmon_x86_rhel52 -fT -s 2 -c 30)(每隔2秒采集一次数据,共采集30次)会在nmon的根目录生成一个以.nmon结尾的文件,将该文件下载到本地使用nmon自带的分析工具(nmon analyser v33g.xls,网上下载)打开
监控数据会以图表形式分析出来,直观准确,其中包括CPU,磁盘,内存,等等的数据
命令free -m(查看剩余内存)
