梯度下降算法是优化神经网络最常见的方式,这里我们会接触梯度下降法的不同变种以及多种梯度下降优化算法。
梯度下降变种
- batch gradient descent
缺点:一次参数更新需要使用整个数据集,因此十分慢,并且内存不够的话很难应付。
优点:保证收敛到全局最小值或者局部最小值 - stochastic gradient descent
一次参数更新使用一个样本
优点:速度快。因为SGD的波动性,一方面,可以跳到更好的局部最小点。
缺点:参数更新方差大,从而目标函数波动严重,**另一方面,**很难收敛到最小值,但是我们可以逐渐减小学习率来应对。
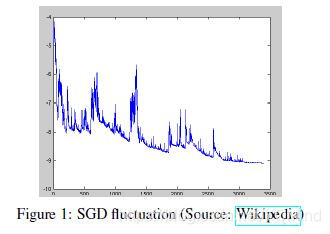
- mini-batch gradient descent
BGD和SGD的折中结合,减少了参数更新的方差,从而可以更稳定的收敛;可以利用矩阵优化
上面提到的有很多问题需要解决:
- 学习率的选择比较困难。太小的学习率使得收敛很慢,太大的学习率使得难以收敛。
- 对所有的参数更新使用同样的学习率。
- 鞍点。
- 预定义好的学习率方案太死板了,不灵活。
梯度下降优化算法
在深度学习中广泛使用的一阶方法。
Note:二阶方法,例如牛顿法,在高维数据上计算量太大,实际上不可行。
- Momentum
动量法是一种帮助SGD在相关方向上加速并且抑制摇摆的一种方法。动量法将历史步长的更新向量的一个分量增加到当前的更新向量中。
对于在梯度点处具有相同的方向的维度,其动量项增大,对于在梯度点处改变方向的维度,其动量项减小。因此,我们可以得到更快的收敛速度,同时可以减少摇摆。 - Nesterov加速梯度下降法(NAG)
我们希望有一个智能的球,这个球能够知道它将要去哪里。NAG能够给予动量项预知能力的方法。
通过计算关于参数未来的近似位置的梯度,而不是关于当前的参数的梯度
自适应学习率算法:Adagrad, Adadelta,RMSprop,Adam
3. Adagrad
Adagrad通过参数来调整合适的学习率
,对稀疏参数进行大幅度更新和对频繁参数进行小幅度更新。Adagrad为不同的参数设置不同的学习率。
因此,Adagrad非常适合处理稀疏数据。
例如,Pennington等人利用Adagrad训练Glove词向量,因为低频词比高频词需要更大的步长。
其中,
是到t时刻为止,关于
的梯度的平方和。有趣的是,没有平方根的操作,算法的效果会变得很差。
优点:无需手工调整学习率,大多数情况下,
缺点:学习率总是在降低以至于最终变得很小,从而停止学习
4. Adadelta
它是Adagrad的一种延申方法,以解决Adagrad的学习率单调递减的问题。而且,无需设置默认的学习率。
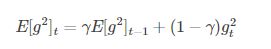
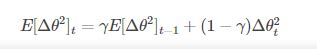
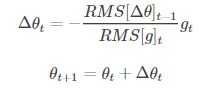
5. RMSprop
RMSprop是一个未被发表的自适应学习率的算法。RMSprop和Adadelta在相同的时间内被独立的提出,都源于对Adagrad的学习率单调递减的问题的求解。
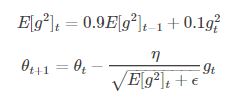
Hinton建议将
设置为0.9,
6. Adam
Adam是另一种自适应学习率的算法。除了像Adadelta和RMSprop一样存储一个指数衰减的历史平方梯度的平均值,还保存一个历史梯度的指数衰减平均值
在实际应用中,Adam效果很好,与其他自适应学习率算法相比,其收敛速度更快,学习效果更有效,而且可以纠正其他优化技术中存在的问题,如:学习率消失,收敛过慢或是高方差的参数更新导致损失函数波动较大等问题。
总结:
自适应学习率算法能很快收敛,并快速找到参数更新中正确的目标方向;SGD,NAG和动量法收敛缓慢,且很难找到正确的方向。
[1] https://blog.csdn.net/google19890102/article/details/69942970
[2] https://zhuanlan.zhihu.com/p/27449596
[3] 学习率退火
https://blog.csdn.net/lanmengyiyu/article/details/79341487?utm_source=blogxgwz4