所谓关联,就在从前面请求的响应中提取数据,给后面的请求使用。而提取数据,则需要用到后置处理器里的正则表达式提取器。为了演示,我简单写了一个java请求,模拟接口的响应数据

响应的数据为一个json,这是模拟接口查询会员列表的数据。time是查询数据花费的时间,count是查询出了多少条数据,memberList就是用户的列表信息,是个数组,数组的一个元素,就是一条用户的信息,包括用户的id、name、phone、status信息。在页面显示用户列表信息,都会做分页,所以只显示了10条用户的信息。这些数据,在浏览器中被js一解析,就可能是一个表格。
现在我们把这个java请求,当作是服务器的接口,调用后获取了响应数据,现在需要获取用户“张三”的id,给后面的接口做参数用,应该怎么做?这个时候就需要用后置处理器的正则表达式提取器了


引用名称,可以理解为就是一个变量,用来保存提取出来的内容。正则表达式,就是提取内容的表达式,其中“(.*)”是一个捕获组,会把 "id": 和 ,"name":"张三" 之间的内容捕获,然后赋值给“userId”。模板和匹配数字,先就这样写,这个在下面再讲,缺省值,就是没有提取到值的时候,那么就会把缺省值赋值给 userId,现在这个用处不大,在后面讲流程控制里的判断语句的时候,会需要使用默认值。
那到底会提取什么出来呢,这个时候可以使用前面讲的java请求,把这个userId的实际值响应出来。

保存脚本,运行,看结果


可以看到,这样就把用户 张三 的id提取出来了。当然,正则表达式里面,也可以使用变量。在测试计划中声明一个全局变量name,值是 张三。

正则表达式中使用该变量
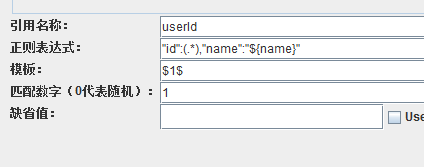
保存脚本,运行,可以看到结果是一样的。现在,如果要提取用户 李四 的id呢,改正则表达式

保存,运行,看结果

可以看到,提取的结果,就不是我们想要的啦,那个name乱码是因为没有加GBK编码,在代码里加上GBK编码再重新打jar包就可以解决。正则表达式匹配,是从字符串的第一个字符开始匹配,我们的正则表达式为:"id":(.*),"name":"李四",那么就会从响应里的第一个字符开始找,先找 "id": 这个字符串,结果在张三的信息里找到了,那么就会把这个作为开始标记,然后再往后找结束标记,也就是 ,"name":"李四",找到后,就会把开始标记和结束标记之间的字符串捕获,赋值给userId,这样就出现了上面的结果了。可我们要的是李四的id啊,要怎么弄?可以这样做,改正则表达式提取器
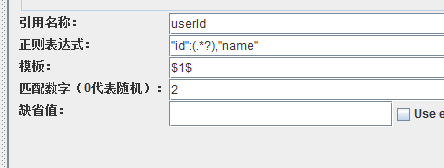
保存,运行之后,可以看到结果就是2。为什么呢?这里,就涉及到一个概念:贪婪匹配和非贪婪匹配。捕获字符串,需要给一个开始标记和结束标记,或者叫左边界和右边界吧。那么正则引擎就会先找开始标记,找到了就会保存下来,然后再往后找结束标记,找到了之后,如果是非贪婪模式,那么匹配结束,把开始和结束标记之间的字符串返回。如果是贪婪模式的话,找到结束标记之后,还会继续往后找,看后面是否还有结束标记,如果后面还有结束标记,就是把前面找到的结束标记丢掉,改用后面的结束标记,然后再往后找。。。一直找到字符串的末尾。贪婪和非贪婪在写法上的区别就是在括号中是不是以?结束。像之前写的括号中都没有?,就是贪婪模式,现在在括号里的后面加上?就变成非贪婪模式了。我们现在的正则表达式为: "id":(.*?),"name",所以就先找开始标记 "id":,找到之后,再找结束标记 ,"name",找到之后,就立马把两者之间字符串返回,这就完成了一次查找(捕获)。非贪婪模式和贪婪模式不一样,贪婪模式只会查找一次,因为它是贪婪模式,找到的结果也只会有一条,而非贪婪模式,找出的结果,就可能会是多条。所以还会有第二次查找。第二次查找就从第一次查找的结束标记之后开始查找,不过查找的是开始标记,找到之后,再找结束标记,如果找到,再把两者之间的字符串返回,第二次查找完成。然后第三次、第四次。。。一直到字符串的结束位置。所以上面的正则表达式,实际上就是会把所有用户的id捕获,然后通过匹配数字来获取对应的数据,如果要第1个用户的id,匹配数字就是1。如果要第7个用户的id,匹配数字就是7。所以匹配数字在贪婪模式下,只能取1,只有在非贪婪模式下,才可能有不为1的情况。
利用上面的方法,是提取出了 李四 的id,不难看出,还是有缺陷,因为要知道李四的信息在数组中的位置。如果不知道李四在数组中的位置,要怎么获取他的id呢?这个,暂时没有好的解决方案,后面学了流程控制,可以解决这个问题。
现在再看另一个问题:我要提取出id为1的用户的手机号,但是我并不知道他的name是什么。要怎么做?
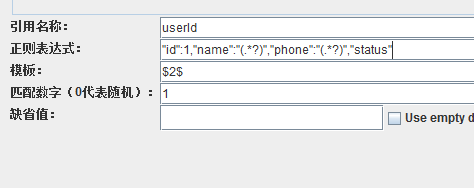
现在的正则表达式,有两个括号了,也就是有两个捕获组,准确地说是有三个捕获组,整个表达式是一个组。这个时候要取某个组里的内容,就要用到组的序号。整个表达式是一个组,组的序号是0,name后面的组序号是1,phone后面的组,序号是2,所以模板里写$2$,就是取第二个捕获组的内容的意思。运行之后,就可以看到第一个用户的手机号13512341234了。也可以这样写:

运行结果:

加上了GBK编码,中文就可以正常显示了。现在我想要id为1的用户的手机号的后四位,同样不知道用户的名字,怎么获取?
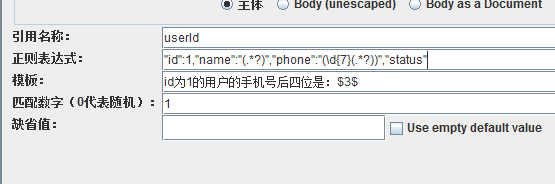
括号嵌套括号,组号,先算外层的,然后是里层的,所以phone后面的外层括号组号是2,里层的是3。我们想要的只是手机号的后四位,name或是phone的11位手机号,并不需要,捕获它们,是会消耗性能和占用内存的,所有,可以使用非捕获组,非捕获组,就是在括号内,以?:开头,所以可以这样写
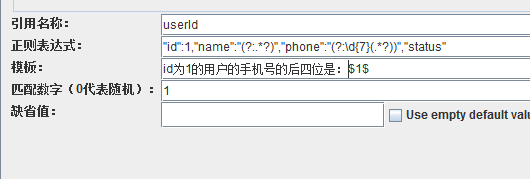
因为name后面的组,及phone后面的外层组,都使用了非捕获,所以phone后面的里层分组就成为了第1组,组号是1,模板里就要用 $1$ 来取分组里的内容。
前面讲的这些都是从响应的主体信息里提取数据,还可以从响应的请求头、URL等里面提取数据。正则表达式的写法是一样,只是在“要检查的响应字段”里选择不同的选项就可以了

然后最上面还有一个“Apple to”,这个是一个更大范围的从哪里提取。前面的三个,主要涉及到重定向。重定向就会有主请求和重定向的请求,重定向的请求这里面叫Sub-sample,也就是子请求了,这个的话,以后再演示吧。最后一个JMeter Variable,就是从一个变量中提取值。依旧用前面的模拟接口的java请求为例,比如要提取出李四的id,前面用非贪婪匹配实现了,这里也可以用另一种方式实现,不过也不是完美的方案。先在正则表达式里配置:

保存,运行,看结果:

这个时候,可以在第一个请求上再加一个正则表达式提取器


运行之后,结果

这里就要注意,两个正则表达式提取器的位置不能反了。更好的做法是,第二个正则表达式提取器写成:

这样,可以做到,不管李四在什么位置,都可以获取到他的id。id是纯数字,可以这样解决,如果是任意字符,就不能这样弄了。