简短介绍下Spark
几个关键词:快速,通用,集群计算平台
Spark扩展了MapReduce计算模型,且支持更多计算模式,包含:
- 交互式查询
- 流处理
这里的交互式,不是简单的我们生活中理解的与设备的交互。它的深意是:对于大规模数据集的处理,速度够快。只有速度够快,才能实现交互式操作。
前文提到的,基于内存的数据定义,Spark可以在内存中进行计算。其实,即使不在内存中计算,放在磁盘上,Spark也有很高的性能,比一般的MapReduce要高效。
Spark适用场景:各种需要不同的分布式平台的场景。
Spark将任务整合在统一的框架下支持这些计算,对于多平台的管理,大大降低了管理者的负担。
另外,Spark和其他大数据工具可以密切配合,比如运行在Hadoop集群。
Spark软件栈
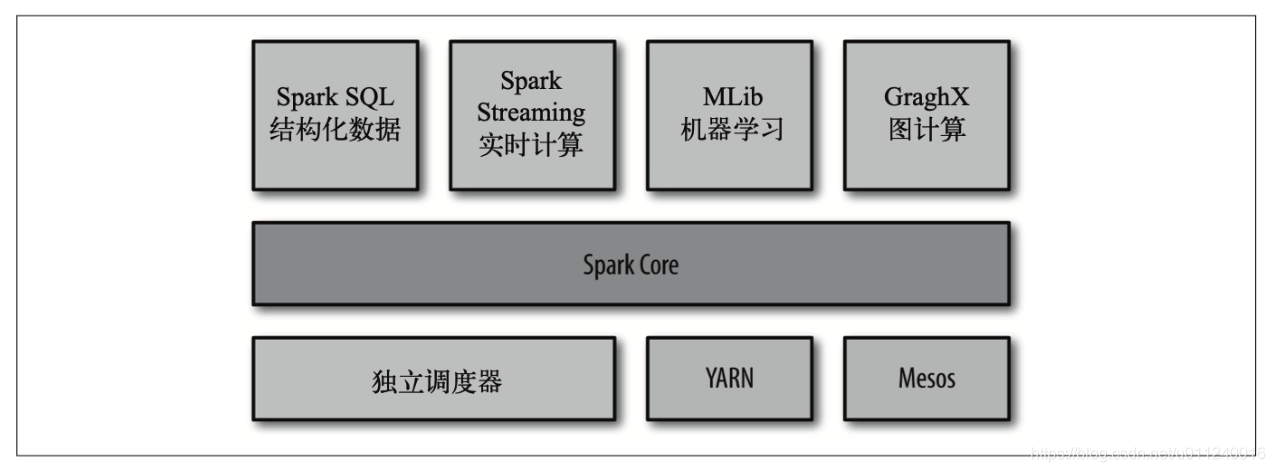
从图上可以看出,Spark Core居于核心地位,它是计算引擎,特点是速度快,通用。职能是调度,分发以及监控任务。
Spark Core的性能很棒,所以能够针对不同场景设计更高层次的组件,比如SQL,以及机器学习库等。这些高层组件关系密切,可以互相调用。因此,在Spark上的开发就和我们平时写代码体验相似,这些组件可以简单的组合调用。
得益于组件间的亲密关系,下层改进,上层直接受益。
且在Spark中增加新的组件,其他组件都能马上使用。
六个字:高内聚,低耦合。
书上举的例子:
在应用中将数据流中的数据用机器学习算法进行实时分类。同时,数据分析师可以通过SQL实时查询结果数据,而且还可以通过Python Shell来访问数据,即时分析。
看到这里,大概我们知道了Spark这个解决方案,有着强大的能力,一套系统打遍天下的感觉。
组件简介
Spark Core
实现的是Spark的基本功能,包含:
- 任务调度
- 内存管理
- 错误恢复
- 存储系统交互
- 弹性分布式数据集
** Spark SQL**
用于操作结构化数据的程序包。支持多种数据源,如:
- Hive表
- Parquet
- JSON
Spark Streaming
对实时数据进行流式计算。
MLlib
提供的是常见的机器学习功能库,包含:
- 分类
- 回归
- 聚类
- 协同过滤
同时,还提供了:
- 模型评估
- 数据导入
等功能。
Spark设计的这些方法,都可以在集群上轻松伸缩。
GraphX
用于操作关系图(比如社交网络)的程序库,并行计算。
END.