1、java本身的序列化存在的问题
1、序列化数据结果比较大、传输效率比较低
2、不能跨语言对接
对于该问题出现的xml、json等方式成为了热门技术,但是这种序列化技术还是存在占用空间大、性能低等问题,也就出现了二进制序列化框架MessagePack等。
2、序列化概念
把对象转换为字节序列的过程称之为对象的序列化,反之则称为反序列化
3、如何实现一个序列化操作
1、对一个类实现Serializable接口,同时生成一个serialVersionUID。
package com.wuyonghu.test4;
import java.io.Serializable;
public class Person implements Serializable {
private static final long serialVersionUID = 2818521397469642897L;
private String name;
private String age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAge() {
return age;
}
public void setAge(String age) {
this.age = age;
}
}
2、创建主方法来进行对对象的序列化:
package com.wuyonghu.test4;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
public class MainTest {
public static void main(String[] args) {
// 序列化
SerializableTest();
}
private static void SerializableTest() {
try {
// 使用ObjectOutputStream指定序列化的结果
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(new File("person")));
// 创建需要序列化的对象
Person person = new Person();
person.setAge("17");
person.setName("lufei");
// 进行序列化
oos.writeObject(person);
System.out.println("序列化完成!");
oos.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
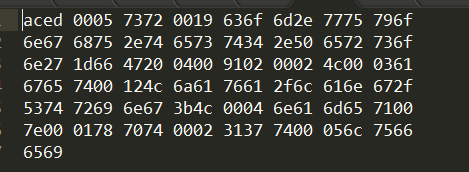
3、执行SerializableTest方法后,会发现在工程的根目录下生成了一个person文件:

该文件通过二进制方式打开的结果如下:
4、如何进行反序列化操作
以第三步得到的person文件来进行反序列化
1、反序列化的方法如下:
public static void SerializableTest2() {
try {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(new File("person")));
Person person = (Person) ois.readObject();
System.out.println("反序列化完成,姓名为" + person.getName() + ",年龄为:" + person.getAge());
ois.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}
2、执行反序列化后的结果如下:

3、从结果可以知道,我们能从通过反序列化得到序列化前的对象信息。
5、serialVersionUID的作用
在对对象进行序列化的时候,该对应对应的类是实现了序列化的接口,同时新增了serialVersionUID这个值的,那么这个值的作用是什么呢?

为了测试,首先将该值保留,进行序列化,得到结果person文件。然后将该值注释后进行反序列化。

此处注意一下,如果要验证该功能,测试时最好自己随意指定一个serialVersionUID值,否则jvm会自动生成一个UID,而反序列的时候自动生成的该UID会相同,从而会出现没有报错的情况。
从该现象,得出的结论如下:
文件流中的class和classpath中的class,也就是修改过后的class,不兼容了,处于安全机制考虑,程序抛出了错误,并且拒绝载入。从错误结果来看,如果没有为指定的class配置serialVersionUID,那么java编译器会自动给这个class进行一个摘要算法,类似于指纹算法,只要这个文件有任何改动,得到的UID就会截然不同的,可以保证在这么多类中,这个编号是唯一的。所以,由于没有显指定 serialVersionUID,编译器又为我们生成了一个UID,当然和前面保存在文件中的那个不会一样了,于是就出现了2个序列化版本号不一致的错误。因此,只要我们自己指定了serialVersionUID,就可以在序列化后,去添加一个字段,或者方法,而不会影响到后期的还原,还原后的对象照样可以使用,而且还多了方法或者属性可以用。
6、关于序列化的其他概念
1、序列化并不保存静态变量的状态
2、transient关键字表示指定属性不参与序列化
3、如果父类没有实现序列化,而子类实现列序列化。那么父类中的成员没办法做序列化操作
4、对同一个对象进行多次写入,打印出的第一次存储结果和第二次存储结果,只多了5个字节的引用关系。
并不会导致文件累加