1.什么是HADOOP?
HADOOP是apache旗下的一套开源软件平台,HADOOP提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理
- HADOOP的核心组件有
- HDFS(分布式文件系统)
- YARN(运算资源调度系统)
- MAPREDUCE(分布式运算编程框架)
- 广义上来说,HADOOP通常是指一个更广泛的概念——HADOOP生态圈
2.HADOOP在大数据、云计算中的位置和关系
云计算是分布式计算、并行计算、网格计算、多核计算、网络存储、虚拟化、负载均衡等传统计算机技术和互联网技术融合发展的产物。借助IaaS(基础设施即服务)、PaaS(平台即服务)、SaaS(软件即服务)等业务模式,把强大的计算能力提供给终端用户。现阶段,云计算的两大底层支撑技术为“虚拟化”和“大数据技术”。而HADOOP则是云计算的PaaS层的解决方案之一,并不等同于PaaS,更不等同于云计算本身。
3.重点组建
HDFS:分布式文件系统
MAPREDUCE:分布式运算程序开发框架
HIVE:基于大数据技术(文件系统+运算框架)的SQL数据仓库工具
HBASE:基于HADOOP的分布式海量数据库
ZOOKEEPER:分布式协调服务基础组件
Mahout:基于mapreduce/spark/flink等分布式运算框架的机器学习算法库
Oozie:工作流调度框架
Sqoop:数据导入导出工具
Flume:日志数据采集框架
4.hadoop集群搭建
三台虚拟机:系统centos6.5 hadoop2.6.4 jdk1.7
1.准备Linux环境
1.0先将虚拟机的网络模式选为NAT
1.1修改主机名:vi /etc/sysconfig/network
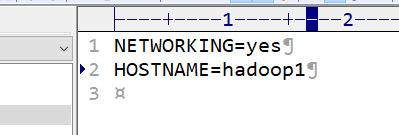
1.2修改IP:vim /etc/sysconfig/network-scripts/ifcfg-eth0 不修改也行
1.3修改主机名和IP的映射关系:vim /etc/hosts
192.168.25.139 hadoop1
192.168.25.140 hadoop2
192.168.25.141 hadoop31.4关闭防火墙
#查看防火墙状态
service iptables status
#关闭防火墙
service iptables stop
#查看防火墙开机启动状态
chkconfig iptables --list
#关闭防火墙开机启动
chkconfig iptables off1.5 添加普通用户hadoop
useradd hadoop
#为storm用户添加密码:
echo 123456| passwd --stdin hadoop
#将hadoop添加到sudoers,这是重新创建一个用户组,他有着自己的home/ hadoop目录
echo "hadoop ALL = (root) NOPASSWD:ALL" | tee /etc/sudoers.d/ hadoop
chmod 0440 /etc/sudoers.d/ hadoop
#修改配置文件sudo vim /etc/sudoers
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL
给hadoop用户添加执行的权限然后强制保存
2.安装jdk,
JAVA_HOME=/usr/local/jdk1.7.0_71
CLASSPATH=.:$JAVA_HOME/lib.tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH
这些处理好了开始安装hadoop
1.上传编译好的hadoop压缩包,并且解压
tar -zxvf cenos-6.5-hadoop-2.6.4.tar.gz -C apps/

配置配置文件hadoop-env.sh 主要配置环境变量
export JAVA_HOME=/usr/local/jdk1.7.0_71

配置配置文件 core-site.xml 主要指定hadoop的文件系统用哪个(fdfs),指定namenode是谁,端口是多少,配置集群里面每个进程工作的数据目录
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hdpdata</value>
</property>
</configuration> 
配置hdfs-site.xml 配置hdfs的副本的数量
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/hdfs/data</value>
</property>
</configuration> 
配置mapred-site.xml.template 并改名字为mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration> 
配置yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration> 
2.配置hadoop环境变量:
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.6.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_PREFIX}/lib/native
export HADOOP_OPTS=-Djava.library.path=$HADOOP_PREFIX/lib
3.分发apps文件夹到其他机器,配置环境变量
4.格式化namenode(是对namenode进行初始化):hdfs namenode -format (hadoop namenode -format)

5. 启动hadoop
先启动HDFS
sbin/start-dfs.sh
查看datanode的启动情况:
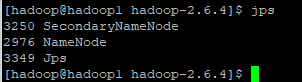
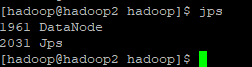
这里注意多次格式化namenode后可能出现datanode起不来的情况,把配置文件中dfs.datanode.data.dir在本地系统的路径下的current/VERSION中的clusterID改为与namenode一样。重启即可!这里就把dfs文件删掉就好了.(问题解决是hdfs配置文件的问题)
再启动YARN
sbin/start-yarn.sh
查看yarn的启动情况:
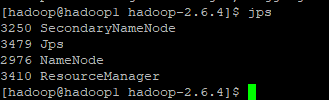
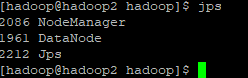
http://192.168.25.130:50070 (HDFS管理界面)

只启动一个namenode或者datanode
hadoop-daemon.sh start namenode hadoop-daemon.sh start datanode
配置slaves:

配置免密登陆:
ssh-keygen -t rsa(回车)
ssh-copy-id localhost
cd .ssh
cp id_rsa.pub authorized_keys
chmod 600 authorized_keys
测试本地免密登陆:ok 没有问题
![]()
将密钥发送到hadoop2,hadoop3 ssh-copy-id hadoop2 ssh-copy-id hadoop3
测试登陆hadoop2: ok没问题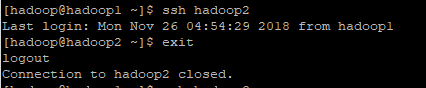
停止hdfs:sbin/stop-dfs.sh
上传一个文件:
首先查根目录下有什么文件:hadoop fs -ls /

什么也没有,现在上传一个文件:hadoop fs -put canglaoshi.avi /
有了:
命令查看也有了:
我们配置的备份数据是两份,这两份会存到哪个机器呢?首先就近就会存放一份这这台机器上,还有一个副本就放其他机器上
根据所配置的配置文件来找到副本的数量,
上传的小文件可以找到他所有的副本的数量,未满128M没有分片


上传大文件:被分成了两片,分别存于不同的机器上


安装包传上去被切成了几块,就没法解压了,但是把他拼起来就有办法解压:

可以从fdfs上下载下来:hadoop fs -get /canglaoshi.avi
