(004)HBase是一个在HDFS上开发的面向列的分布式数据库。如果需要实时地随机访问超大规模数据集,就可以使用HBase这一Hadoop应用了
HBase集群的搭建
前提条件
- Hadoop集群
- ZooKeeper集群
- JDK
原料
- hbase-2.1.0-bin.tar.gz
附件
链接:https://pan.baidu.com/s/1E5TQeoyofRDlyR9pTquzZQ
提取码:btr8
集群的划分
我是这样划分集群的
192.168.225.100 – master
192.168.225.101 – slave1
192.168.225.102 – slave2
安装步骤
1.将安装包上传到master主机上(我这里放在了/opt/bigdata目录下了)
2.解压安装包
3.修改配置文件(定位到/opt/bigdata/hbase-2.1.0/conf目录下)
文件清单
- hbase-env.sh
- hbase-site.xml
- regionservers
3.1修改hbase-env.sh文件

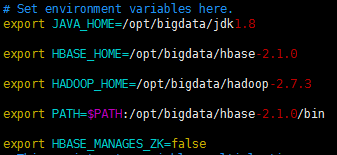
3.2修改hbase-site.xml文件
使用vim命令打开该文件,做出如下修改:

注:hbase.zookeeper.property.clientPort配置的这个端口号必须跟zookeeper配置的clientPort端口号一致。
3.3修改regionservers文件
使用vim命令打开该文件,做出如下修改:
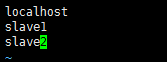
4.将hbase-2.1.0文件夹发送到slave1和slave2节点上
命令:
$ scp -r /opt/bigdata/hbase-2.1.0/ hadoop@slave1:/opt/bigdata/
$ scp -r /opt/bigdata/hbase-2.1.0/ hadoop@slave2:/opt/bigdata/


5.修改文件夹权限
命令:
$ chown -R hadoop:hadoop /opt/bigdata/hbase-2.1.0
启动与测试
启动
启动集群的顺序是Hadoop集群–>ZooKeeper集–>HBase集群,首先定位至/opt/bigdata/hbase-2.1.0/bin目录下,执行./start-hbase.sh命令。

测试
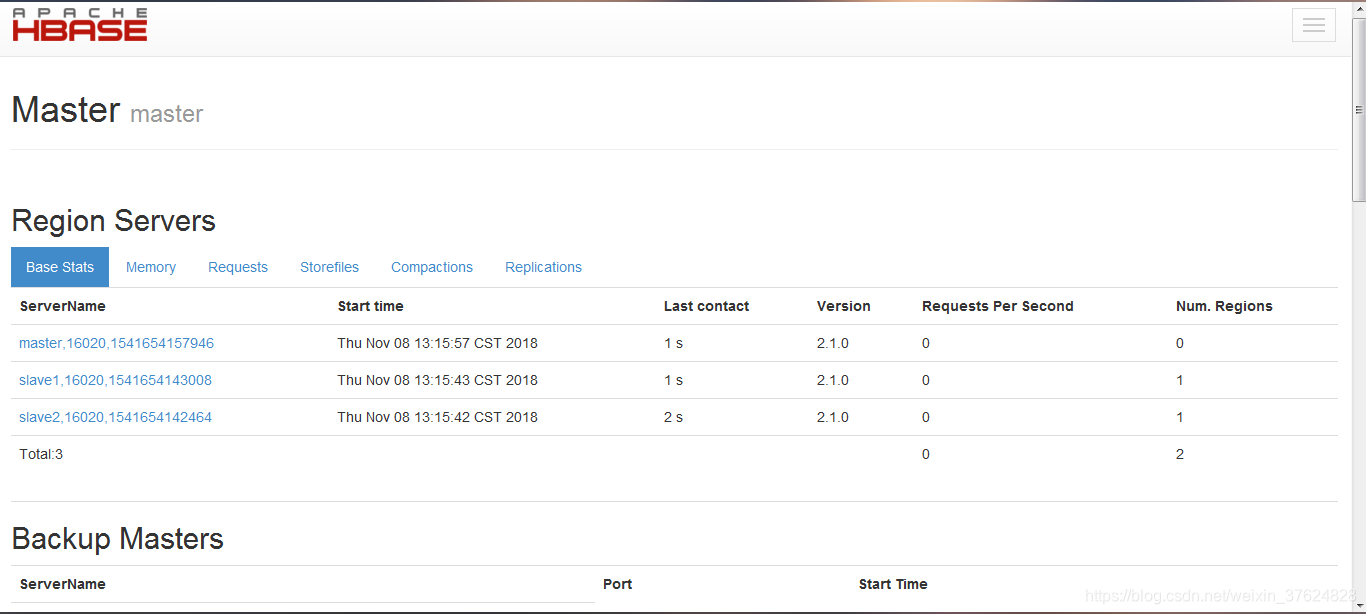
WEB界面:输入http://192.168.225.100:16010可以看到web界面
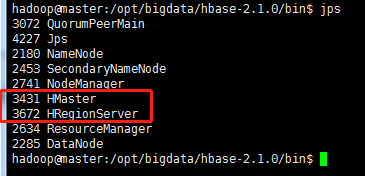
JPS命令:输入jps
master:
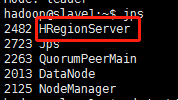
slave1:
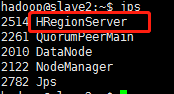
slave2:
至此HBase集群就算搭建完毕了。