【问题】
生产环境有多台slave服务器,不定期的会crash,下面是error log中的堆栈信息
Thread pointer: 0x7f1e54b26410
Attempting backtrace. You can use the following information to find out
where mysqld died. If you see no messages after this, something went
terribly wrong...
stack_bottom = 7f1ed98e6e28 thread_stack 0x40000
/usr/sbin/mysqld(my_print_stacktrace+0x35)[0xf438c5]
/usr/sbin/mysqld(handle_fatal_signal+0x4a4)[0x7ce014]
/lib64/libpthread.so.0[0x3ef280f7e0]
/usr/sbin/mysqld[0x132713a]
/usr/sbin/mysqld(_Z23well_formed_copy_ncharsPK15charset_info_stPcmS1_PKcmmPS4_S5_S5_+0xba)[0xde2c2a]
/usr/sbin/mysqld(_Z29field_well_formed_copy_ncharsPK15charset_info_stPcmS1_PKcmmPS4_S5_S5_+0x66)[0x7f4e06]
/usr/sbin/mysqld(_ZN10Field_blob14store_internalEPKcmPK15charset_info_st+0x1dc)[0x80037c]
/usr/sbin/mysqld(_ZN17Fill_process_listclEP3THD+0x4c9)[0xd6b089]
/usr/sbin/mysqld(_ZN18Global_THD_manager19do_for_all_thd_copyEP11Do_THD_Impl+0x26d)[0x7cca9d]
/usr/sbin/mysqld(_Z23fill_schema_processlistP3THDP10TABLE_LISTP4Item+0x43)[0xd54143]
/usr/sbin/mysqld[0xd52d57]
/usr/sbin/mysqld(_Z24get_schema_tables_resultP4JOIN23enum_schema_table_state+0x1cc)[0xd52fec]
/usr/sbin/mysqld(_ZN4JOIN14prepare_resultEv+0x6d)[0xd485cd]
/usr/sbin/mysqld(_ZN4JOIN4execEv+0xc0)[0xcde670]
/usr/sbin/mysqld(_Z12handle_queryP3THDP3LEXP12Query_resultyy+0x250)[0xd49370]
/usr/sbin/mysqld(_ZN21Sql_cmd_insert_select7executeEP3THD+0x3bc)[0xe944ac]
/usr/sbin/mysqld(_Z21mysql_execute_commandP3THDb+0xfc0)[0xd0b0a0]
/usr/sbin/mysqld(_Z11mysql_parseP3THDP12Parser_state+0x3a5)[0xd0f605]
/usr/sbin/mysqld(_Z16dispatch_commandP3THDPK8COM_DATA19enum_server_command+0x17a8)[0xd10e18]
/usr/sbin/mysqld(_Z10do_commandP3THD+0x194)[0xd11764]
/usr/sbin/mysqld(handle_connection+0x2bc)[0xde4d0c]
/usr/sbin/mysqld(pfs_spawn_thread+0x174)[0x1255534]
/lib64/libpthread.so.0[0x3ef2807aa1]
/lib64/libc.so.6(clone+0x6d)[0x3ef20e8bcd]
【分析过程】
从生成2个core file分析来看,有一些发现:
1、 报错发生在查询information_schema.processlist表的INFO字段

2、 值拷贝函数well_formed_copy_nchars,传入参数from_length的长度是65535,说明当时正在执行超长的SQL语句,INFO字段被截断了
第1个core.184694文件

发生异常的代码行,在验证字符串的2个字节时报错
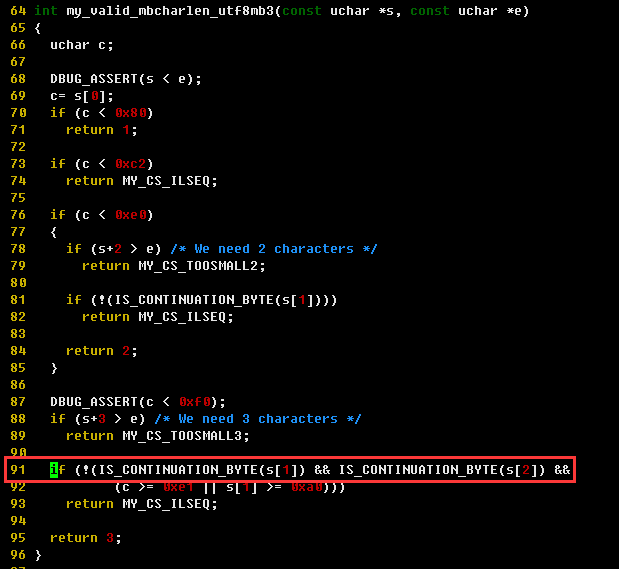
第2个core.61979文件
发生异常的代码行,在获取字符串的第一个字节时报错
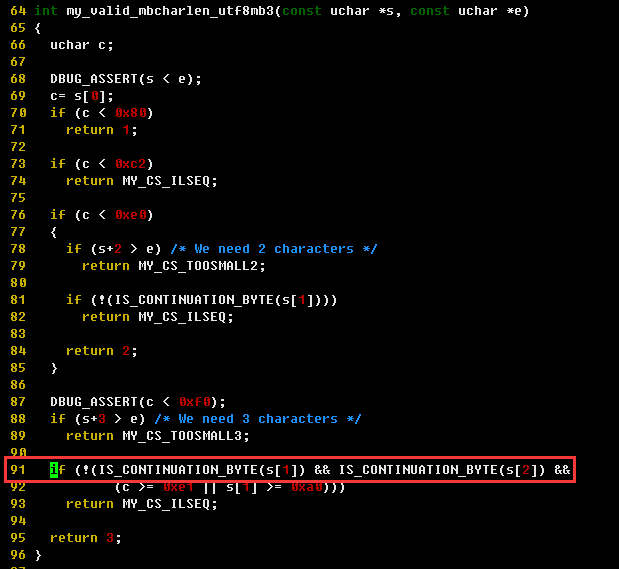
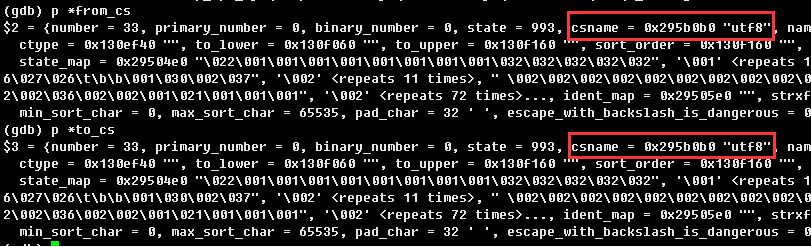
3、从字符集来看,from_cs是UTF8,to_cs也是UTF8,值拷贝时字符集从UTF8到UTF8
【结论】
目前可以确定的触发条件是DB在执行长度大于65535的SQL语句,同时执行information_schema.processlist的查询语句。
发生的两台服务器都是slave,可以推测可能是主库执行了包含二进制或大文本字段的insert、update、delete语句,在ROW模式下所有执行的语句记录到日志时,记录了每一行数据每个字段的修改。
这样比起master更容易出现超长的SQL语句,同时也提高了问题发生的概率。
将主从复制模式从ROW改为MIXED后,问题没有再现。
获取更多更及时的文章信息,请关注我的微信公众号
