文章目录
一、基本信息
标题:《Fast and accurate object detection in high resolution 4K and 8K video using GPUs》
时间:2018-10-26
出版源:HPEC 2018
论文领域:目标检测(Object Detection)
主要链接:
- homepage:None
- arXiv(Paper):https://arxiv.org/abs/1810.10551
- github:https://github.com/previtus/AttentionPipeline
关键词:yolov2、attention、high resolution
二、研究背景
大多数目标检测论文都是聚焦在低分辨率图像上(特别是VOC、COCO),而低分辨率图像会损失很多细节,并且目前很多设备拍摄的图像或者视频都是高清的(4k/8k)。
如下图所示,一幅高清图像可以识别到更多的目标,如果使用传统的目标检测算法,resize图像后,会丢失很多目标(recall很低)。

因此这篇论文主要针对高清图像/视频来提出有效的目标检测算法,保证准确率和速度。
三、创新点
3.1 概述
论文提出Attention pipeline。第一阶段,将原始图像下采样(downscaling)到低分辨率空间中。在低分辨率中目标检测引导model attention到原图的重要区域。第二阶段,model直接处理原图上的区域,仅限于上述highlighted areas。
这里有个关键词Attention,其概念就是仅关注原图中少数的区域。
注:本文使用YOLOv2算法为基础网络。
主要贡献如下:
We propose a novel method which processes high
resolution video data while balancing the trade-off
of accuracy and performance.We show that our method reduces the number of
inspected crops as compared to a baseline method
of processing all crops in each image and as a result
increases performance by up to 27%.We increase the PASCAL VOC Average Precision
score on our dataset from 33.6 AP50 to 75.4 AP50 as
compared to using YOLO v2 in baseline approach
of downsampling images to the model’s resolution.Implement efficient code which distributes work
across GPU cluster and measure the performance of
each individual operation of proposed method.
速度结果:
-
3-6 FPS on 4k video
-
2 FPS on 8k video
3.2 详解
3.2.1 问题分析
在本文的上下文中,我们将使用高分辨率的视频数据集,可以将其视为连续帧的stream。
除了每个帧内的空间信息之外,还存在跨相邻帧传送的时间信息(相同的跟踪对象可能存在于相似位置的下一帧中)。
Basiline approaches
1.将原图缩放(downscale)到evaluating 模型的分辨率
2.用略微重叠的固定分辨率网格覆盖原始图像,并分别评估每个crop的区域。
First approach is to downscale the whole image original image into resolution of the evaluating model. This approach offers fast evaluation,
but loses large amounts of information potentially hidden in the image, which especially applies with high resolutions. Second approach is to overlay the original image with a slightly overlapping grid of fixed resolution and evaluate each cut out crop separately. In this second approach we pay the full computational cost as we evaluate every single crop of the image.
本文定义了"crop",如下图中的绿色方框所示,"crop"其实包含了bounding box的方形区域。

3.2.2 Attention pipeline
本文提出了 attention pipeline模型,有助于优化上述两个步骤,提高精确率和性能。
本文根据两个stage来评估模型:
- “attention evalution” stage 关注图像的roughly采样区域,以获得我们正在定位对象的怀疑区域。
- “final evalution” stage 关注在更高分辨率下查看这些选定区域。
注:attention可以译为注意力
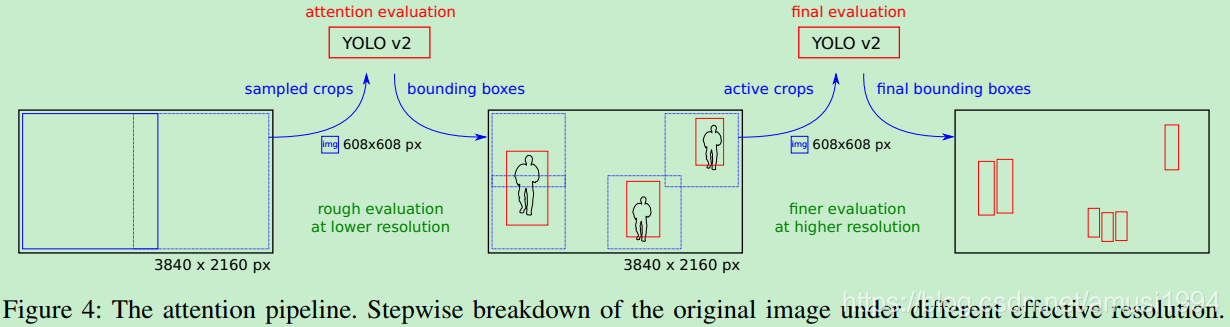
Attention evaluation
将原图输入到attention evaluation stage,为了平衡精度和速度,我们选择通过在原始图像上按行数(图像高度)进行crop,保证相邻网格之间存在像素重叠。
注意:此次crop参数是行数
例如,可以选择注意力评估来通过以行数为参数的方形网格来裁剪图像,使得原始图像完全被最小量的正方形覆盖。请注意,这些方形区域可能重叠。
然后将crop的区域缩小为具有对应于纵横比的608px高度和宽度。图像的宽度将细分为608x608像素的正方形。
请参阅图3中第一和第二阶段中此网格的示例。

由上图可知,有2=1x2个方形网格
本文使用YOLOv2来评估这些初始attention crop,并获得检测目标的bounding boxes。注意,初始评估也许会丢失图像中的小目标或者被遮挡的目标,但这些目标仍然会在感兴趣的rough 区域上获得。在视频分析的实际设置中,本文使用视频的时间方面,并在几个相邻帧中合并和重用attention。
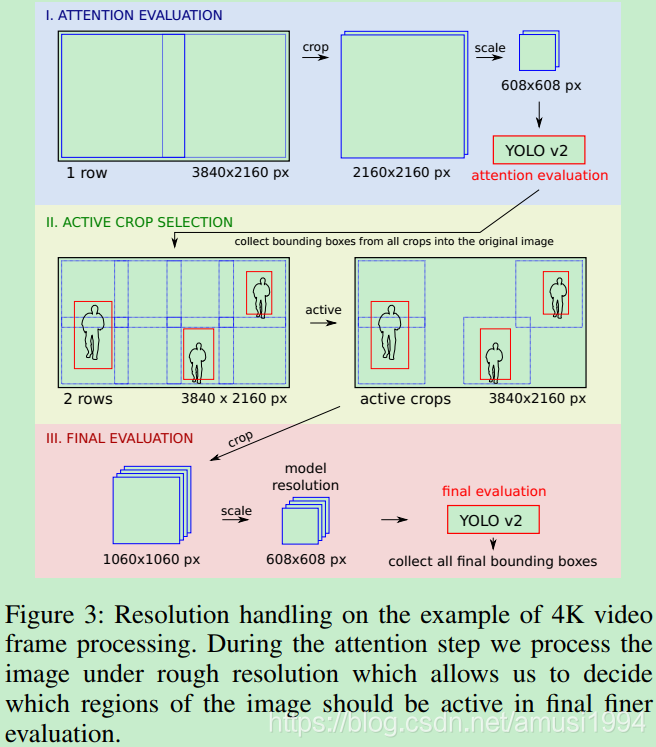
Active crop selection
按行数/2将图像划分为多个方形网格,然后检查每个网格与在attention evaluation阶段中检测的bouding boxes的交叉。具有重叠的网格将被标记为final evaluation中的active crop。
Active crop数量通常少于所有crop的数量。
注意:此次crop参数是行数/2
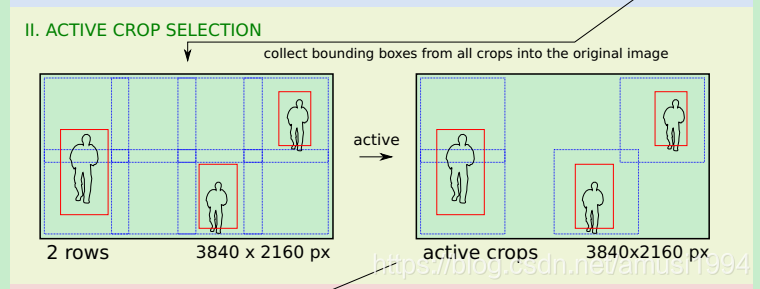
由上图可知,有8=2x4个方形网格
Final evaluation
在final evaluation阶段,本文使用YOLOv2模型在更高分辨率的方形crop定位目标。如下图中的第三阶段所示,
请注意crop分辨率的差异(1060px比例缩放至608px,而不是2160px,缩放至608px)

Postprocessing
在评估图像的多个重叠crop区域时,我们获得这些区域中的每一个的边界框列表。为了限制边界框的数量,我们运行非最大抑制(non-maximum suppression)算法以仅保留最佳预测。因为我们不知道对象的大小或其在图像中的位置,我们可能会在多个相邻区域中检测到相同的对象。如果对象大于我们网格的区域,或者如果它位于两个相邻区域的边界上,实际上被切成两半,则会发生这种情况。 如图5所示。
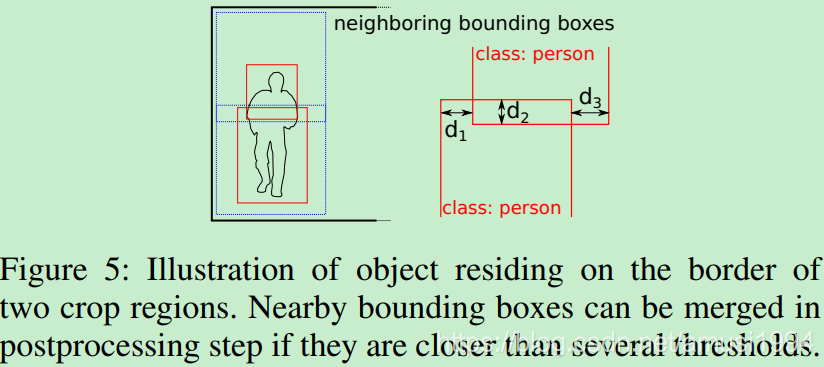
如果沿着splitting边界观察,则可以检测被重叠网格切割的对象。本文尝试检测并合并附近的边界框。 这个问题是数据特定的,如果我们试图定位像人类这样的对象,情况往往在图像中高而不是宽。这可以根据检测到的对象类进行调整。根据经验,我们设置了几个距离阈值,在这些阈值下我们可以合并相同对象类的附近边界框。 对于人体检测,我们考虑合并仅垂直相邻的区域。
3.2.3 Implementation of the client-server version
本文提出的attention pipeline 的动机是使4K视频的实时评估。针对以下两个特定属性来实现快速处理。
第一点是image crop 评估是一个并行问题
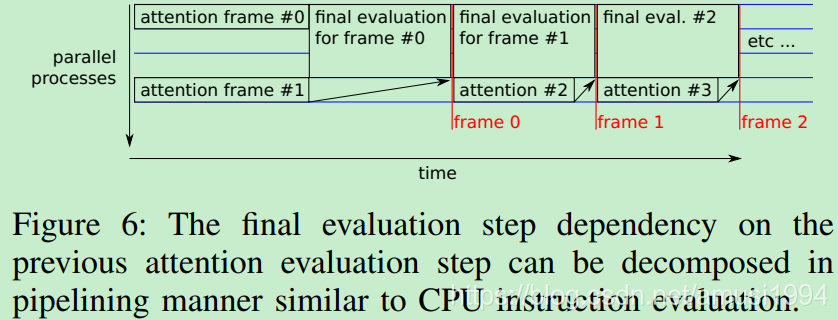
第二个是final评估总是取决于先前的attention评估步骤。其实绕过这种依赖性,在当前帧的最终评估的同时计算下一帧的评估步骤,这样有效地减少了每个注意力评估步骤的等待时间,见图6。
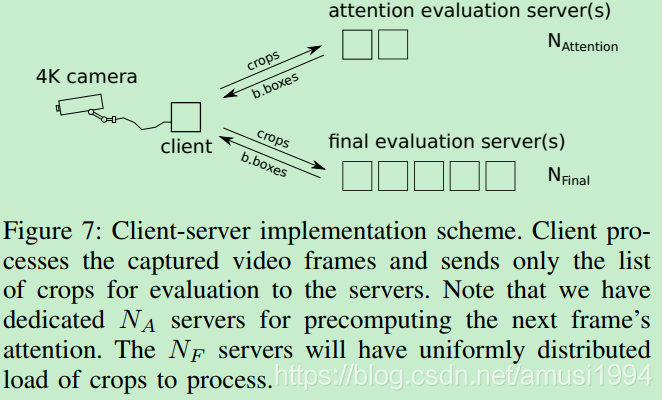
为了利用这些属性,我们使用了客户端 - 服务器实现,如图7所示。请注意,对于客户端机器,我们还可以将输入/输出操作和图像处理移动到多个线程中,从而进一步加快每帧性能。
四、实验结果
运行环境:在PSC’s Bridges cluster上运行,每个node的配置是 2 Intel Broadwell E5-2683 v4 CPUs running at 2.1 to
3.0 GHz and 2 NVIDIA Tesla P100 Pascal GPUs。
数据集:PEViD-UHD
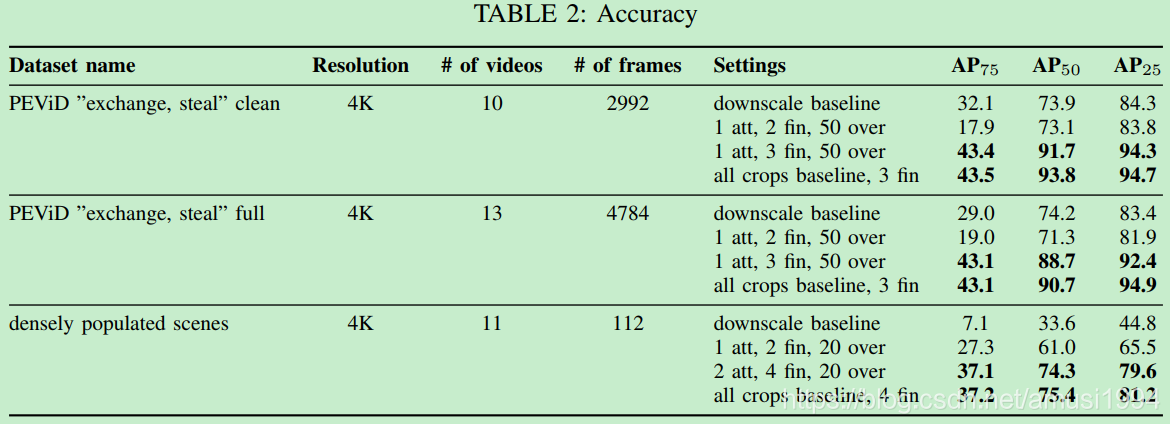
准确率度量:IoU 0.5、IoU 0.25和IoU 0.75下的平均准确率,即AP50、AP25和AP75。
Crop 设置:Crop设置受将原图划分成多少行的影响。论文尽可能的用最小的方向crop数量来覆盖整幅图像。然后每个方形都被缩放到608*608。表1显示了根据网格数量得到的网格分辨率,其中默认方形crop之间存在20像素的重叠。

准确率:
FPS:

五、结论与思考
5.1 作者结论
As a motivation of this paper we have stated two goals in processing high resolution data. First goal consists of the ability to detect even small details included in the 4K or 8K image and not loosing them due to downscaling. Secondly we wanted to achieve fast performance and save on the number of processed crops as compared with the baseline approach of processing every crop in each frame. Our results show that we outperform the individual baseline approaches, while allowing the user to set the desired trade-off between accuracy and performance.
5.2 记录该工作的亮点,以及可以改进的地方
- Attention trick
- 两次YOLOv2
- 按行数划分方形网格
参考
None