表的复杂查询
在实际应用中,常常需要执行复杂的数据统计,经常需要显示多张表的数据现在我们来学习比较复杂的select的语句。我们将继续使用scott用户下emp表作为示例。
聚合函数
MAX函数:
对一列取最大值
MIN函数:
对一列取最小值
AVG函数:
对一列取平均值
SUM函数:
对一列求和
COUNT 函数:
统计该列有多少行
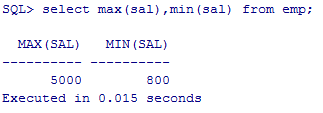
显示所有员工中的最高工资和最低工资
select max(sal),min(sal) from emp;
显示所有员工的平均工资和工资总和
select avg(sal) “平均工资”,sum(sal) “工资总和” from emp;

计算有多少员工
select count(ename) “员工总数” from emp;

显示工资最高的员工名字和工作岗位
select ename,job from emp where sal = (select max(sal) from emp);

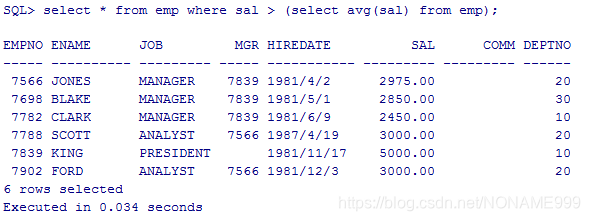
显示工资高于平均工资的员工信息
select * from emp where sal > (select avg(sal) from emp);
group by 和 having 子句
group by 用于对查询结果分组统计,
having 子句用于限制分组显示结果。
显示每个部门的平局工资和最高工资并按部门分组 按部门编号升序排列
select * from (select avg(sal) as “平均工资”,max(sal) as “最高工资”,deptno as “部门编号” from emp group by deptno) order by “部门编号”;

显示每个部门的平局工资和最高工资并按部门和工作岗位分组 按部门编号升序排列
select * from (select avg(sal) as “平均工资”,max(sal) as “最高工资”,deptno as “部门编号”,job as “工作岗位” from emp group by deptno,job) order by “部门编号”;

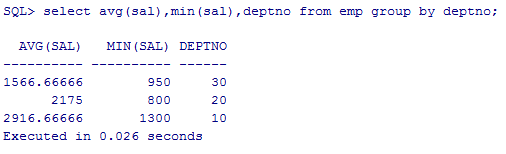
显示每个部门每种岗位的平均工资和最低工资
select avg(sal),min(sal),deptno from emp group by deptno;
显示平均工资低于2000的部门和它的平均工资
select avg(sal) ,deptno from emp group by deptno having avg(sal) <2000;

多表查询
多表查询是指两个或两个以上的表或视图的查询
笛卡尔集
笛卡尔集是指查询表的行数 乘与被查询表的列数(关联表外键的行数乘与主表的列数) 这样会产生一些不需要的数据 所以为了避免笛卡尔集,在多表查询的时候必须加上判断条件
多表查询的原则
是表的查询条件至少不能少于表的个数减一(查询表数-1)
--------------------------------------------------------
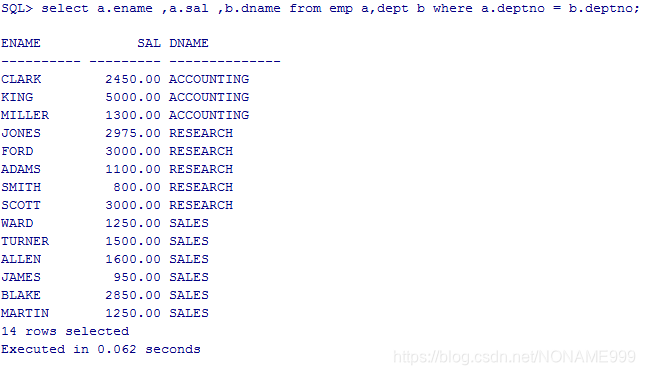
显示员工信息和员工工资以及所在部门的名字 这里我们用到两张表 emp 和dept。
select a.ename ,a.sal ,b.dname from emp a,dept b where a.deptno = b.deptno;
显示部门号为10的部门名,部门编号,员工名,和工资
select a.ename,a.sal,b.deptno,b.dname from emp a,dept b where a.deptno = b.deptno and a1.deptno= 10;

显示员工工资,员工姓名,和工资的级别(工资级别在工资级别表salgrade)
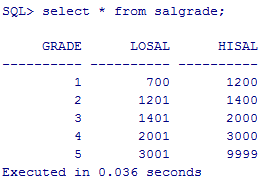
select a1.ename,a1.sal,a1.deptno,a2.grade from emp a1,salgrade a2 where a1.sal between a2.losal and a2.hisal;

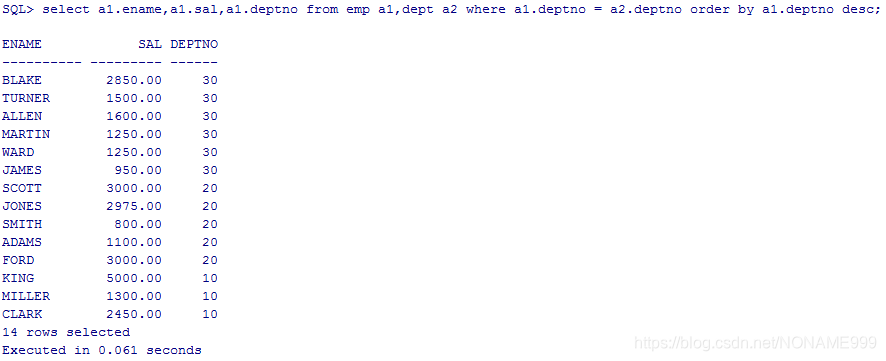
显示员工工资,员工姓名,所在部门的名字,按部门编号降序排列
select * from (select a1.ename,a1.sal,a1.deptno,a2.dname from emp a1,dept a2 where a1.deptno = a2.deptno ) order by deptno;
自连接
在EMP表中 找出每个员工的上级
我们先看一下EMP表,里面每个员工都有上级编号(MGR),同时每个员工的上级也在EMP表中,那我们现在结合之前多表查询的知识,把EMP看成两张表,一张老板表,一张员工表,根据员工表中员工上级的编号 匹配老板表中老板的员工编号(EMPNO)
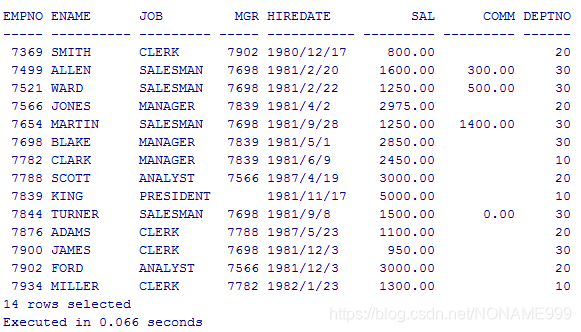
select worker.ename,boss.ename from emp worker,emp boss where worker.mgr = boss.empno;

同理 找出员工姓名为ford 的上级
select worker.ename,boss.ename from emp worker,emp boss where worker.mgr = boss.empno and worker.ename = ‘FORD’;

子查询
子查询也叫 嵌套查询 ,有多个select语句出现在一个SQL语句中 就称为子查询;
单行子查询
只显示一行数据的查询,叫单行子查询
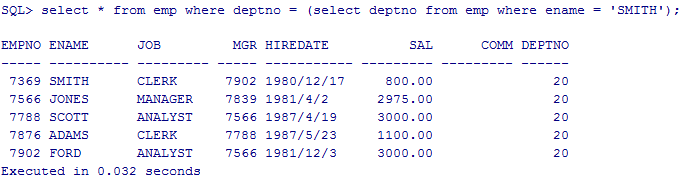
查询和SMINTH同一部门的所有员工信息
先找出SMINTH的部门编号
select deptno from emp where ename = ‘SMITH’;
然后再从emp表中选择部门编号和SMITH相同的进行匹配
select * from emp where deptno = (select deptno from emp where ename = ‘SMITH’);
多行子查询
返回多行数据 的子查询
查询部门号为10的岗位(JOB),相同的员工的 岗位(JOB)和员工的相关信息
我们先查出部门号为10号的岗位(JOB),这里返回了多个内容,10部门下有三种岗位,这里如果我们再去匹配的话,就不可以用“= ”操作符了 这要用到一个操作符 “ in” ,这里 “in” 的意思可以理解为 匹配该字段包含的多个内容
select job from emp where depton = 10;
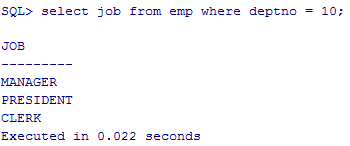
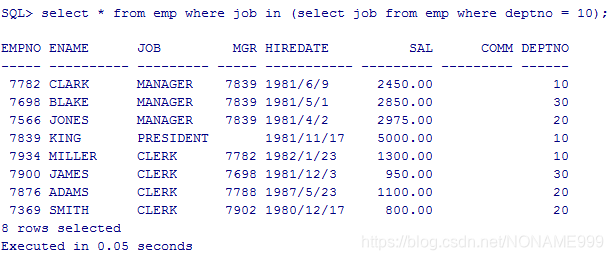
select * from emp where job in (select job from emp where deptno = 10);
在多行子查询中使用all操作符
all用来比较该字段包含的所有内容(所有条件同时满足)
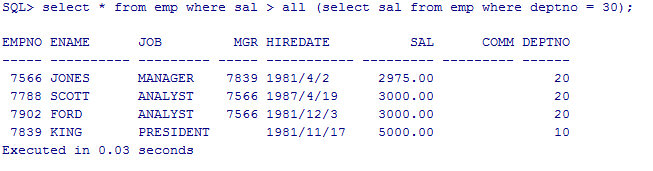
显示工资比部门30号的所有员工工资高的员工信息,同样先查出部门30号的员工工资,因为是要和30号部门的所有员工的工资进行比较
select sal from emp where dept = 30;

使用all来显示工资比部门30号的所有员工工资高的员工信息
select * from emp where sal > all (select sal from emp where deptno = 30);
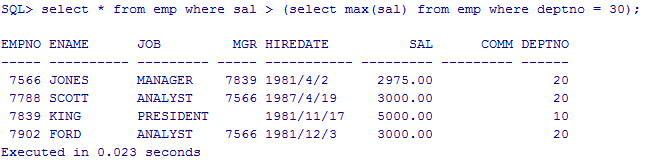
使用聚合函数MAX显示工资比部门30号的所有员工工资高的员工信息
select * from emp where sal > (select max(sal) from emp where deptno = 30);
多行子查询中使用any操作符
any用来比较该字段包含的任意内容(满足任意条件)
显示工资比部门30号任意员工工资高的员工信息
select * from emp where sal > any(select sal from emp where deptno = 30);
用聚合函数min来显示工资比部门30号任意员工工资高的员工信息
select * from emp where sal > (select min(sal) from emp where deptno = 30);

多列子查询
查询和SMITH部门编号和岗位相同的员工信息
注意!查询的列的顺序,必须与子查询中列的顺序相同
select * from emp where (deptno,job) = (select deptno,job from emp where ename = ‘SMITH’);

在FROM语句中使用子查询
在FROM语句中使用子查询 子查询必须指定 别名(给子查询指定别名不用加as)
显示自己的工资高于部门平均工资的员工信息
我们先查询出所有部门的平均工资
select deptno,avg(sal) sal1 from emp group by deptno;
把上面的查询看成一张子表,然后在使用多表查询,匹配和emp表中相关的信息
select a.ename,a.sal,a.deptno,b.mysal from emp a,(select avg(sal) mysal,deptno from emp group by deptno) b where a.deptno = b.deptno and a.sal > b.mysal order by a.deptno;
