Hive是基于Hadoop的数据仓库解决方案。由于Hadoop本身在数据存储和计算方面有很好的可扩展性和高容错性,因此使用Hive构建的数据仓库也秉承了这些特性。
这是来自官方的解释。
简单来说,Hive就是在Hadoop上架了一层SQL接口,可以将SQL翻译成MapReduce去Hadoop上执行,这样就使得数据开发和分析人员很方便的使用SQL来完成海量数据的统计和分析,而不必使用编程语言开发MapReduce那么麻烦。
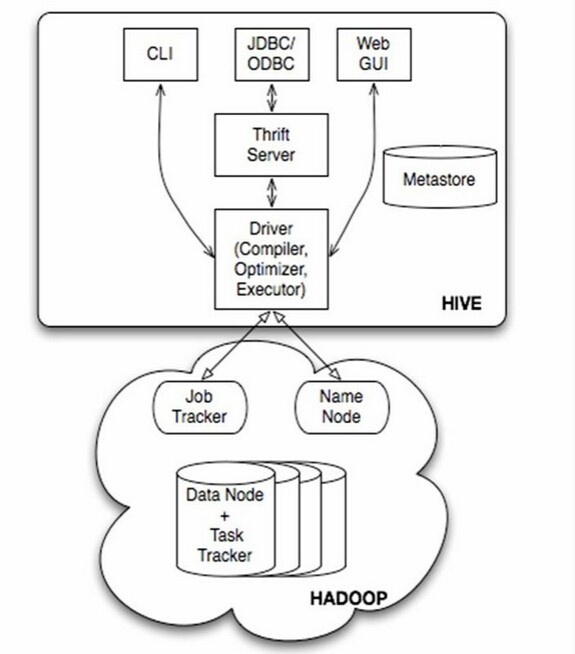
如图中所示,Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
在使用过程中,至需要将Hive看做是一个数据库就行,本身Hive也具备了数据库的很多特性和功能。
Hive可以使用HQL(Hive SQL)很方便的完成对海量数据的统计汇总,即席查询和分析,除了很多内置的函数,还支持开发人员使用其他编程语言和脚本语言来自定义函数。
但是,由于Hadoop本身是一个批处理,高延迟的计算框架,Hive使用Hadoop作为执行引擎,自然也就有了批处理,高延迟的特点,在数据量很小的时候,Hive执行也需要消耗较长时间来完成,这时候,就显示不出它与Oracle,Mysql等传统数据库的优势。
此外,Hive对事物的支持不够好,原因是HDFS本身就设计为一次写入,多次读取的分布式存储系统,因此,不能使用Hive来完成诸如DELETE、UPDATE等在线事务处理的需求。
因此,Hive擅长的是非实时的、离线的、对响应及时性要求不高的海量数据批量计算,即席查询,统计分析。
1. Hive在HDFS上的默认存储路径
Hive的数据都是存储在HDFS上的,默认有一个根目录,在hive-site.xml中,由参数hive.metastore.warehouse.dir指定。默认值为/user/hive/warehouse.
修改数据库属性:
ALTER (DATABASE|SCHEMA) database_name
SET DBPROPERTIES (property_name=property_value, …);
Hive的动态分区
Hive UDF开发
http://lxw1234.com/archives/2015/08/454.htm
Hive文件的导入和导出 load
1.时间日期函数
日期转换成时间戳: unix_timestamp('2017-09-15 14:23:00','yyyy-MM-dd HH:mm:ss')
时间戳转换成日期:from_unixtime(1505456567,'yyyy-MM-dd HH:mm:ss');
获取日期:to_date('2017-09-15 11:12:00')
日期中的年/月/日/时/分/秒/周:year(from_unixtime()),month(),day(),hour(),minute(),second()
2.模糊匹配
where ts like '%再见%'
3.字符串处理
字符串拼接
4.json解析
5.设置hive表的生命周期
hive -e"
create table if not exists test.xdw(
order_id string,
accid_time string,
state string,
accident_type_name string,
accident_reason_name string
)partitioned by (pt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE
TBLPROPERTIES('LEVEL'='1','TTL'='365');
"