TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与信息探勘的常用加权技术。
TF的意思是词频(Term - frequency), IDF的意思是逆向文件频率(inverse Document frequency)。
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF-IDF加权的各种形式常被搜寻引擎应用,作为文件与用户查询之间相关程度的度量或评级。
一个词在文章中出现很多次,那么这个词肯定有着很大的作用,但是我们自己实践的话,肯定会看到你统计出来的TF 大都是一些这样的词:‘的’,‘是’这样的词,这样的词显然对我们的分析和统计没有什么帮助,反而有的时候会干扰我们的统计,
一般我们会使用停用词的方式将这些没有含义的字过滤掉(网上可以搜索停用词的语料)。
算法公式介绍:
TF(词频):

IDF(逆文档频率):
此项计算需要相关意境的文档(例如:医疗类, 需多篇医疗相关的文档,从而有相关的侧重点)
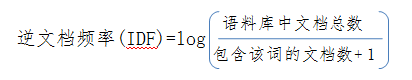
注:此位置 +1 的目的是防止分母为0
TF-IDF 计算:
tf-idf = TF(词频) * IDF(逆文档频率)
代码实现:
IDF生成:


1 # -*- coding: utf-8 -*- 2 # @Time : 2018/12/5 17:34 3 # @Author : Richer 4 # @File : get_idf.py 5 # 此文件用于自动计算idf 6 7 import jieba 8 import os,sys 9 import math 10 11 class IDF(): 12 13 def __init__(self): 14 self.base_path = os.getcwd() 15 self.idf_input_path = os.path.join(self.base_path + '/train_data/tf_idf_input/') # 存放制作idf文档存放的文件夹 16 self.stop_word_file = os.path.join(self.base_path + '/train_data/stop_words.txt') # 停用词 17 self.idf_output_path = os.path.join(self.base_path + '/data/idf_out/') 18 19 def idf(self): 20 all_chars_dict, total = self._get_file() 21 with open(self.idf_output_path + 'idf.txt', 'w', encoding='utf-8') as wf: 22 for char,value in all_chars_dict.items(): 23 if char > u'\u4e00' and char <= u'\u9fa5': 24 p = math.log(total / (value + 1)) 25 wf.write(char + ' ' + str(p) + '\n') 26 27 def _get_file(self): 28 idf_input_list = os.listdir(self.idf_input_path) 29 all_dict = {} 30 total = 0 31 for file_name in idf_input_list: 32 file = os.path.join(self.idf_input_path, file_name) 33 words = self._read_file(file) # 读取每一个文件的信息 34 tmp_dict = {char: 1 for char in words} 35 total =+1 36 for tmp_char in tmp_dict: 37 num = all_dict.get(tmp_char, 0) 38 all_dict[tmp_char] = num + 1 39 return all_dict, total 40 41 def _read_file(self, file): 42 stop_words = self._stop_words() 43 file = open(file, 'r', encoding='utf-8',errors='ignore') .read() 44 content = file.replace("\n","").replace("\u3000","").replace("\u00A0","").replace(" ","") 45 content_chars = jieba.cut(content, cut_all= True) 46 words = list(set([char for char in content_chars if char not in stop_words])) 47 return words 48 49 def _stop_words(self): 50 stop_words = [] 51 with open(self.stop_word_file, 'r') as f: 52 words = f.readlines() 53 for word in words: 54 word = word.replace("\n","").strip() 55 stop_words.append(word) 56 return stop_words
TF计算及TF-IDF计算:
1 # -*- coding: utf-8 -*- 2 # @Time : 2018/12/8 15:08 3 # @Author : Richer 4 # @File : tfidf.py 5 # 此文件是tfidf算法入口 6 7 import os, sys 8 import jieba 9 import re 10 from collections import Counter 11 12 13 class TFIDF(): 14 def __init__(self, file, topK=20): 15 self.base_path = os.getcwd() 16 self.file_path = os.path.join(self.base_path, file) # 需提取关键词的文件, 默认在根目录下 17 self.stop_word_file = os.path.join(self.base_path + '/train_data/stop_words.txt') # 停用词 18 self.idf_file = os.path.join(self.base_path + '/data/idf_out/idf.txt') # idf文件 19 self.idf_freq = {} 20 self._load_idf() 21 self.topK = topK 22 23 def key_abstract(self): 24 # 获取处理后数据 25 data = self._fitter_data() 26 stop_words = self._get_stop_words() 27 data = [char for char in data if char not in stop_words] 28 total_count = data.__len__() 29 list = Counter(data).most_common() 30 keywords = {} 31 for chars in list: 32 char_tmp = {} 33 char_tmp[chars[0]] = (chars[1] / total_count) * self.idf_freq.get(chars[0], 34 self.mean_idf) # TF * IDF(IDF不存在就取平均值)值 35 keywords.update(char_tmp) 36 tags = sorted(keywords.items(), key=lambda x: x[1], reverse=True) 37 if self.topK: 38 return [tag[0] for tag in tags[:self.topK]] 39 else: 40 return [tag[0] for tag in tags] 41 42 def _fitter_data(self): 43 string = open(self.file_path, 'r', encoding='utf-8').read() 44 content = string.replace("\n", "").replace(" ", "").replace("\u3000", "").replace("\u00A0", "") 45 content = " ".join(jieba.cut(content, cut_all=False)) 46 return re.sub('[a-zA-Z0-9.。::,,))((!!??”“\"]', '', content).split() # 此位置说白了就是只留下中文; 还可以使用遍历的方法判断词是否在 char > u'\u4e00' and char <= u'\u9fa5': 47 48 def _load_idf(self): # 从文件中载入idf 49 cnt = 0 50 with open(self.idf_file, 'r', encoding='utf-8') as f: 51 for line in f: 52 try: 53 word, freq = line.strip().split(' ') 54 cnt += 1 55 except Exception as e: 56 pass 57 self.idf_freq[word] = float(freq) 58 print('Vocabularies loaded: %d' % cnt) 59 self.mean_idf = sum(self.idf_freq.values()) / cnt 60 61 def _get_stop_words(self): 62 stop_words = [] 63 with open(self.stop_word_file, 'r') as f: 64 words = f.readlines() 65 for word in words: 66 word = word.replace("\n", "").strip() 67 stop_words.append(word) 68 return stop_words
个人github项目:https://github.com/RicherDong/Keywords-Abstract-TFIDF-TextRank4ZH