cs294 Lecture2: Supervised Learning of behaviors
这一章主要讲在序列化决策里常用的模仿学习。
Definition of sequential decision problems
Terminology & notation
还是用观察丛林中的老虎举例。首先是传统的监督学习的模式:

输入是一个观察到的图片,用
表示,输出是一组分类标签的概率,在这里用
表示。而中间的函数就是一个基于输入图片的概率分布的拟合函数
。其中
表示的是函数的参数,比如在深度学习模型里就是那些权重。
如果把原来的监督学习中对于每幅作为观察结果
的图像的分类结果改为看到图像一个人需要做出的动作
,而做出动作之后会改变接下来观察到的图像
,之后重复整个过程。那么这样的过程就叫做一个序列的决策过程。

而在每个当前观察到的图片
的背后有一个实际的状态
,它有可能与当前观察到的部分有所区别。而对应的策略函数
也有基于观察的版本与基于实际状态的版本。比如豹子追捕羚羊,它们被观察到的作为
的是作为一个图片,实际上它们之间存在着一个相对的位置关系:

因此对于整个的序列决策过程,可以看成是一个概率图模型。对应不同的状态
得到一个观察
,基于观察由策略
中得到一个动作a_{t},执行动作然后当前状态根据状态转移分布
转移到下一个状态
。在这个过程中有一个马尔科夫性质,那就是下一个状态
的分布只与当前状态
有关系,而知道
之前的状态并不会为状态转移或决策提供更多的信息。对于能够完全对状态进行观察的情形,我们只需要知道当前状态即可,但是很多时候会遇到只能够部分观察到当前状态的情况。
依然是豹子追捕羚羊,如果在当前状态时有一个汽车挡住了摄像机,那么观察到的
中可能就没有豹子的位置,但是可能前一时刻
的时候汽车并不在这里,因此在只能部分观察的情况下,利用好过往的信息也可能带来更多的信息。
这里还有一个符号表示的问题。另外一个表示通常用在控制领域,但是表示的意思是一样的:

Imitation learning: supervised learning for decision making
接下来看一个实际的应用场景。当我们需要训练程序来进行自动驾驶时,能够选择的一个方法是,在车上装一个摄像头,记录下对应图片场景下车上司机的动作,把这些对应的标签作为训练数据来做一个图片分类的监督学习的工作。如果能够做的比较好,最终得到的分类模型就相当于是一个决策的函数。这样程序也就克隆了人类司机的行为。

但是很不幸,如果仅仅是直接就这么做的话,大部分情况下不会得到理想的效果。我们可以简单的进行一些理论分析。

把状态作为一个维度,时间作为一个维度,我们就得到了模仿学习可能得到的一个轨迹曲线和实际的训练样本的曲线。出现这种偏差的原因可能仅仅是因为训练出来的模型在某一个状态下犯了一个很小的错误,但是得到的下一个状态会与训练集合中的状态也有一些差别,于是模型得到的动作还会进一步的导致状态的偏移,错误最终累积得到了如图示的比较大的差距。
但是在实际的应用中,使用模仿学习的方法能够得到一个较好的结果,他们是如何做的呢?

他们的做法是,在车上装了三个摄像头,一个正中,一个偏左一个偏右。对于正中的摄像头,对应的动作与人类的动作一致。对于偏左的摄像头输入的图像,将对应时刻的人类动作进行一定的往右修正。同样偏右的摄像头动作往左修正。这样将它们得到的训练集合合并用来训练模型。
这样就解决了原来做法不稳定的问题。因为每当模型出现了一点错误,比如往左或往右偏离了一点,那么训练集中还有对应的状态与动作,就能够帮助汽车纠正回正中的状态轨迹上。因此能够保证最终的稳定性。

因为对于实际的训练数据来说,使用多个摄像头并且对对应的动作进行一定的纠正相当于是将训练数据中的轨迹数据加入了噪音。这样实际的训练数据中,轨迹在每个时间的状态里相当于是一个分布。而且加入的噪音类似于强迫人类专家做出动作来纠正这个噪音,相当于得到了一个比较全面的轨迹分布。当你的策略从最优的动作偏离的时候,训练数据里依然有一些数据能够帮助模型做出纠正动作,回到正确的轨迹上来。这对于人类来说很难自己写下来这样的分布,但是使用模仿学习模仿一个完美的策略,加入一定的噪音,然后让人类纠正这些噪音,就能够得到这样的分布。从而得到比较稳定的结果。
但是这样的做法是一个非常启发式的做法。就是对可能会出现的偏离情况添加了对应的数据让模型能够纠正自己。有没有一种算法能够自然的保证模仿学习的结果至少在最理想化的情况下最终能够保持稳定呢?现在来更深入的理解这种不稳定性为何会发生。
现在我们得到了一个策略
,这是我们的训练结果。那么在应用这个策略的过程中得到的轨迹的分布就相当于是
,而实际的训练数据用的是人类基于观察到的情况做出的决策
。也就是说实际应用训练得到的策略时对应的观察分布与训练时候输入的分布不同。那么我们就会想到,能不能使得两者相等
。如果实际遇到的场景与训练时候的场景是同分布的,那么训练得到的策略显然就会能够稳定(不考虑监督学习本身的不稳定性)。

Ross在论文里提出了这样一个算法。先根据已有的训练数据进行训练,然后在实际情形里运行训练得到的结果,得到新的轨迹。利用人类专家将这些新得到的轨迹进行标记。之后与原来的训练数据组合起来重复训练。这样一直下去最终就能够完成
的目标。
但是这个算法也有个问题,那就是中间依然需要大量的人工标注。我们是否能够完成一种算法也不需要更多的数据就能够得到良好结果呢?

即使是拥有一个完美的不会偏离的模型,我们依然需要能够精确地模仿人类专家的行为。那么模仿人类专家的行为又有哪些难度?
难度主要在两个地方,一个是人类的行为有可能是非马尔科夫的。对于马尔科夫性质的假设来说,如果两次遇到相同的观察,那么两次做出的动作会是完全相同的。但是对于人类来说,做决策时候却不一定是遵循马尔科夫性质的。因此有时候需要将策略依赖前面若干个观察。

如果想要解决非马尔科夫性的问题,可能就需要处理历史信息,这个时候使用RNN系列的算法会很有帮助,特别是LSTM。

第二点就是,得到的动作有可能是多峰的。有些情况下多峰的情况是影响不大的,比如动作是离散的情况下。但是对于连续的动作空间,如果使用了一个高斯分布,那么输出的一般会是高斯分布的均值与方差。但是有些情况比如滑雪时候绕过大树,往左或往右都可以,但输出均值意味着很多时候选择中间的动作,这样就会有问题。

解决多峰动作也有三个方案。第一个是输出一个混合的高斯模型:

第二种是从输入开始加入一定的噪声。讲的不是很细,可以看ppt上提供的三个更详细的方向。

最后一个方法是将输出的维度进行分割。每一次只输出一个维度上的动作,将前一个维度的结果和原来的状态作为下一个维度预测模型的输入,预测下一个维度的结果,以此类推。这样做主要是将指数级别的输出空间化为线性的:

总结:模仿学习一般直接使用是不好使的,因为会带来轨迹的漂移问题。有时候会使用一些方法来使模仿学习能够应用。

Case studies of recent work in imitaion learning

第一个例子用的是类似于之前自动驾驶里使用的方法,使用多个摄像头来加入噪声增加稳定性。

第二个例子是用的仿真环境中人类的动作来帮助机械臂完成拿起物体并放在另一个位置的工作。
还有一些模仿学习中其它的例子。比如结构化的预测。就是给定了一些样例,能够模仿学习出符合结构规则的结果。还有逆强化学习。并不是从给出的动作中学习动作,而是从中学出这些动作的目标。

What is missing from imitation learning

还有一个关于目标函数设定的问题。对于最初的看到老虎做出动作的例子,可能目标函数是最小化被老虎吃掉的概率。对于模仿学习来说,最简单的cost函数可以设定为是否与需要模仿的动作一样。也就是0/1 error。或者是与给定的动作相同的概率等等。

下面来对模仿学习的学习效果来做一些数学上的分析。分析通过求一条轨迹的总的cost的期望入手。为了推导的简单,假设cost使用的就是0/1 error。然后假设对于最后训练出来的模型,对每个训练集中的状态
都有
。那么推导出对于整个序列来说,cost的期望是一个T的二次式:

理解这个推导的重点在于,当轨迹偏离了训练轨迹之后,后面所有的动作都可以看成是错误的,因为设定的对比策略是训练集中的。偏离了训练集之后的所有动作都没有什么最优策略。
如果把假设做出一些改动,将
改为
。同时假设使用了Dagger算法使得
。得到的推到结果就会完全不同。就会变成T的一次式。因为即使前一步犯错了,下一步依然有可能得到正确的动作。于是:
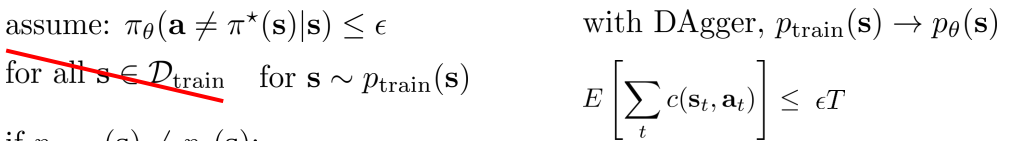
但是实际上有可能不是完全等于,因此还要进行另外的推导。如果不是完全等于,在当前的假设下依然可能得出T的二次项结果作为cost期望的上限。cost期望越大这表明模型的结果与真实训练数据中人类专家的动作相差越远。

除此之外还有一些关于cost设计的问题。很多问题里用到的cost函数都不会是0/1 error这么简单。因为cost函数或者是reward需要能够引导程序学会对应的动作,因此可能设计起来非常复杂。

后面的章节会更多的讲述reward的设计。