版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/pku_langzi/article/details/81174347
这篇文章是比利时鲁汶大学的一篇文章,它提出了一个新的任务:
输入结构化的文本(主语,关系,宾语),来预测两个物体之间的空间位置关系。
对于spatial template可以划分:
explicit类型:比如on, below等直接的空间关系。
implicit类型:比如(man, pulling, kite) , (man, pulling, luggage)等,本文主要处理的是这种类型。
文章的方法比较直接:两种模型(基于回归和基于像素),深度网络对位置进行约束训练。

评价指标:(1)IOU (2)Regression (3)Above/below classification (4)Pixel (macro) accuracy
数据集:Vgnome筛选合适的样例,最终∼378K instances,2,183 unique implicit Relationships and 5,614 unique objects
(i.e., Subjects and Objects).
数据集样例:
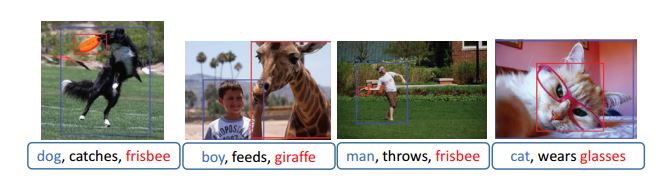
一些可视化的例子:

原文链接:Acquiring Common Sense Spatial Knowledge through Implicit Spatial Templates