以下是 《长短期记忆(LSTM)系列_LSTM的数据准备》 专题的概况图
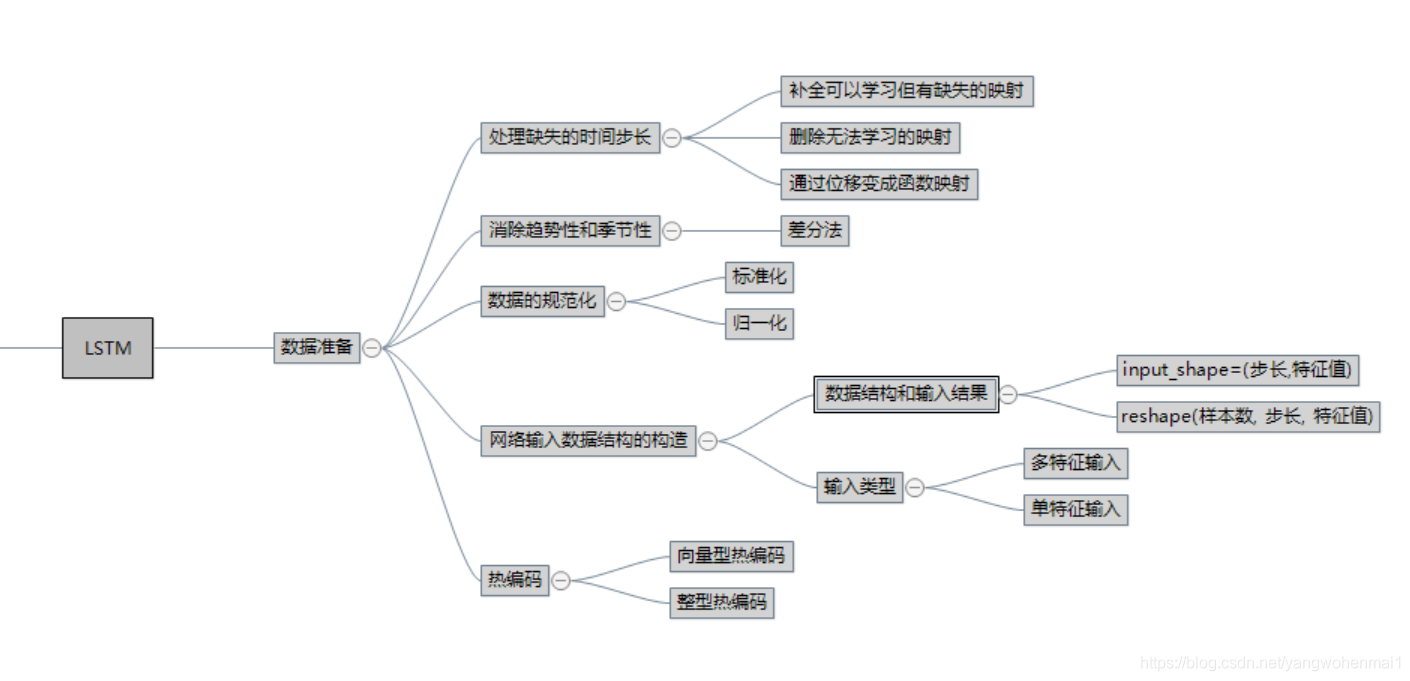
本专题包含6篇文章:
长短期记忆(LSTM)系列_LSTM的数据准备(1)——如何重塑Keras中长短期内存网络的输入数据
长短期记忆(LSTM)系列_LSTM的数据准备(2)——如何编写OneHotEncoder(热编码)序列数据
长短期记忆(LSTM)系列_LSTM的数据准备(3)——如何使用差分法消除数据的趋势和季节性
长短期记忆(LSTM)系列_LSTM的数据准备(4)——如何归一化标准化长短期记忆网络的数据
长短期记忆(LSTM)系列_LSTM的数据准备(5)——如何配置Keras中截断反向传播预测的输入序列步长
长短期记忆(LSTM)系列_LSTM的数据准备(6)——如何处理序列预测问题中的缺失时间步长(附两个完整LSTM实例)
前置课程为:
长短期记忆(LSTM)系列_1.1、回归神经网络在时间序列预测中的介绍和应用
长短期记忆(LSTM)系列_2.1~2.3、用递归神经网络简要介绍序列预测模型
长短期记忆(LSTM)系列_3.1~3.3、第一个LSTM小例子:Keras中长短期记忆模型的5个核心步骤(python)
下面一个是完整的LSTM实例,每一步的结果和说明都在注释中
阅读完本文基本可以对LSTM有一个清晰的理解
同时自己能写出一个最简单完整的LSTM程序
这里《LSTM的数据准备》这个专题到此就结束了,我们准备下一个专题的学习《使用LSTM建模》
from pandas import DataFrame
from pandas import concat
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
# 创建一个0.1~0.9的序列[0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]
length = 10
sequence = [i/float(length) for i in range(length)]
print(sequence)
# 构建一个X->y的映射关系
"""DataFrame方法可以把一个数组序列转换成一个有序编码的矩阵序列
0
0 0.0
1 0.1
2 0.2
3 0.3
4 0.4
5 0.5
6 0.6
7 0.7
8 0.8
9 0.9
"""
df = DataFrame(sequence)
print(df)
"""concat是一个链接方法,把多个数据拼接起来,axis=1就相当于把数据按照行对应拼接起来
DataFrame.shift是一个位移函数,df.shift(1)就相当于将df序列向下整体移动一位,第一位用NAN值补上。
0 0
0 NaN 0.0
1 0.0 0.1
2 0.1 0.2
3 0.2 0.3
4 0.3 0.4
5 0.4 0.5
6 0.5 0.6
7 0.6 0.7
8 0.7 0.8
9 0.8 0.9
"""
df = concat([df.shift(1), df], axis=1)
print(df)
"""删除数据中为NAN的数据
0 0
1 0.0 0.1
2 0.1 0.2
3 0.2 0.3
4 0.3 0.4
5 0.4 0.5
6 0.5 0.6
7 0.6 0.7
8 0.7 0.8
9 0.8 0.9
"""
df.dropna(inplace=True)
print(df)
# 使用reshape方法,把序列转换为LSTM可识别的数组格式
"""将df这个矩阵序列中的有用值提取出来,变成一个二维的数组数据
[[0. 0.1]
[0.1 0.2]
[0.2 0.3]
[0.3 0.4]
[0.4 0.5]
[0.5 0.6]
[0.6 0.7]
[0.7 0.8]
[0.8 0.9]]
"""
values = df.values
print(values)
"""values[:, 0]是将数组中第0列的所有行提取,赋值给X,values[:, 1]则是获取第1列
[0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8]
(9,)
"""
X, y = values[:, 0], values[:, 1]
print(X)
print(X.shape)
"""pandas.reshape将一个一维数组转换成一个三维的数据类型,神经网络的输入数据都是三维的
[[[0. ]]
[[0.1]]
[[0.2]]
[[0.3]]
[[0.4]]
[[0.5]]
[[0.6]]
[[0.7]]
[[0.8]]]
(9, 1, 1)
(9, 1, 1)代表9个样本,每个样本步长为1,并且有1个特征值
"""
X = X.reshape(len(X), 1, 1)
print(X.shape)
print(X)
# 1. 定义网络类型,Sequential是一个参数容器
model = Sequential()
# 由存储器单元组成的LSTM循环层称为LSTM(),input_shape(步长,特征值),可以指定input_shape参数,该参数需要包含时间步长和特征值的元组
model.add(LSTM(10, input_shape=(1,1)))
# 通常跟随LSTM层并用于输出预测的完全连接层称为Dense()。
model.add(Dense(1))
# 2. 编译网络,设置损失参数
model.compile(optimizer='adam', loss='mean_squared_error')
# 3. 调用网络开始训练模型
history = model.fit(X, y, epochs=1000, batch_size=len(X), verbose=0)
# 4. 评估网络
loss = model.evaluate(X, y, verbose=0)
print(loss)
# 5. 利用训练好的模型,带入原始的X进行单步预测
predictions = model.predict(X, verbose=0)
print(predictions[:, 0])
# 创建一个0.1~0.9的序列
length = 10
sequence = [(i+5)/float(length) for i in range(length)]
print(sequence)
# 构建一个X->y的映射关系
df = DataFrame(sequence)
df = concat([df.shift(1), df], axis=1)
df.dropna(inplace=True)
# 使用reshape方法,把序列转换为LSTM可识别的数组格式
values = df.values
X, y = values[:, 0], values[:, 1]
X = X.reshape(len(X), 1, 1)
predictions = model.predict(X, verbose=0)
print(predictions[:, 0])